
Pandas是Python环境下一个非常重要的数据管理工具包,随着Python的流行,使用Pandas管理数据越来越多,Pandas提供了600多个函数,具有易学易用、操作灵活、免费开源、执行速度快等特点。pandas和一般的数据库类似,但是也有很大的差异,在很多应用场景下可以替代数据库系统,但是并不能完全替代。


Pandas和SQL两个不同的数据操作工具,都在数据处理中有着广泛的应用,对于新手来说都易学易用;SQL是在有数据库支持的环境下使用,因此需要对数据支持有基本的了解,所操作的数据对象则是以数据表的形式存在,而Pandas的使用环境则比较简单,只要数据是简单的文本格式,就可以在Python中对数据进行操作;此外更重要的一点,常见的数据库系统,一般都对内存有相应的管理机制,一般不会出现内存外溢的情况,而Pandas则是把目标数据都导入内存,再进行操作,所以有可能面临内存不够用的问题。
本文以简单的示例来演示一些Pandas与SQL/Database类似或相同的管理数据的方法,其中数据库系统以PostgreSQL为例。
在postgreSQL数据库系统中创建一个表,命名为 yuangong,创建该表的SQL代码如下:
CREATE TABLE public.yuangong
(
id integer NOT NULL,
department integer,
cpm bool,
name text COLLATE pg_catalog."default",
sex character varying(10),
age integer,
salary real
)
WITH (
OIDS = FALSE
)
TABLESPACE pg_default;测试数据 employee.csv,内容如下:
# number,department,cpm,name,sex,age,sallary
1,1,1,张晓,女,29,24160
2,1,1,李冰,男,32,113781
3,1,0,巫晓琳,女,54,113781
4,1,0,王成东,男,30,113781
5,1,0,刘瑾,女,25,113781
6,1,1,郑晓宁,男,48,19952
7,1,1,李倩倩,女,63,13502
8,1,0,柳林,男,39,112050
9,1,1,赵凯灵,女,53,11769
10,2,0,吴斌,男,30,3381
11,2,1,杨小青,女,28,3381
12,2,0,程兆东,男,30,248744
13,2,0,徐承武,男,28,231945
14,2,0,刘刚,男,25,34050
15,2,0,王东,男,34,226875
16,2,1,徐静,女,36,226875
17,2,0,郑天昊,男,57,244346
18,2,0,周子扬,男,18,29108
19,2,0,程浩,男,23,31030
20,3,0,李强,男,42,5547
21,3,0,肖秀琳,男,22,2673
22,3,0,吴玲玲,男,16,2673
23,3,1,沈文惠,女,35,2673
24,3,1,黎民,女,16,348125
25,3,1,王旭东,男,25,348122
26,3,1,冯涛,男,20,3101284
27,3,1,司马东,女,28,2657
28,3,0,孙露,男,30,7076
29,3,0,崔健东,男,26,341826以上数据的字段说明:number(序号),department (部门编号),cpm(是否党员),name(姓名),sex(性别),age(年龄),sallary(工资)。注意字段名称在csv文件中没有,否则后面导入该文件内容到数据库的数据表会报错。
把 employee.csv 的内容导入到新建的数据库的表中,操作过程如下:
- 把psql命令所在的路径D:\Program Files\PostgreSQL\15\bin追加到默认路径中,在命令提示符窗口下,执行如下命令:
D:\>set PATH=%PATH%;D:\Program Files\PostgreSQL\bin- 把文本文件staff.csv的内容复制到数据库postgres中的员工数据表中,执行命令:
D:\>psql -U postgres -d postgres -h localhost -c "\COPY yuangong FROM employee.csv CSV"以上命令中,-U postgres 表示用户名,-d postgres 表示数据库名称,-h localhost 表示数据库的地址;-c “\COPY yuangong FROM employee.csv CSV” 表示从employee.csv文件中复制内容到数据表 yuangong 中,注意 employee.csv在D:\ 目录下。
- 在Python环境下,导入文件employee.csv,代码如下
import Pandas as pd
