
通过对于plt的表现我们可以了解到plt能够实现我们很多东西,比如数据可视化,比如对于关键点位置进行说明,比如对于区间进行显示,比如对于柱状图的书写,都可以让我们更加形象具体精准的发现数据信息以及表达的意思。
其实对于plt库中或者其他库中我们一定要懂得几个道理:
- 通读一遍或者几遍
- 操作一遍或者几遍
- 掌握专有名词和记录好笔记
- 剩下的交给百度即可
理论其实不难,难的是如何去进行布局,通过合理的布局和标记使得自己的意思能够清晰的表达出来,从这点来讲,我们可以从自己的实际简单业务来培养,或者通过他人的案例来参考和学习,调整自身的思路都是不错的。
看书只是给我们一个更加专业系统的搜索提供帮助,也是为我们在搭建新的业务需要的时候提供一种思路,通过基础去启迪我们的思维,不要怕错,不要怕难,毕竟能够遇到的问题基本上百度上面都有。
要勇于开拓思维,举一反三。
是以为文。
系列文章:
import pandas as pd
import numpy as np
import time
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']# 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
fig=plt.figure(figsize=(12,8))
ax=fig.add_subplot(111)
ax.hist(np.random.normal(loc=0,scale=1,size=1000),bins=50,density=False,color='r')
#这里要注意一点的是,ax.hist只接受一条数据,不能接受多条数据。
ax.set_xlabel('样本值',fontsize=15)
ax.set_ylabel('频数',fontsize=15)
ax.set_title('正态分布直方图',fontsize=25)
plt.show()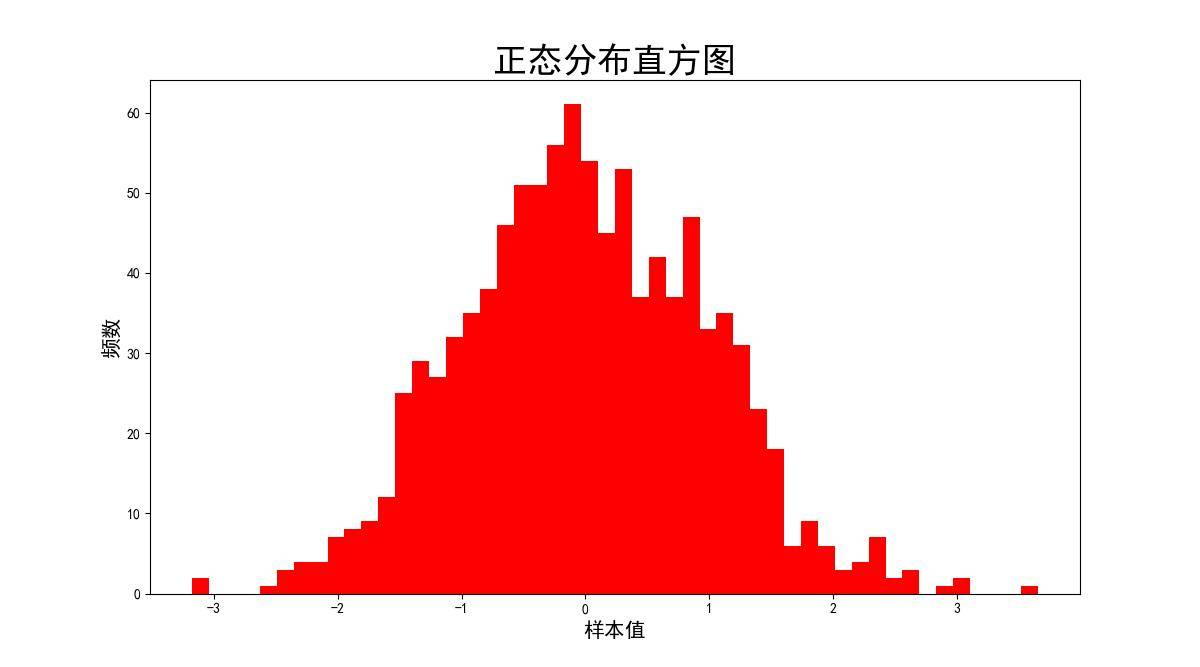
5.2.7K线图的绘制:
以上两个案例我们可以搭建成交量的展示,还有就是涨跌幅的展示,现在我们将通过candlestics2_ochl()函数进行K线绘制。
import pandas as pd
import numpy as np
import time
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']# 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
fig=plt.figure(figsize=(8,6))
ax=fig.add_subplot(111)
