
本文概述:
本文提出了一种新的框架,用于在量化交易领域中生成能够协同工作的公式化Alpha集合。Alpha因子是用于预测市场趋势的信号,而传统的Alpha生成方法通常独立地挖掘每个Alpha,忽略了它们最终将被组合使用的事实。为了解决这一问题,作者们基于强化学习(RL)设计了一个以下游组合模型的性能为优化目标的Alpha挖掘框架。
具体来说,该框架包括两个主要部分:Alpha组合模型和基于RL的Alpha生成器。Alpha组合模型采用线性模型,将多个公式化Alpha组合起来,以实现最优的预测性能。而Alpha生成器则利用序列生成器和策略梯度算法来生成有效的公式化Alpha。作者们还提出了一种新的优化方案,直接使用组合模型的性能作为Alpha生成器的优化目标,从而生成能够更好地适应”挖掘和组合”过程的Alpha集合。
本文亮点:
本文创新之处在于它不仅关注单个Alpha因子的性能,而且还考虑了Alpha集合作为一个整体时的协同效应。通过将组合模型的性能作为训练信号,强化学习能够帮助发现那些在组合中能够相互补充、提高整体预测精度的Alpha因子。相当于在模型层面做了因子的筛选与合成。这种方法在量化交易中具有重要的应用价值,因为它提供了一种系统性的方式来优化交易策略,以期获得更好的投资回报。
本文主线:
1. 引言 (Introduction)
- Alpha因子的重要性:Alpha因子是量化交易策略中用以预测股票未来表现的指标。它们可以基于各种财务指标、市场情绪、宏观经济数据等构建。Alpha因子的有效性直接关系到投资策略能否在市场中获得超额收益。因此,发现高回报的Alpha因子是投资者和研究人员不断追求的目标。
- Alpha因子分类:基于机器学习的Alpha因子和公式化Alpha因子。基于机器学习的Alpha因子通常利用深度学习模型,如LSTM(长短期记忆网络)或Transformer,通过复杂的数据处理和模式识别来预测股票趋势。而公式化Alpha因子则通过简单的数学公式表达,这些公式通常由领域专家根据经验和经济原理手工构建。
- 现有方法的局限性:传统方法在挖掘Alpha因子时,通常是单独一个个地进行,没有考虑到这些Alpha因子最终会被组合在一起使用。此外,机器学习基础的Alpha因子虽然表达能力强,但它们通常比较复杂,缺乏可解释性,当模型性能意外下降时,专家难以调整模型。
