
- 数据下载【第一次下载】
- 数据下载【数据更新】
- 数据分仓【主板指数,行业指数,个股指数】
- 数据维护:重新选择免费数据接口,增加数据新因子
- 数据调用
- 使用工具和库:Python,Navicat for MySQL,baostock等
未来将全部搬迁到云上去。
写代码主要要弄清楚:
1.自己的业务需求,这是一切的开始,请在书写代码的时候一定要想清楚才是。这是学习代码的目标,也是解决问题的开始。
2.多看文档,多看别人写的。
3.代码经过运行发现几个问题:
3.1一个是没有对函数进行封装,导致使用的效果比较差
3.2只是对于案例进行梳理和说明,没有考虑到实际情况,导致后面无法进行更新和维护,笔者都将进行修订和整改。
- 获取数据code【主板+指数、个股】
- 分仓管理
1.1获取个股数据,返回一个dataframe
import pandas as pd
import numpy as np
import baostock as bs
import matplotlib.pyplot as plt
import pymysql
from sqlalchemy import create_engine
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = 'SimHei'
lg = bs.login()
# 显示登陆返回信息
def stockcode_detail():#返回一个当前最新的dataframe,第一次调用即可,后面可以不用管
#调用baostock数据
rs = bs.query_stock_industry()
#打印数据并且合并
industry_list = []
while (rs.error_code == '0') & rs.next():
# 获取一条记录,将记录合并在一起
industry_list.append(rs.get_row_data())
#合并
result = pd.DataFrame(industry_list, columns=rs.fields)
#第一次采取to_sql即可,后面的都是进行更新,即便终止,只要不去读取就好了,抛出异常进行处理
return result
#调用该函数
#print(stockcode_detail().head())- 通过询问baostock客服得知,该指数的更新是以周为单位进行更新,所以平时可以少进行更新,调用的频率比较少。
- 必须要取到当前的dataframe,而不是之前说的list,也是便于后面的插入。
1.2返回的数据展示:
updateDate code code_name industry industryClassification
0 2021-01-18 sh.600000 浦发银行 银行 申万一级行业
1 2021-01-18 sh.600001 邯郸钢铁 申万一级行业
2 2021-01-18 sh.600002 齐鲁石化 申万一级行业
3 2021-01-18 sh.600003 ST东北高 申万一级行业
4 2021-01-18 sh.600004 白云机场 交通运输 申万一级行业
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4278 entries, 0 to 4277