#导入数据,数据预处理
df=pd.read_csv('sh600000.csv')
df['date']=pd.to_datetime(df['date'])
df=df.sort_values(by='date')
#截取数据,数据太长无法显示
df=df[-20:]
df=df.reset_index(drop=True)
#引入新函数
import mpl_finance as mpf
#书本用的list格式,笔者尝试用了一下series,这样子可以减少格式的转换。
mpf.candlestick2_ohlc(ax,df['open'],df['high'],df['low'],df['close'],width=0.5,
colorup='r',colordown='g')
#推导式,格式化时间
data_index=[p.strftime("%Y-%m-%d ") for p in df['date']]
#长度
ax.set_xlim(0,10)
#间隔
ax.set_xticks(np.arange(0,10))
#接收list格式,一个参数。
ax.set_xticklabels(data_index,rotation=45)
ax.set_xlabel('日期',fontsize=5)
ax.set_ylabel('价格',fontsize=15)
ax.set_title('日k线图',fontsize=15)
plt.show()
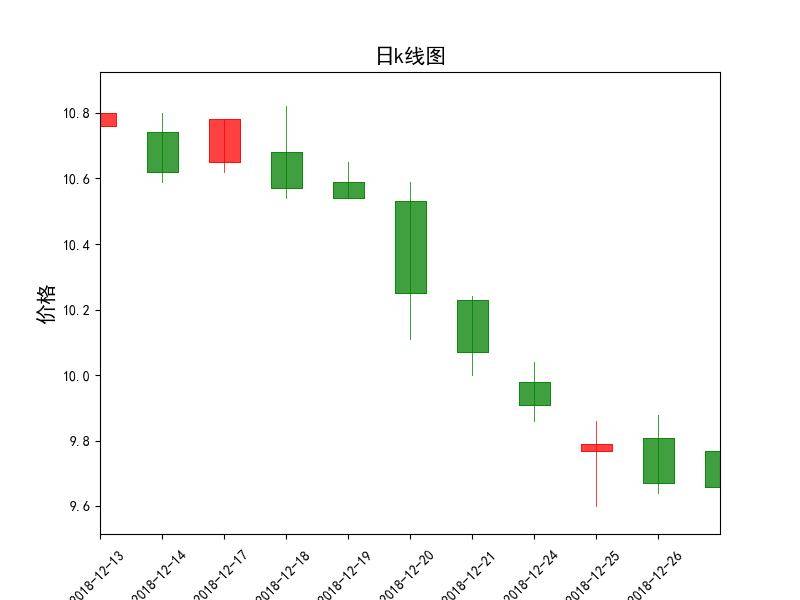
浦发银行的走势
- 考虑两点:一个是如何设置周期,从而自由调整数据周期,一个是如何对数据进行缩放。
5.3图形对象属性参数的调节
略
5.4多子图对象的创建和布局:
这里我们来将个股的数据进行可视化,任务为展示浦发银行的K线图走势,均线走势以及成交量。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import mplfinance as mpf
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = 'SimHei'
#导入数据
df=pd.read_csv('sh600000.csv')
df['date']=pd.to_datetime(df['date'],format='%Y-%m-%d')
df=df.sort_values(by='date')
# df.index=df.pop('date')
df=df.set_index('date')
df=df['2017':'2019']#设计成这个样子,就可以进行封装,调参,测试了。