2. 问题阐述 (Problem Formulation)
- Alpha因子:定义为一个函数,将交易日的所有股票的特征向量映射到Alpha值。
- Alpha因子挖掘:衡量Alpha有效性的指标是信息系数(Information Coefficient, IC),用于衡量Alpha值和真实股票趋势之间的相关性。
- 公式化Alpha:公式化Alpha因子以数学表达式的形式存在,它们通常由领域专家根据经济原理手工构建。这些因子的优点在于易于理解和解释,但这也带来了搜索空间巨大的挑战,因为可能的公式组合非常多。
- 组合模型的优化需求:为了充分利用Alpha因子集合的潜力,需要一种方法来优化组合模型,使得不同Alpha因子能够协同工作,提高整体的预测性能。这要求Alpha因子挖掘过程不仅要考虑单个因子的有效性,还要考虑它们在组合中的相互作用。
- 研究问题的具体化:本文的研究问题可以概括为一句话:如何设计一个框架,利用强化学习来挖掘一组能够有机组合的公式化Alpha因子?这个框架需要能够直接使用下游组合模型的性能来优化Alpha生成器,从而发现能够提高当前集合性能的新的Alpha因子。
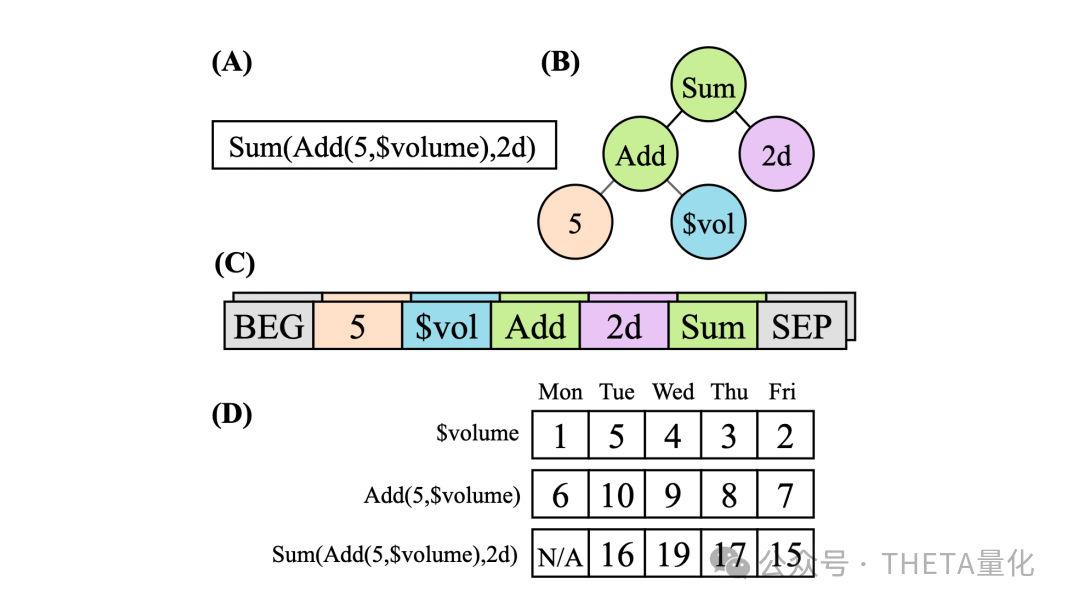
上图为公式化Alpha因子的直观示例,包括它的表达式树、逆波兰表示法(RPN)以及在示例时间序列上的逐步计算过程。
2.1 公式化Alpha示例 (A):这部分展示了一个具体的Alpha因子公式。Alpha因子通常是一个数学表达式,它使用股票的历史数据(如开盘价、收盘价、成交量等)来预测未来的市场表现。
2.2 表达式树 (B):表达式树是公式化Alpha因子的图形表示方法。树中的每个节点代表一个操作符或函数,而叶节点则代表输入特征或常数。从根节点到叶节点的路径定义了Alpha因子的计算逻辑。
2.3 逆波兰表示法 (C):逆波兰表示法(RPN)是表达式树的一种线性表示,它按照后序遍历的顺序列出操作符和操作数。RPN的一个优点是它消除了对括号的需要,因为操作符的顺序和它们操作的操作数都清晰地定义了表达式的结构。