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 updateDate 4278 non-null object
1 code 4278 non-null object
2 code_name 4278 non-null object
3 industry 4278 non-null object
4 industryClassification 4278 non-null object
dtypes: object(5)
memory usage: 83.6+ KB1.3数据库的展示:
#表的columns分别是:更新日期,股票代码,股票名字,所属行业,行业分类标准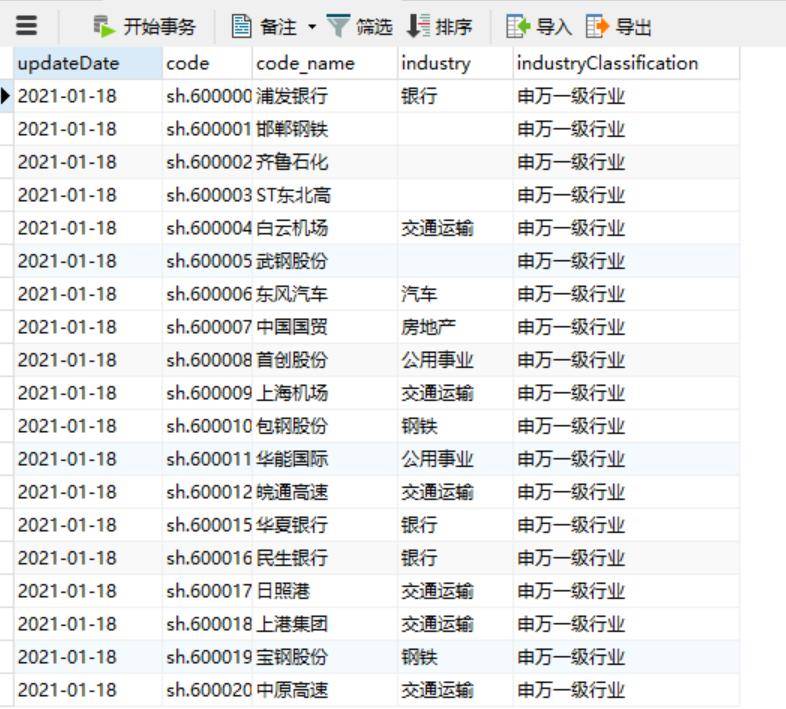
1.4在sql进行查询:
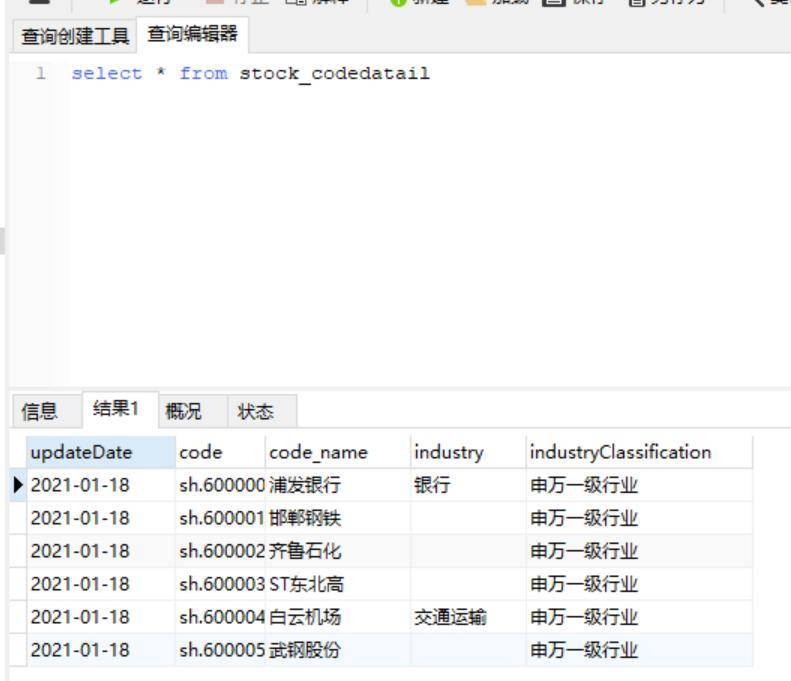
二、更新,维护:
#2.1用于与sql进行检查,经常需要更新的地方,指定数据库进行修改。#2.2其实我们还可以把df_pass= pd.read_sql('select * from stock_codedatail', conn)#中的stock_codedatail表格作为参数进行设置,但是这里只有一个表就不考虑。def update_data(database): #读取数据,属于旧数据 conn=pymysql.connect(host='localhost', port=3306, user='root', password='123456', db=database,charset='utf8') #获取游标卡尺 cursor=conn.cursor() df_pass= pd.read_sql('select * from stock_codedatail', conn) #再次调用: df_now=stockcode_detail() #形成两个列表,进行快速判断。 df_pass_list = df_pass['code'].tolist() df_now_list=df_now['code'].tolist() #在现在的列表里面找不存在于过去表的元素,然后插入 c_value= [x for x in df_now_list if x not in df_pass_list] df_c=df_now.loc[df_now['code'].isin(c_value)] #构建插入语句: #这里的stock_codedatail为表名(table_name),插入多少数据列,就写多少列名,对应的 #%s就有多少个。 query = """insert into stock_codedatail (updateDate, code, code_name,industry, industryClassification) values (%s,%s,%s,%s,%s)""" #条件判断,如果为真,则开始赋值插入 if len(c_value) > 0: for i in range(len(c_value)): #从df_new中取出新增的每一行,然后进行赋值给insert_data