yuangong = pd.read_csv("D:\\employee.csv")
yuangong.head()输出结果如下图所示:
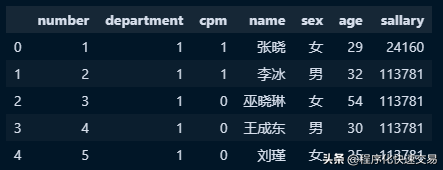
数据操作比较
- 筛选数据
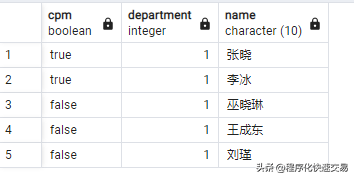
SQL方法:
SELECT cpm, department, name
FROM yuangong
LIMIT 5;输出结果:
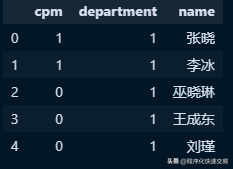
Pandas方法:
yuangong[['cpm', 'department', 'name']].head()输出结果:
where 条件
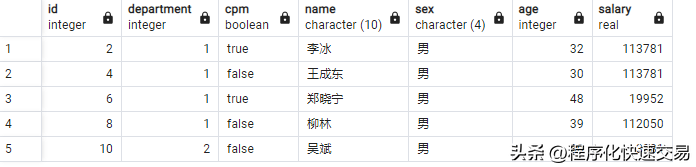
SQL方法:
SELECT *
FROM yuangong
WHERE Sex = 'male'
LIMIT 5;输出结果:
Pandas方法:
yuangong[yuangong['Sex'] == '男'].head()输出结果:
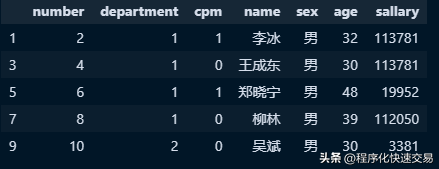
OR和AND操作
SQL方法:
SELECT *
FROM data
WHERE Sex = 'Male' AND Age > 5.00;输出结果:

Pandas方法:
yuangong[(yuangong['sex'] == '男') & (yuangong['age'] > 40)]输出结果:
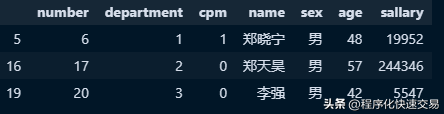
GROUP 分组
SQL方法:
SELECT sex, count(*) FROM yuangong GROUP BY sex;输出结果:
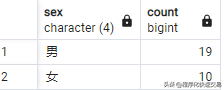
Pandas方法:
yuangong.groupby('sex').size()输出结果:
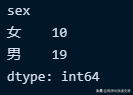
INNER JOIN 内连接操作
SQL方法:
SELECT *
FROM table1
INNER JOIN table2
ON table1.key = table2.key;其中table1和table2有相同的主键。
Pandas方法:
先构建两个dataframe,df1的列为A、B、C、D,df2的列为B、D、D、E,其中的数值为随机数,代码如下:
import numpy as np
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': np.random.randn(4)})
df2 = pd.DataFrame({'key': ['B', 'D', 'D', 'E'],
'value': np.random.randn(4)})执行Pandas内连接的方法:pd.merge(df1, df2, on=’key’),输出结果如下:
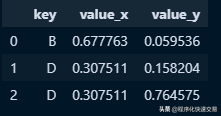
Left outer join 左外连接
SQL方法:
SELECT *
FROM table1
LEFT OUTER JOIN table2
ON table1.key = table2.key;Pandas方法:
pd.merge(df1, df2, on='key', how='left')输出结果:
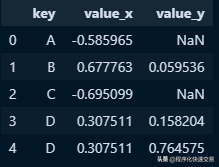
Right outer join 右外连接
SQL方法:
SELECT *
FROM table1
RIGHT OUTER JOIN table2
ON table1.key = table2.key;Pandas方法:
pd.merge(df1, df2, on='key', how='right')输出结果:
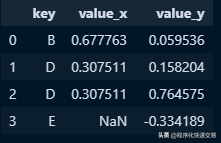
Full join 全连接
SQL方法:
SELECT *
FROM table1
FULL OUTER JOIN table2
ON table1.key = table2.key;Pandas方法:
pd.merge(df1, df2, on='key', how='outer')输出结果:
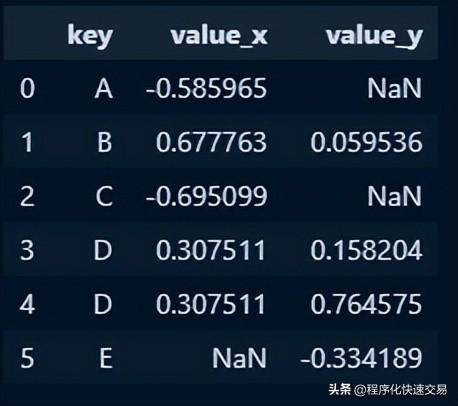
以上几种方法都是在SQL和Pandas中经常用到的,相互之间转换也比较容易理解。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/76213
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!