2.4 示例时间序列上的计算 (D):这部分展示了如何使用逆波兰表示法在一组示例数据上计算Alpha因子的值。它逐步展示了如何将时间序列数据代入RPN,按照操作符的优先级依次执行计算,最终得到Alpha值。3. 方法论 (Methodology)
-
- Alpha组合模型:Alpha组合模型的目的是将多个公式化Alpha因子结合起来,以提高预测市场趋势的准确性。由于不同Alpha因子的量级可能差异很大,模型首先对每个Alpha值进行中心化和标准化处理,确保它们具有零均值和单位方差。这种处理不仅有助于优化过程,而且由于皮尔逊相关系数在线性变换下保持不变,因此不会影响Alpha因子单独的性能。
- 线性组合:使用线性模型来组合Alpha因子。
- 标准化:通过中心化和标准化处理,保证Alpha值的均值为0,方差为1。
- Alpha组合模型:Alpha组合模型的目的是将多个公式化Alpha因子结合起来,以提高预测市场趋势的准确性。由于不同Alpha因子的量级可能差异很大,模型首先对每个Alpha值进行中心化和标准化处理,确保它们具有零均值和单位方差。这种处理不仅有助于优化过程,而且由于皮尔逊相关系数在线性变换下保持不变,因此不会影响Alpha因子单独的性能。
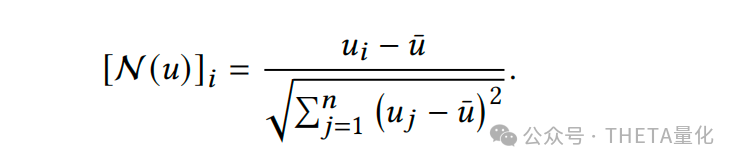
-
- Alpha生成器:Alpha生成器是基于强化学习的方法,特别是采用策略梯度算法,如近端策略优化(PPO)。生成器将公式化Alpha的搜索空间视为一个非平稳的马尔可夫决策过程(MDP),并使用状态空间、动作空间、转移动态、奖励函数等MDP组件来生成有效的Alpha表达式。
- 强化学习:使用PPO算法优化Alpha生成器。
- MDP建模:将Alpha表达式生成过程建模为MDP。
- Alpha生成器:Alpha生成器是基于强化学习的方法,特别是采用策略梯度算法,如近端策略优化(PPO)。生成器将公式化Alpha的搜索空间视为一个非平稳的马尔可夫决策过程(MDP),并使用状态空间、动作空间、转移动态、奖励函数等MDP组件来生成有效的Alpha表达式。
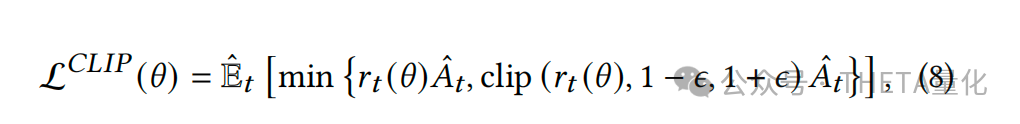
-
- 网络架构 (Network Architecture):网络架构包括一个共享的LSTM特征提取器和两个独立的头:值网络和策略网络。LSTM用于将输入序列(Token序列)转换为密集的向量表示,而MLP则用于进一步处理这些特征,生成动作的分布。