insert_data=df_c.iloc[i].tolist() #获取insert_data中的数据 updateDate=insert_data[0] code=insert_data[1] code_name=insert_data[2] industry=insert_data[3] industryClassification=insert_data[4] #构建query的values值,并对格式进行处理,强制转化 values=(str(updateDate),str(code),str(code_name),str(industry),str(industryClassification)) #获取数据并且插入 cursor.execute(query,values) # 关闭游标,提交,关闭数据库连接 # 如果没有这些关闭操作,执行后在数据库中查看不到数据 cursor.close() conn.commit() conn.close() # 不存在,则跳过 else: print('未更新')- df_pass_list = df_pass[‘code’].tolist()是将series转变为list,而dataframe则是采取df_pass_list = df_pass[‘code’].values.tolist()。pandas不同的数据结构转化为list是有一定的差别的。
- 我们为什么要通过将两列series进行list处理,就是为了减少代码的运行时间,在这里有一部分喜欢用for…in…循环方式去找寻,这样子大大增加了代码运行的时间,不利于未来整体的设计。
- c_value= [x for x in df_now_list if x not in df_pass_list],这里的意思是,x在新数据下但是不在旧数据下的代码。
- 运行效果如下:

- 这个是2021-2-1的数据展示(修改以后已经添加进去了),已经适合于实际情况的做法。之前一直在报错。
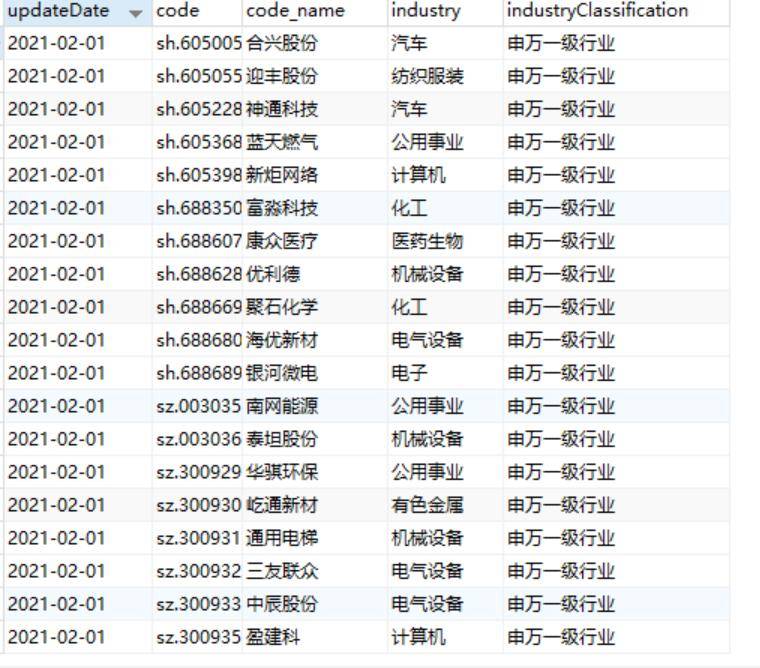
- 修改版本以后的插入思路有所不同,之前是去取dataframe的整行,但是无法更新,后来采取将dataframe每列进行循环,再tolist(),然后我们就能够得到一个list包含[‘updateDate’,’code”code_code’,’industry’,’industryClassification’],再通过访问list的位置进行取数,则大大提高了运算速度。
三、总结:
在这里笔者其实感觉这种设计思路和做数学题目是一样的,就是将复杂的问题简单化,然后通过简单的计算去得出结果,再反过来给复杂问题进行标记,取值,最终得到答案。这是笔者悟出来的编程思考,仅供参考。
最近笔者一直在设计一个简单的查询GUI框架,通过搭建以后也发现是这样子的问题,所以要多撸代码才是,多思考才是,消化才是最终是得出自己的东西。
最重要的是不要忘记自己设计的初心和最开始的目的才是,业务才是我们设计一切的起源和开端。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/496094
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





