
文章中通过引入希勒《非理性繁荣》一书来论证市场的涨幅与投资者的普遍预期呈现出相关性,简而言之就是,大众觉得涨,市场就会涨,大众觉得跌,市场就会跌。但是要提出疑问的是,这种情绪的建立是如何形成,如何蔓延的,如果光靠股吧,雪球等方式来进行舆情分析,似乎是一种思路和借鉴,当然也不是没有人这样子做过,有人就通过搜集推特的股票信息进行分析,从而进行预测和调仓。但是这仍然解决不了任何问题。
根据去年的相关新闻报告显示,我国的投资者中,具备本科学历及以上的人数占比在30%左右,也就是说,如果我们能够去认证这30%的投资者掌握着绝大多数的资金,那么他们在股票平台的发言就显得更加掷地有声,但是如果这部分人群的资金只是占据少数,那么他们的话即便是再大声,也不可能主动去影响到这些行情的发展和变化的。
因此论证情绪指标的根本还是在于量和价的关系之上,通过价量的关系来分析本身就是老调重弹,但是赋予了舆情的特色,似乎又有那么点意味,本文也只是对于数据进行一点探索,仅供参考。
其次,Python金融量化的文章中还提到中信证券对于市场关注点进行了梳理,它们分别是以下几类数据:
- (1)市场整体类指标:整体市盈率、市净率、换手率;
- (2)市场结构类指标:上涨家数比下跌家数、小盘股相对大盘股的超额收益率等;
- (3)IPO系列指标:股票首发上市家数、新股上市首日涨幅;
- (4)封闭式基金折价率;
- (5)资金流动指标:A股账户净增加数。
同样,也会作为参考来分析市场情绪的风向标。只不过无论是价格,量能,还是以上的指标,都存在着不同维度的数据跨度太大的情况,不可能马上进行分析,还必须进行数据预处理。
更为重要的是发布的时间上又有间隔和时间跨度,在处理上,很有可能往往只是行情的助推器而已,而本身并不能进行解释什么。但是它们仍然将作为市场分析的重要监测工具来为我们的投资进行服务。
二、ARBR指标计算:
- ARBR实际上是由AR和BR两个指标构成。
AR是通过比较某个周期内的开盘价(open)与最高价(high),最低价(low)来反应市场买卖人气的。
计算公式为:N日AR=(N日内(H-O)之和)/(N日内(O-L)之和)*100。
本质上来讲,所谓的最高价,最低价与日内分时图的均线相比,都是对于价格出现的可能性的期望,对于看空者而言,自然会以更低的价格出售,对于看多者而言,自然会以更高的价格买入,从而形成对于个股走势认识上的一种撕裂。但是我们想要强调的是,更多的走势应当是同样的出价较为集中的地方,相比于最高价和最低价的昙花一现,我们其实更应该关注的是均价以及均价附近的量能,那才是我们应该分析,值得分析的地方。
同时我们也应当清楚的认识到,价格越是紧凑,其方差越小,代表同一方向的看法就越一致,价格越是离散,其方差就越大,代表多空在看法上的不一致。典型就是涨跌停以及盘中的走势来回震荡的几种情况。
这里的紧凑和离散我们可以以方差的形式来计算,同样也可以用振幅的指标来替代。
BR是通过比较一段周期内的收盘价在该周期价格波动的地位。
计算公式为:N日BR=(N日内(H-YC)之和)/N日内(YC-L)之和)*100。
其中,O 为当日开盘价,H 为当日最高价,L 为当日最低价,YC 为前一交易日的收盘价,N 为设定的时间参数,一般原始参数日设定为 26 日,计算周期可以根据自己的经验或回测结果进行修正。【可以通过迭代,寻找最优价,这就是量化的好处,一般书本上提出的经验之谈,均可以通过计算来进行证伪】
三、条件判断:
具体参考大佬文章,我这里就不多说了。
说实话,更像是双均线策略,然后增加了限制交易条件。
四、Python代码实现:
本文以浦发银行(sh.600000)作为参考对象进行梳理。
- 代码块:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#导入数据
df=pd.read_csv('sh600000.csv')
#排序,升序
df=df.sort_values(by='date')
#时间化处理
