
Pandas和SQL在数据转换和数据分析方面都应用广泛,但是对于完成同样的任务,pandas更简洁明了,这种表现的很重要的一个原因是:pandas不像SQL那样要受到数据库系统环境的诸多严格限制,而pandas则相对独立,提供的函数更多。写过 SQL程序的人大概都有过很痛苦的经历,针对复杂任务写SQL代码简直就是恶梦!相比之下,使用pandas操作和管理数据的体验很轻松。
本文将通过一些数据管理的任务示例,分别用pandas操作方法和SQL查询语句来实现,来演示pandas和SQL的代码写法之间的差别,这些任务用SQL实现起来都不是那么容易。特别注明,以下内容摘译自英文技术网页,记录在这里供日后参考;平台不允许在文中出现外部链接,如想了解更详细信息,可搜索ponder这个词。
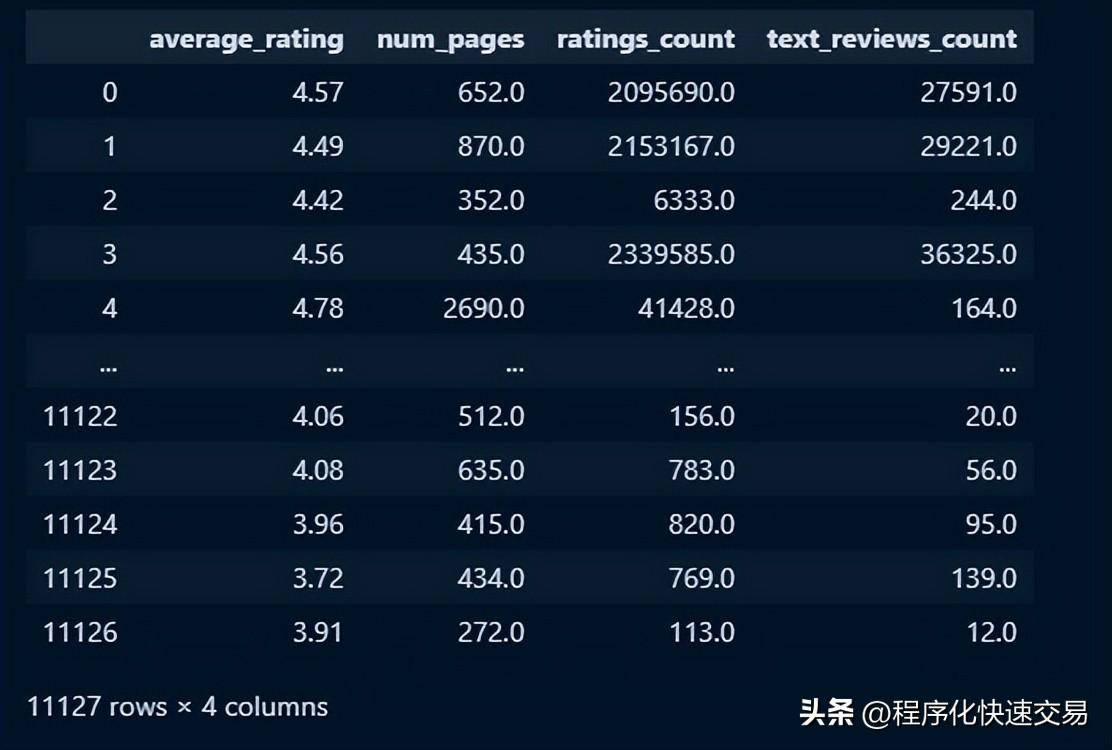
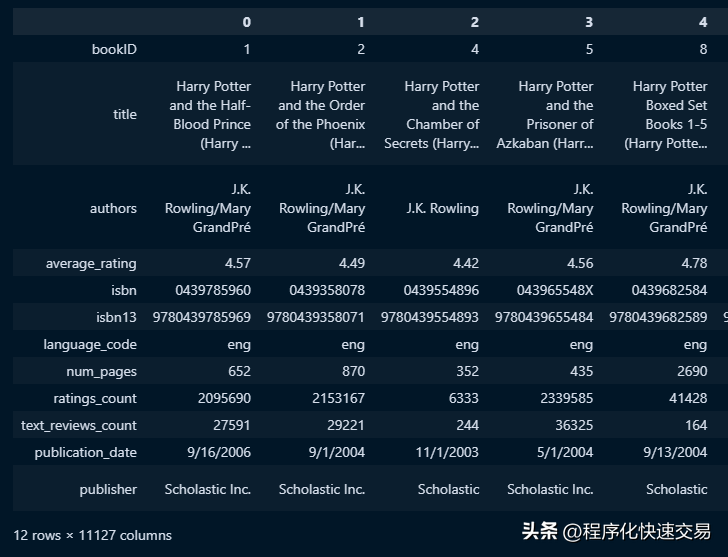
数据一个图书出版信息的文本文件,其中列内容如下:bookID,title,authors,average_rating,isbn,isbn13,language_code, num_pages,ratings_count,text_reviews_count,publication_date,publisher。
import pandas as pd
import numpy as np
df = pd.read_csv("books.csv", on_bad_lines='skip', dtype={'bookID': str, 'isbn': str, 'isbn13': str})
df部分内容:


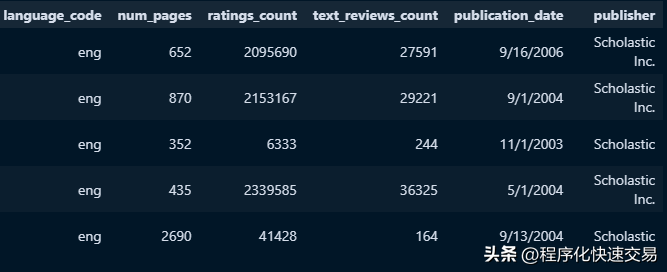
针对列做统一规范,即列的范式化
范式化是机器学习中特征工程的常见操作,如某列的数值的范围做刻度标识,以便确定数值在特定的范围内,又如数值分布的方差较小等。这样的数据操作要在机器学习模型训练之前完成,然后作为特征输入值,进而提高机器学习模型的准确性。数值范式化在pandas中很容易,而在数据库中用SQL则相对繁琐,示例代码如下:
pandas 代码:
x = df.select_dtypes(include='number').columns
(df[x] - df[x].mean())/df[x].std()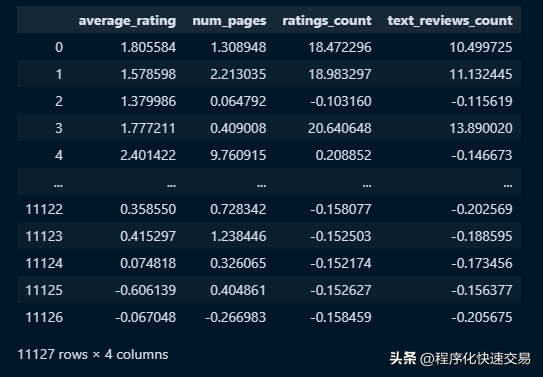
SQL 代码:
SELECT
(
(average_rating - AVG(average_rating) OVER ()) /
STDDEV_POP(average_rating) OVER ()
),
(
(num_pages - AVG(num_pages) OVER ()) /
STDDEV_POP(num_pages) OVER ()
),
(
(ratings_count - AVG(ratings_count) OVER ()) /
STDDEV_POP(ratings_count) OVER ()
),
(
(text_reviews_count - AVG(text_reviews_count) OVER ()) /
STDDEV_POP(text_reviews_count) OVER ()
),
FROM
Books以上SQL代码中,需要对每列单独进行操作,如果涉及的列比较多,那就要重复写很多查询语句;如果列有变化,那对应的sql语句也要修改。使用pandas,只需指定所有的数值列即可。
独热编码
很多机器学习工具包都涉及到把数值矩阵或布尔矩阵作为输入的用法,其中独热编码(one-hot encoding)就是常见的一种。本例中对 df 的 language_code 列做独热编码处理,
pandas 代码:
pd.get_dummies(df['language_code'])结果如下:
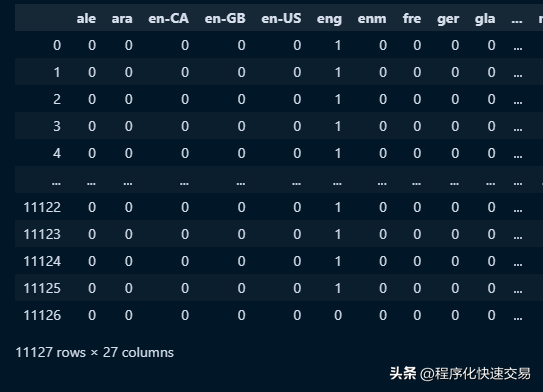
SQL 代码:
SELECT
IF(language_code = 'eng', 1, 0) as eng,
IF(language_code = 'en-US', 1, 0) as en_US,
IF(language_code = 'fre', 1, 0) as fre,
[... 还有 20 条类似的 IF 语句 ...]
