
Pandas工具包提供了600多个函数,这就为管理和操作数据集提供了非常多的方法,实现某个任务也就比使用SQL更加灵活;由于Pandas在机器学习、线性代数、特征工程、数据清洗等方面都有着广泛的应用,提供非常多的函数也是为了更好地适应不同的场景。
本文主要讲述如何灵活地使用Pandas 下 dataframe 数据结构的数据模型,能更好地适用于数据科学和数据学习的应用环境,以及关系数据库系统下SQL能不能完成相同或类似的操作。特别说明,本文以下内容摘译自英文ponder网,头条文章中不允许提供网站链接,感兴趣可自己搜索;示例代码测试环境为VScode下的Jupyter Notebook。


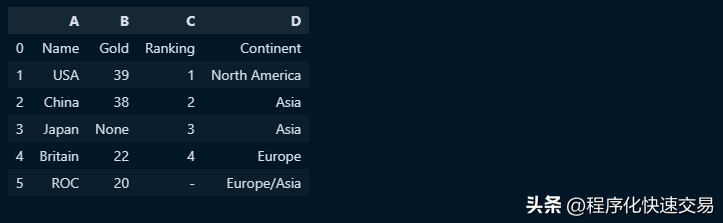
数据来自2020夏季奥运会奖牌榜前五名的数据,
import pandas as pd
df = pd.DataFrame({'A': ['Name', 'USA', 'China', 'Japan', 'Britain', 'ROC'], 'B': ['Gold', 39, 38, None, 22, 20], 'C': ['Ranking', 1, 2, 3, 4, '-'], 'D': ['Continent','North America', 'Asia', 'Asia', 'Europe', 'Europe/Asia']})
df输出结果如下图:
数据转换为元数据或元数据转换为数据
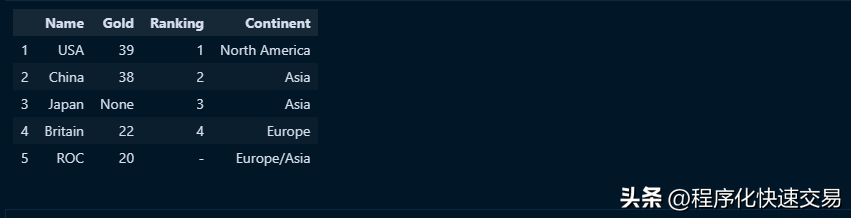
使用pandas可以把数据转换为元数据,或者把元数据转换为数据,但是使用SQL无法实现这种操作,在前文准备的dataframe数据中列名称为A、B、C、D,没有含义描述,实际列名称是数据的组成部分,即第0行数据:Name、Gold、Ranking和Continent,现在用后者替代前者,看pandas中如何实现,代码如下:
header = df.iloc[0]
df = df[1:]
df.columns = header
df代码中先指定 header 为 df 的第一行,然后把df 中的第一行删除,再指定header就是列名称,这就把数据转换成了元数据。输出结果如下图:
下面看看pandas中如何把元数据转换为数据,代码如下:
df_header = df.columns.to_frame()
df_header = df_header.T
df = pd.concat([df_header, df])
df输出结果如下图:
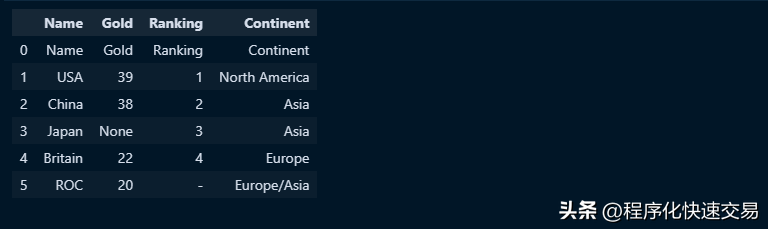
代码中先把df的列名称转换为框结构,作为整个数据的标题行,并进行行列转置后,把df_header和df拼接在一起。
行和列的元数据
在pandas中可以把不同数据类型的列混合使用,而SQL只支持单一数据类型的列;pandas在数据科学领域使用很广泛,在各个阶段都面临清理数据的任务,使用不同数据类型的列,看起来不严格,但是极大地提供了适用性。看看下面的例子:
df = pd.DataFrame({'Name': ['USA', 'China', 'Japan', 'Britain', 'ROC'], 'Gold': [39, 38, None, 22, 20], 'Ranking': [1, 2, 3, 4, '-'], 'Continent': ['North America', 'Asia', 'Asia', 'Europe', 'Europe/Asia']})
df输出结果如下图:
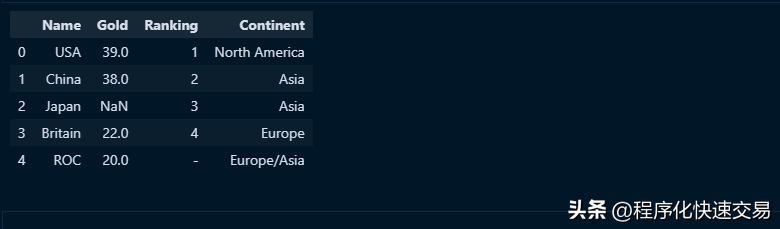
可以看出其中的Ranking列的数据内容有整数类型,也有字符串类型。检查一下该列数据的类型,代码如下:
df['Ranking'].apply(type).value_counts()输出结果如下图,其中有4个是整数类型,1个是字符串类型,这是使用 apply(type) 函数自行判断的结果,

如果想把其中的字符串数据转换为空值,那么该列就只有一种数据类型,操作如下:
df['Ranking'] = pd.to_numeric (df['Ranking'], errors = 'coerce')
df['Ranking'].apply(type).value_counts()输出结果:

灵活的数据规划(flexible schemas)
Pandas中输出数据的规划有多种,可以灵活运用。但是使用SQL时,这样的规划是固定不变的,输出结果只能是列及其类型的集合,输入数据和查询都要受严格的约束;Pandas没有像SQL那样严格的约束,数据输出灵活多样。看下面的例子:
df = pd.DataFrame({'Name': ['USA', 'China', 'Japan', 'Britain', 'ROC'], 'Gold': [39, 38, None, 22, 20], 'Ranking': [1, 2, 3, 4, '-'], 'Continent': ['North America', 'Asia', 'Asia', 'Europe', 'Europe/Asia']})
df_expanded = pd.get_dummies(df, columns=['Continent'])
df_expanded输出结果如下图:
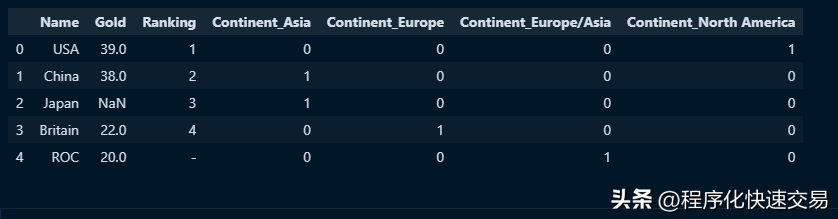
以上代码中的get_dummies函数给 Continent 列中的每个值创建了一个布尔类型的新列,这种特点对于机器学习非常有用,因为绝大多数机器学习工具包只接受数字数据,所有的字符串类型的列都需要转换为数值类型的列。如果忽略数据集中最后一行ROC,就不会生成 conentinent_europe/asia 这一列。生成什么样的列,取决于数据本身的特点!
元数据转换
在pandas中,可以把元数据灵活的转换为列名称或行名称,这对于SQL来说是做不到的。Pandas的数据规划针对元数据操作提供了超强的能力,这不仅仅体现在编程方面。例如,如果觉得 Continent_ 作为列名称的前缀部分不合适,那只需要一行命令就可以删除它,示例代码如下:
df_expanded.columns = df_expanded.columns.str.replace('Continent_', '')
df_expanded输出结果如下图:
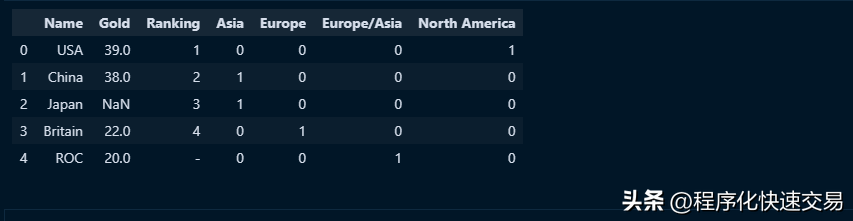
这样的操作,使用SQL就根本不用想了。
列操作
使用Pandas,可以像操作行一样对列进行操作,这对于SQL是不可能的。最常见的用法就是行列转置,
df.T行列转置后的结果如下图:
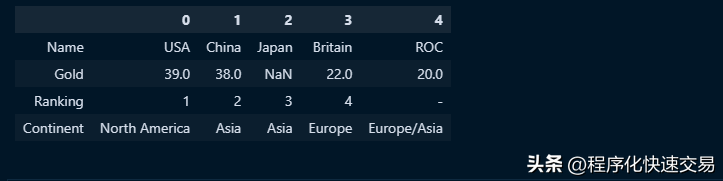
执行行列转置函数时,pandas会自动判断新列的类型,不需要人工指定或定义。这种情况下,所有的列都是混合数据类型的列。除了行列转置这种操作之外,还可以把大多数应用于行的函数应用于列。
层次化的元数据
Pandas中可以使用层次化的元数据,SQL则不行。层次化的元数据有利于组织数据信息,使得数据可读性更好、更直观,pandas不仅支持层次化的行,也支持层次化的列。看下面的示例代码:
df = pd.DataFrame({'Name': ['USA', 'China', 'Japan', 'Britain', 'ROC'], 'Gold': [39, 38, None, 22, 20], 'Ranking': [1, 2, 3, 4, '-'], 'Continent': ['North America', 'Asia', 'Asia', 'Europe', 'Europe/Asia']})