df=df[[ 'open', 'high', 'low', 'close','volume']]
#因为,mpf会自动识别这五个参数,所以为了防止报错,就取这几个数,防止报错。
#设置参数
my_color = mpf.make_marketcolors(up='red',#上涨时为红色
down='green',#下跌时为绿色
edge='i',#隐藏k线边缘
volume='in',#成交量用同样的颜色
inherit=True)
#设置网格
my_style = mpf.make_mpf_style(gridaxis='both',#设置网格
gridstyle='-.',
y_on_right=True,
marketcolors=my_color)
#生成3条均线
df["sma5"] = df["close"].rolling(5).mean()
df["sma10"] = df["close"].rolling(10).mean()
df["sma30"] = df["close"].rolling(30).mean()
#精确小数点,提高计算精度
df=df.round(2)
#初始化信号
df['sign']=0
#生成信号
for i in range(1,len(df)):
if df.sma5.iloc[i]>df.sma10.iloc[i] and df.sma5.iloc[i-1]<df.sma10.iloc[i-1]:
df.sign.iloc[i]=1
if df.sma5.iloc[i]<df.sma10.iloc[i] and df.sma5.iloc[i - 1]>df.sma10.iloc[i - 1]:
df.sign.iloc[i] =-1
#生成买点位置
df['buysign']=df[df['sign']>0]['sign']
#生成卖点位置
df['sellsign']=df[df['sign']<0]['sign']
#将均线,买点,卖点信号设置好,然后准备传参
add_plot=[mpf.make_addplot(df[['sma5','sma10']]),
mpf.make_addplot(df['buysign'],scatter=True,markersize=80,marker='^',color='r'),
mpf.make_addplot(df['sellsign'],scatter=True,markersize=80,marker='v',color='g')]
#接受设置好的参数
mpf.plot(df,type='candle',
addplot=add_plot,
style=my_style,
volume=True,#展示成交量副图
figratio=(2,1),#设置图片大小