- LSTM特征提取:提取Token序列的特征。
- MLP头:用于输出动作分布的多层感知机。
- 训练方法 (Training Method):训练方法强调在整个训练过程中,Alpha生成器不是追求每集的平均回报,而是追求整体训练过程中的轨迹。通过维护一个Alpha集合,并且在生成新Alpha后,使用组合模型的性能作为奖励信号来更新生成器。
- 策略梯度方法:使用PPO进行策略优化。
- 连续训练:维护Alpha集合,不重制episodes。
- 网络架构 (Network Architecture):网络架构包括一个共享的LSTM特征提取器和两个独立的头:值网络和策略网络。LSTM用于将输入序列(Token序列)转换为密集的向量表示,而MLP则用于进一步处理这些特征,生成动作的分布。
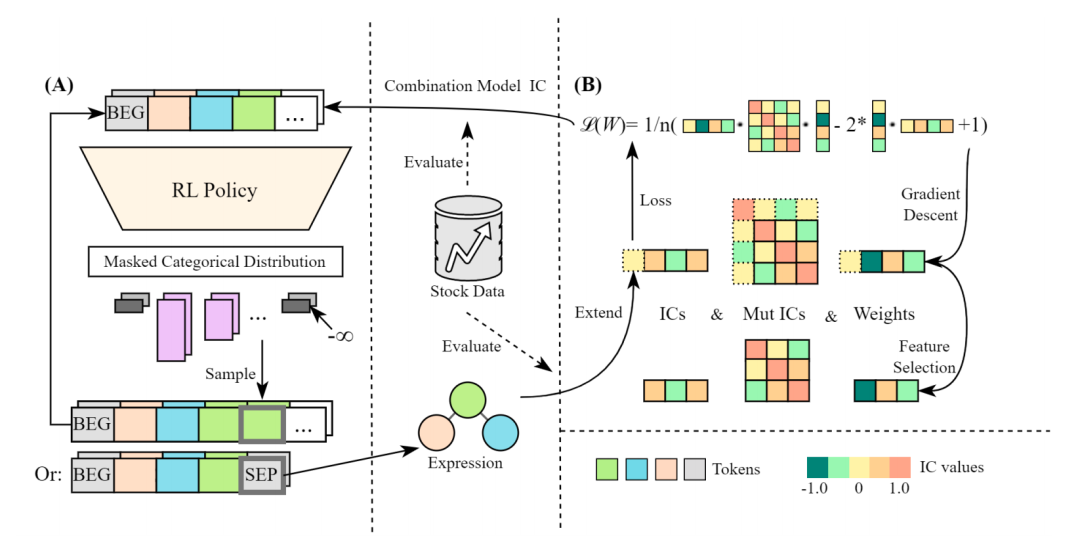
上图展示的框架由两个主要部分组成:Alpha组合模型(Alpha Combination Model)和基于强化学习的Alpha生成器(RL-based Alpha Generator)。
Alpha生成器 (Alpha Generator):
这一部分是一个生成表达式的组件,它通过优化策略梯度算法来生成公式化Alpha。生成器以状态(当前生成的部分表达式的序列)为输入,输出一个动作(下一个Token),这个动作随后被添加到表达式中。
组合模型 (Combination Model):
组合模型负责将多个公式化Alpha组合起来,以实现最优的预测性能。它接收一组Alpha因子,并计算它们的加权组合,其中权重是通过训练过程优化得到的。
优化过程 (Optimization Process):
即如何通过策略梯度方法来更新生成器的策略。这个过程涉及到评估生成的Alpha因子在组合模型中的表现,并使用这些表现作为反馈来指导生成器产生更好的Alpha因子。
奖励信号 (Reward Signal):
组合模型的性能被用作奖励信号,反馈给Alpha生成器。这意味着如果新生成的Alpha因子能够提高组合模型的预测性能,那么生成这个Alpha的策略就会在随后的训练中得到加强。