IF(language_code = 'nor', 1, 0) as nor,
IF(language_code = 'tur', 1, 0) as tur,
IF(language_code = 'gla', 1, 0) as gla,
IF(language_code = 'ale', 1, 0) as ale
FROM
Books以上SQL 语句实现独热编码,比在pandas中实现就复杂很多,且在SQL语句之前,首先由找出 language_code 中不重复的值:
SELECT DISTINCT language_code FROM Books清理列中的缺失数值
如果列中有缺失值,如NULL 或NA, 首先要进行清理,这样的值对机器学习模型来说没有价值。假如要把缺失值超过1%的列丢弃,那么用pandas和SQL如何实现?示例代码如下:
pandas 代码:
df.loc[:, df.isnull().mean() < .01]
df.columns结果如下:

SQL 代码:
SELECT
(COUNT(CASE WHEN book_id IS NOT NULL THEN 1 END) /
CAST(COUNT(*) AS FLOAT) AS book_id_null_fraction,
(COUNT(CASE WHEN title IS NOT NULL THEN 1 END) /
CAST(COUNT(*) AS FLOAT) AS title_null_fraction,
[... 还有8个类似的语句 ...]
(COUNT(CASE WHEN publication_date IS NOT NULL THEN 1 END) /
CAST(COUNT(*) AS FLOAT) AS publication_date_null_fraction,
(COUNT(CASE WHEN publisher IS NOT NULL THEN 1 END) /
CAST(COUNT(*) AS FLOAT) AS publisher_null_fraction,
FROM Books用SQL实现就不是一句能实现的了,首先要得到每一列中由缺失数据的行,再判断这样的行数是否大于1%。
共轭计算
这涉及到共轭矩阵,一般在主成分分析中要计算出列与列之间数值的相关值,这是机器学习中特征选取必须要完成的任务,以便删除怪异的特征,有助于提高机器学习算法的效率。示例代码如下:
pandas 代码:
df.cov() * (len(df) - 1)输出结果:
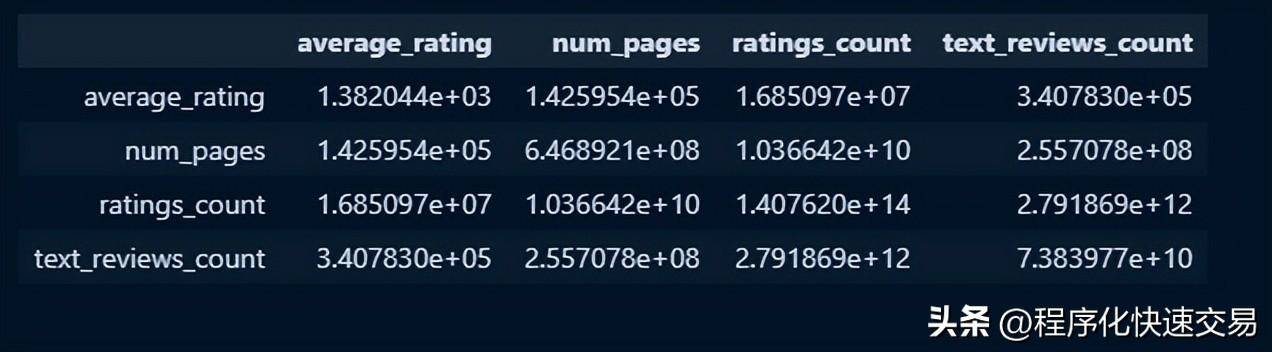
SQL 代码:
WITH t1 AS (
SELECT
text_reviews_count,
AVG(text_reviews_count) OVER() AS avg_text_reviews_count,
ratings_count,
AVG(ratings_count) OVER() AS avg_ratings_count,
num_pages,
AVG(num_pages) OVER() AS avg_num_pages,
average_rating,
AVG(average_rating) OVER() AS avg_average_rating
FROM Books
)
SELECT
SUM(
(text_reviews_count - avg_text_reviews_count) *
(ratings_count - avg_ratings_count)
) AS text_reviews_count_vs_ratings_count,
SUM(