figscale=5)效果图:
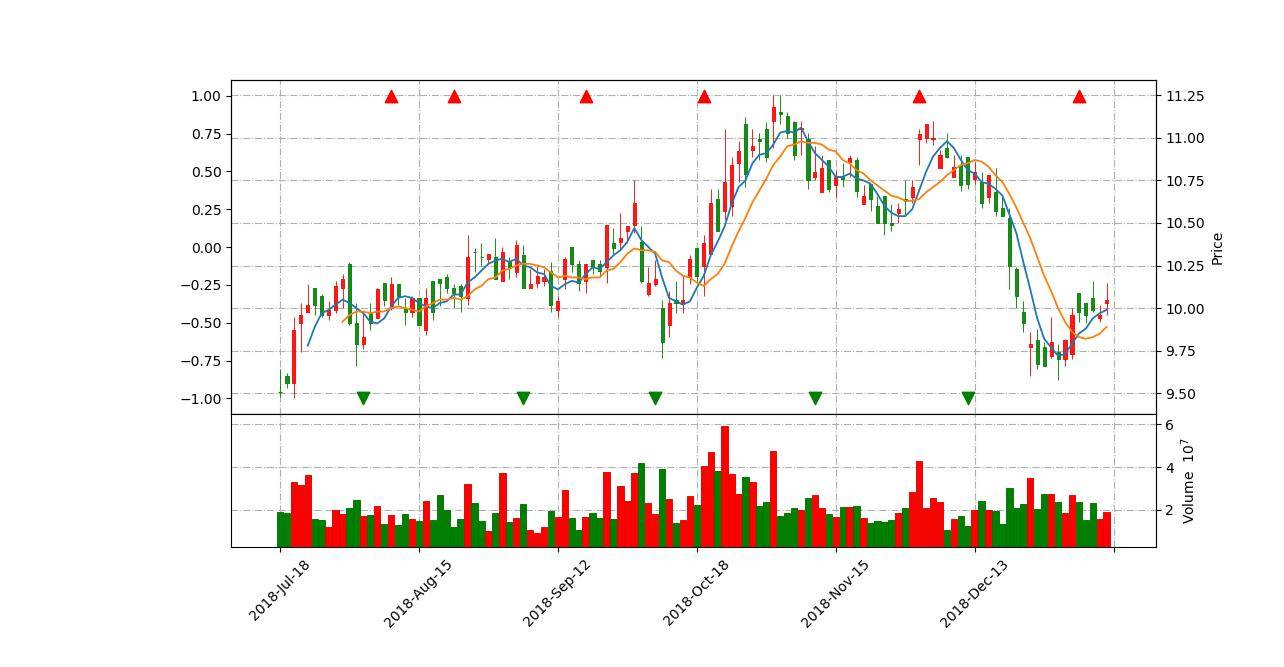
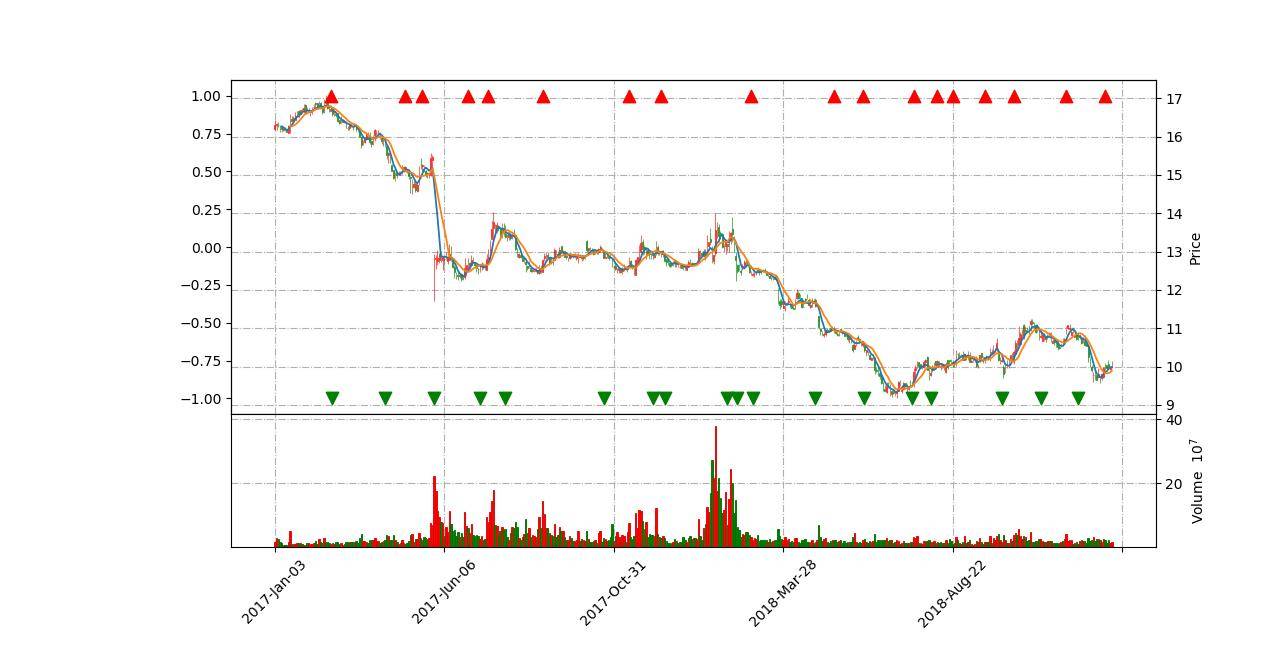
感悟:
- 靠别人都是藏着掖着,不给全码,调试起来太吃亏了,只能根据不同的人文章进行参考学习。
- 学习要趁早,不能拖拖拉拉,原来调用数据,可以通过df.ix进行处理,现在居然没有了,df.at原来不行,后来又可以,现在也不行了,只能通过df.col.iloc[index]进行调用,光就这个问题,我就浪费了太多的时间了。这库更新的也太快了。真的是活到老,学到老。
- 图例的信号还要进行优化,就先这样子吧。
- 关于df[‘buysign’]=df[df[‘sign’]>0][‘sign’]是一个非常好的思路,尽可能地减少迭代,减少计算压力。
- 关于采取for循环的考虑是想运用到模拟盘,但是这种处理仍然会造成未来透视的情况存在,更好的方案应该是单位的bar传入进行运算是最符合实际交易模型的,因此,回测的设计和模拟盘实盘上存在很大的差距,从实际操作和心理活动来讲,回测的引发的情况要更低一些。
- 相关的参数还需要进一步掌握。
- 本章将对可视化告一段落,即将对于数据库保存数据进行处理,通过学习,我们将对于数据的下载进行说明,同时对于数据的清洗,保存,维护进行处理,笔者用的是Navicat for MySQL。
- 尽量采取传参的模式,同时在设计上进行健壮性的调整。以df.ix为例,函数突然失灵,很容易导致整个回测框架失灵,因此应该根据业务要求尽量进行分开才是,便于维护和查阅。
- 至于整体的测试框架还是以B站的量化视频为准,有利用爬虫等模式进行取数,便于后面的模拟盘交易。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/496100
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!
![[通达信指标]大中小全底组合附图公式](https://95sca.cn/2024/08/07/ZJLajxQGwXqvc6A1722996115.6329794.jpg?imageMogr2/thumbnail/!480x300r|imageMogr2/gravity/center/crop/480x300)




![[通达信指标]经典指标 庄家出现 公式源码](https://95sca.cn/2024/08/07/dI6ekAmTwRgce5w1722998305.2903464.jpg?imageMogr2/thumbnail/!480x300r|imageMogr2/gravity/center/crop/480x300)