迭代训练 (Iterative Training):
整个框架是一个迭代训练的过程,其中Alpha生成器不断产生新的Alpha因子,组合模型不断评估这些新因子的性能,并且生成器根据这些性能反馈来优化其策略。4. 实验 (Experiments)
- 实验设置:
- 数据集:作者选择了中国A股市场的数据,并选取了六个原始特征(开盘价、收盘价、最高价、最低价、成交量、成交量加权平均价格)作为Alpha因子的输入。目标是预测股票未来20天的回报率。数据集被分为训练集、验证集和测试集,分别对应不同的时间段。
- 目标:预测股票20天后的回报率。
- 数据集划分:分为训练集、验证集和测试集。
- 比较方法:与遗传编程(GP)和近端策略优化(PPO)等方法进行比较。
- 评估指标:使用了信息系数(IC)和排名信息系数(Rank IC)作为性能评估指标。
4. 一些结论(Results)
下表展示了在CSI 300和CSI 500指数成分股上,不同方法在信息系数(IC)和排名信息系数(Rank IC)上的表现。这些方法包括多层感知机(MLP)、XGBoost、LightGBM、PPO(近端策略优化)、遗传编程(GP)以及本文提出的框架。表中的数值包括平均值和标准差,分别对应10次运行的结果。
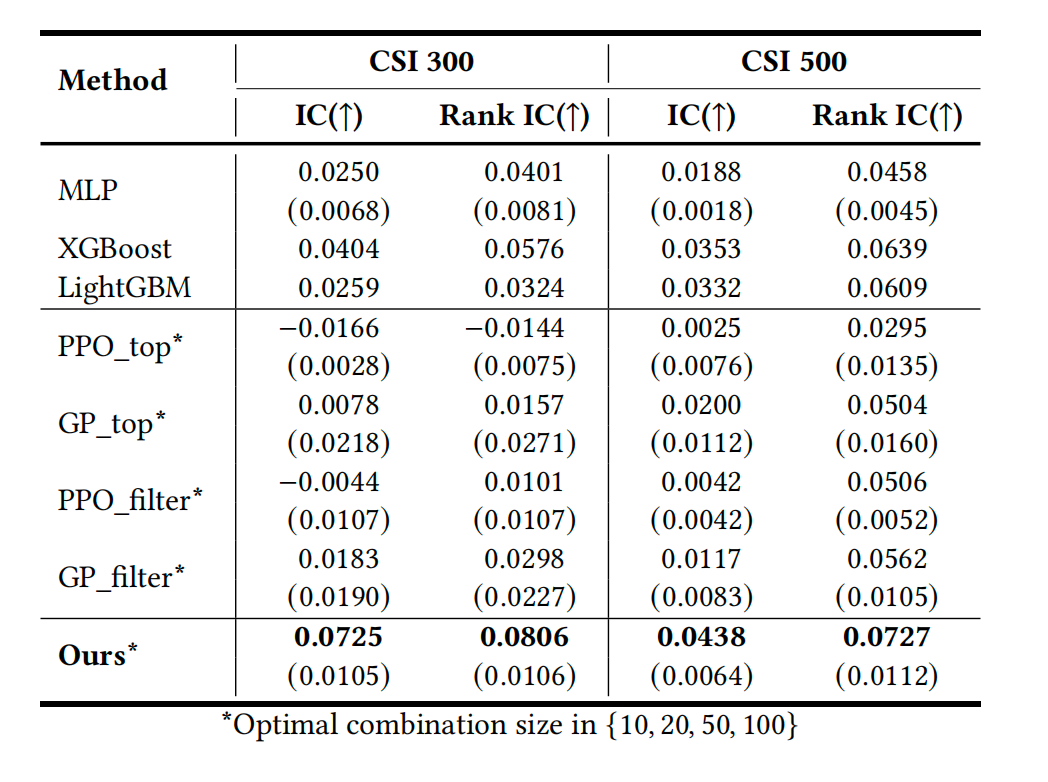
下图展示了不同Alpha集合规模下(1, 10, 20, 50, 100),基线方法(PPO_filter)与本文提出的方法的性能比较。图中显示了随着Alpha集合规模的增加,不同方法在信息系数(IC)上的表现。可以看出本文方法在Alpha集合规模增加时,性能提升显著,显示出良好的扩展性和协同效应。
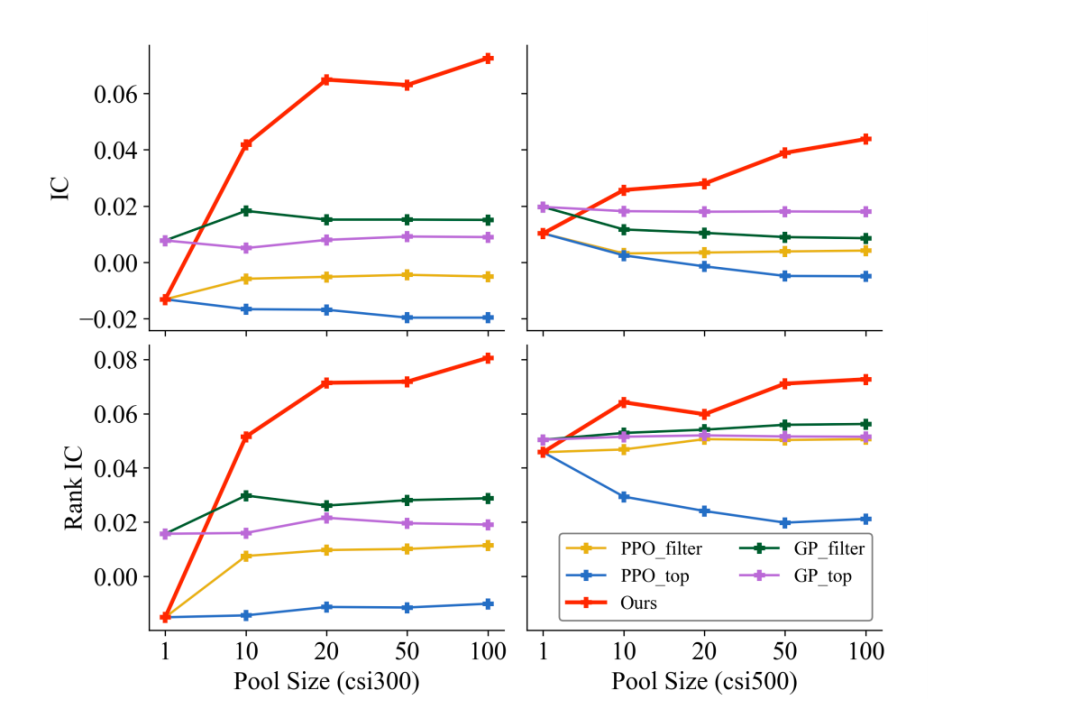
下图为作者使用上述模型在沪深300挖掘出的部分因子,可以看出最终组合起来的IC为5.11%,在沪深300上表现尚可。

发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111123
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!