df['date']=pd.to_datetime(df.date)
#重写索引
df=df[-150:-31]
#指标计算:
df['HO'] = df.high - df.open
df['OL'] = df.open - df.low
df['HCY'] = df.high - df.close.shift(1)
df['CYL'] = df.close.shift(1) - df.low
#计算ar,br指标:
#原文有talib库,电脑没装,所以只能计算。
# df['AR'] = ta.sum(df.HO, timeperiod=26) / ta.sum(df.OL, timeperiod=26) * 100
# df['BR'] = ta.sum(df.HCY, timeperiod=26) / ta.sum(df.CYL, timeperiod=26) * 100
df=df.reset_index(drop=True)
print(df)#检查数据
for i in range(len(df)):
df.at[i,'ar']=100*round(sum(df['HO'][i:i+26])/sum(df['OL'][i:i+26]),2)
df.at[i,'br']=100*round(sum(df['HCY'][i:i+26])/sum(df['CYL'][i:i+26]),2)
#重新制定索引
df.index=df.pop('date')
#双坐标轴使用
df[['ar','br','close']].plot(secondary_y=['close'])
plt.show()- 启示和总结:
1.相关的库要足够多才行,尤其是talib库没有安装的确是十分失策
2.在计算df[‘br’]的过程中,我们发现,df[‘CYL’]居然结果为0,出现了报错。所以不得不反复进行切片,找到不为0的地方进行计算。可见,该策略存在问题,一旦报错就无法进行下去,这种情况下只能进行填充来进行解决,通过抛出异常进行填充。
3.在切片过程中发现df.at[len(df)-1,’br’]数据快速增加,这个让人百思不得其解。
4.该策略虽然好,但是计算上仍然需要注意处理。
ZeroDivisionError: float division by zero
- 图例展示:
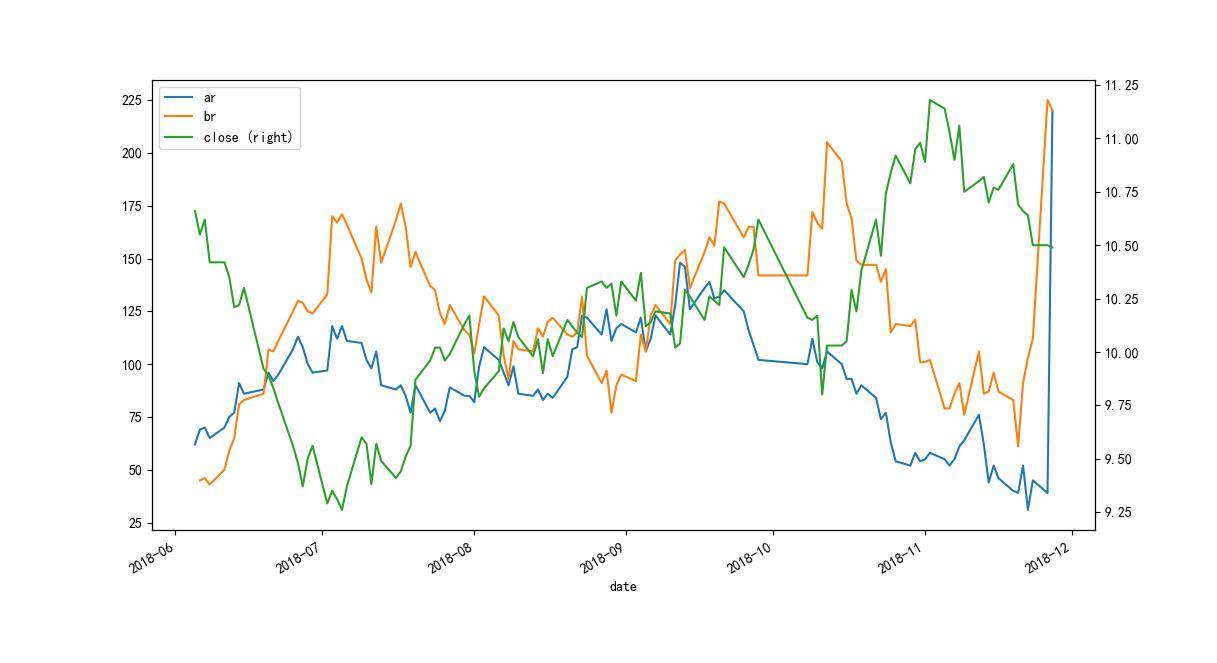
我们可以明显发现,当br上穿ar的过程中,股价已经有很明显的下跌趋势。如果按照这个来进行操作,面临的回撤比例较大,当然仍然需要更多的数据进行检验,单一的样本并不能说明什么。
五、总结:
- 理论丰满,现实刻骨,策略这种东西还是需要进行多测试才是。
- 存在明显的滞后性,这种数据变形中,所以应当尽可能合理选择参数才是。
- 尽管笔者强调回测的致命缺陷,但是回测仍然是淘汰和识别差的策略的重要手段之一。
- 由于笔者只是单一的案例说明,大家可以通过其他数据接口进行分析,从而得出结论。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/496104
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!
![[通达信指标]神兵18期 组合指标 一主两附精选公式 历史神兵组合](https://95sca.cn/2024/08/07/axwhJicO7RdQicQ1722995934.9808311.jpg?imageMogr2/thumbnail/!480x300r|imageMogr2/gravity/center/crop/480x300)



![[通达信指标]神奇开口公式源码](https://95sca.cn/2024/08/07/JRpfdOV75D2mQRA1722998294.7287662.jpg?imageMogr2/thumbnail/!480x300r|imageMogr2/gravity/center/crop/480x300)