(text_reviews_count - avg_text_reviews_count) *
(num_pages - avg_num_pages )
) AS text_reviews_count_vs_num_pages,
[... 省略的语句 ...]
SUM(
(ratings_count - avg_ratings_count) *
(average_rating - avg_average_rating)
) AS ratings_count_vs_average_rating,
SUM(
(num_pages - avg_num_pages) *
(average_rating - avg_average_rating)
) AS num_pages_vs_average_rating
FROM t1很长的一段SQL查询语句!
dataframe多列结合
假如把图书分成两类:畅销书goodreads和其他书otherreads,现在要求这两类书的加权平均值。在pandas中,可以选择所有的数值列作为上述两个dataframe的列,写很短的代码就可以轻松的算出来 ,代码如下:
pandas 代码:
otherreads_df = df.copy()
goodreads_numerical = df.select_dtypes(include='number')
otherreads_numerical = otherreads_df.select_dtypes(include='number')
.8 * goodreads_numerical + .2 * otherreads_numerical结果如下:
SQL 代码:
SELECT
.8 * Goodreads.average_rating + .2 * Otherreads.average_rating AS average_rating,
.8 * Goodreads.num_pages + .2 * Otherreads.num_pages AS num_pages,
.8 * Goodreads.ratings_count + .2 * Otherreads.ratings_count AS ratings_count,
.8 * Goodreads.text_reviews_count + .2 * Otherreads.text_reviews_count as text_reviews_count
FROM
Goodreads
LEFT JOIN
Otherreads
ON
Goodreads.bookID = Otherreads.bookID用SQL代码就要复杂多了!首先要求出每个数值列的均值,这就要把非数值列分离出去。pandas中可以按照行编号合并,但在SqL中没有行编号的概念,就要临时加一个类似BookID的列,字段越多查询语句越长。
行列转置
行列转置是线性代数中常见的操作,在清理数据中也经常会用到,看看使用pandas 和SQL 如何实现?代码如下:
pandas 代码:
df.T语句简单地不能再简单了!结果如下:
如果在df 中有方向相反的数据,该命令会自动修正。
使用SQL 不可能完成这一任务,SQL 根本就不可能支持这种操作!
用代码针对列名称进行数据操作
通常数据集有许多列,针对相似的列名称,获得数据子集,使用pandas可以轻易的实现,而SQL不支持这样的操作。pandas 代码如下:
df.filter(regex='isbn')结果如下:
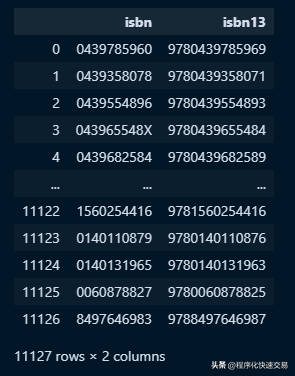
对于数据库系统而言,选择模糊匹配的多个字段需要数据表策略的支持,SQL查询实现起来难度很大!