df.set_index(['Continent','Name'])输出结果如下图:
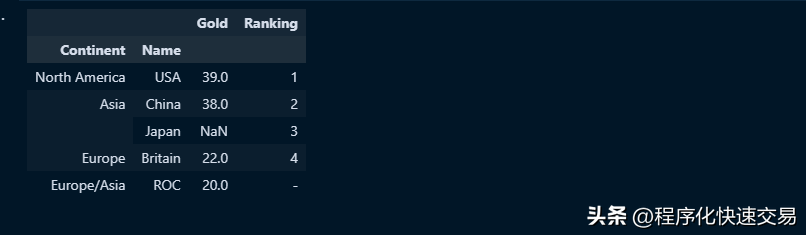
从输出结果可以看出,层次化的行数据包括成对的大洲和国家名称,这是set_index函数指定的,这种特性对于处理JSON、XML等这类数据非常有用。
元数据的冗余
Pandas对于由不同的元数据构成的多个dataframe进行操作,容许存在这样的差异,这样的特性SQL是没有的。就拿concat函数来说,如果另一个dataframe中多了australia、France和Netherlands这三个国家的信息,使用该函数依然可以把两个dataframe合并在一起。示例代码如下:
df = pd.DataFrame({'Name': ['USA', 'China', 'Japan', 'Britain', 'ROC'], 'Gold': [39, 38, None, 22, 20], 'Ranking': [1, 2, 3, 4, '-'], 'Continent': ['North America', 'Asia', 'Asia', 'Europe', 'Europe']})
df2 = pd.DataFrame({'Name': ['Australia', 'Netherlands', 'France'], 'Gold': [17, 10, 10], 'Ranking': [5, 6, 7], 'Continent': ['Australia', 'Europe', 'Europe']})
pd.concat([df,df2])输出结果如下图:
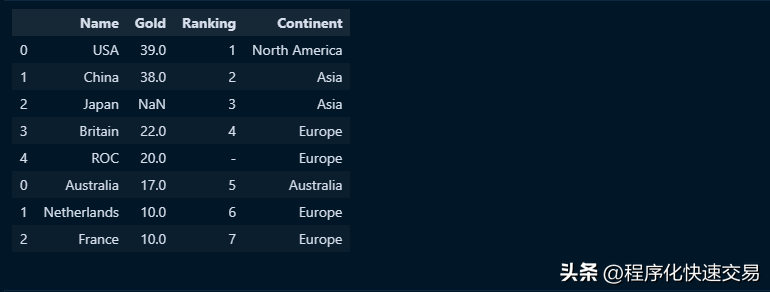
合并后的dataframe有8行数据,这个操作类似于SQL中union 运算符。
如果两个dataframe的结构规划不一样,例如 其中一个dataframe中没有 gold mental 数据,那么两个dataframe合并后是什么样子,代码如下:
df = pd.DataFrame({'Name': ['USA', 'China', 'Japan', 'Britain', 'ROC'], 'Gold': [39, 38, None, 22, 20], 'Ranking': [1, 2, 3, 4, '-'], 'Continent': ['North America', 'Asia', 'Asia', 'Europe', 'Europe']})
df2 = pd.DataFrame({'Name': ['Australia', 'Netherlands', 'France'], 'Ranking': [5, 6, 7], 'Continent': ['Australia', 'Europe', 'Europe']})
pd.concat([df,df2])输出结果如下图:
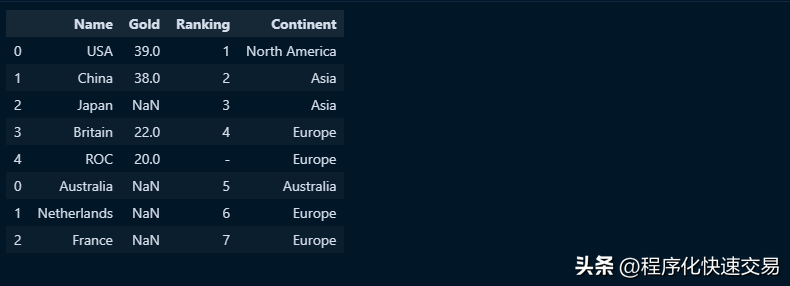
可以看出,后面三行的Gold数据用 “NaN”填充,即空值或null,如果使用SQL实施类似的操作就会报错。
综合以上pandas和SQL在数据管理和操作方面的差别,可以看出pandas比SQL灵活很多,但是pandas的这种灵活设计与其面对的应用场景有关,对于SQL来说受到数据库系统的严格约束也是可以理解的,毕竟pandas和数据库系统/SQL之间有很大的不同。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/76198
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!