更新单项数据
有时候数据集中有错误或异常,就会打破数据处理的步骤,因此需要做相应的处理。假定在books 数据集中发现 average_rating的第一行是错误的,就需要更正,在pandas 中可以使用以下代码:
df.iloc[0, df.columns.get_loc('average_rating')] = 4.0这在pandas中操作起来很容易,就像操作Excel电子表格,但是对于数据库系统中的books数据表则不支持这样的操作,只能修改文本数据,因为sql查询不能基于列顺序进行操作。
数据透视与格式转换(pivot 和 melt)
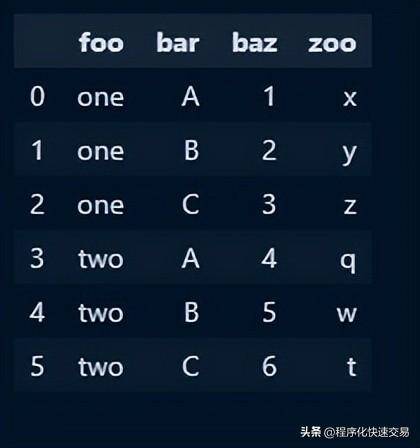
重构dataframe,基于指定的索引和列生成新的 dataframe,这和Excel中的相关操作类似。看下面的例子:
pandas 代码:
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two','two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
df示例数据如下图所示:
df.pivot(index='foo', columns='bar', values='baz')结果如下图:
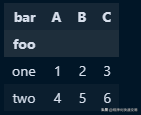
SQL 代码:
SELECT
foo,
MIN(CASE WHEN bar = "A" THEN baz END) AS A,
MIN(CASE WHEN bar = "B" THEN baz END) as B,
MIN(CASE WHEN bar = "C" THEN baz END) as C
FROM
Data
GROUP BY foo用SQL 实现同样的数据透视,需要针对每一列的bar数据写select语句,字段少也还可以,字段多就很繁琐了!
时间序列的移动均值
假定一个数据表的每一列是某一天网站访问者的数量,即买某种商品的人数,构建数据集的python代码如下:
import numpy as np
visits = pd.DataFrame(np.random.randint(0, 1000, size=(2, 365)),
columns=pd.date_range(start='1/1/2018', end='12/31/2018'),
index=['visits', 'purchases'])
visits = visits.rename_axis('date', axis='columns')
visits结果如下图:

现在假设计算每周的平均人数,在pandas中就要用到时间滚动窗口,代码如下:
average = visits.rolling(7, axis=1).mean().dropna(axis=1)
average.index += " (r. w. a.)"
average结果如下图:
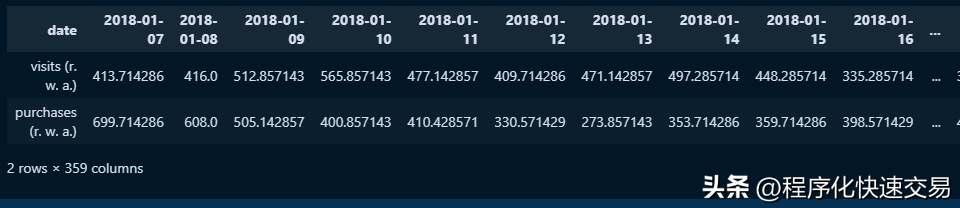
用SQL实现同样的方法,代码如下:
SELECT
(2018_01_01 +
2018_01_02 +
2018_01_03 +
2018_01_04 +
2018_01_05 +
2018_01_06 +
2018_01_07) / 7 AS 2018_01_07,
(2018_01_02 +
2018_01_03 +
2018_01_04 +
2018_01_05 +
2018_01_06 +
2018_01_07 +
2018_01_08) / 7 AS 2018_01_08,
[...省略的代码行]
(2018_12_25 +
2018_12_26 +
2018_12_27 +
2018_12_28 +
2018_12_29 +
2018_12_30 +
2018_12_31) / 7 AS 2018_12_31
FROM
Interactions这需要2513行代码,时间越久,代码行越多!
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/76199
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!