
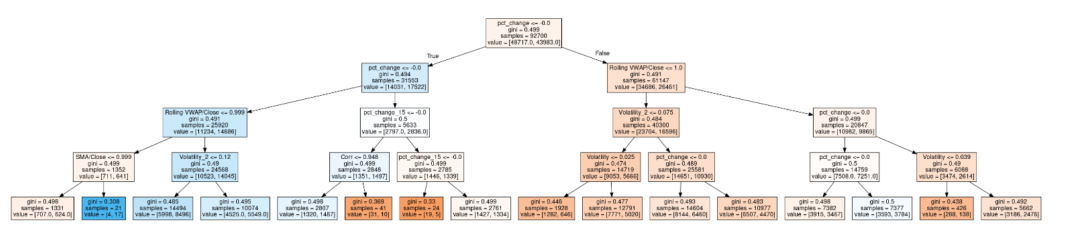
 决策树的优势在于其能够处理多种类型的数据,包括数值型和类别型数据。它们能够创建易于理解和解释的规则,这对于希望理解其交易逻辑的交易者来说非常有用。此外,决策树在处理不平衡数据集方面表现出色,这在金融市场中是常见的情况,因为某些事件可能比其他事件更频繁地影响市场。
决策树的优势在于其能够处理多种类型的数据,包括数值型和类别型数据。它们能够创建易于理解和解释的规则,这对于希望理解其交易逻辑的交易者来说非常有用。此外,决策树在处理不平衡数据集方面表现出色,这在金融市场中是常见的情况,因为某些事件可能比其他事件更频繁地影响市场。
| 特征名称 | 详细描述 |
| 收盘价回报率 | 衡量股票价格变动的基本指标,反映了股票价格在短期内的变化 |
| 15期回报率 | 观察更中期的价格变化,为模型提供了除了短期视角外的额外信息 |
| 14期相对强弱指数(RSI) |
|
| 14期平均方向指数(ADX) | 衡量趋势强度的指标,帮助识别市场趋势的强弱 |
| 14期简单移动平均线(SMA)与收盘价系列的比率 | 反映了长期价格趋势,并与当前价格水平进行比较 |
| SMA与收盘价之间的相关系数 | 评估两者之间的线性关系,为模型提供了趋势一致性的度量 |
| 14期滚动波动率 | 衡量市场在特定周期内的波动性 |
| 210期滚动波动率 | 这是15期滚动回报的14期波动率,提供了不同时间尺度上的市场波动性视角 |
| 14期滚动成交量加权平均价格(VWAP)与收盘价系列的比率 | 评估成交量加权的平均价格与实际价格之间的关系 |
import numpy as npimport pandas as pdfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import sharpe_ratio, annualized_return, max_drawdownfrom vectorbt import signals_to_df, run_backtest## 仅为示例代码## TODO:数据集加载、数据清洗、指标构建、回测# 数据加载def load_data(icici_breeze_api, yahoo_finance_api): pass# 数据调整和同步def adjust_and_sync_data(icici_data, yahoo_data): # 根据文章描述,实现数据调整和同步的逻辑 # 包括计算调整因子,重采样等 pass# 技术指标计算def calculate技术指标(data): # 根据文章中提到的技术指标,计算相应的值 # 包括收盘价回报率、RSI、ADX等 # 此处需要实现具体的技术指标计算逻辑 indicators = {} # 示例:计算14期SMA indicators['14_SMA'] = data['Close']rolling(window=14).mean() pass# 决策树模型训练def train_decision_tree(X, y, max_depth=4, criterion='gini'): clf = DecisionTreeClassifier(max_depth=max_depth, criterion=criterion) clf.fit(X, y) return clf# 策略回测def backtest_strategy(clf, data): # 使用决策树模型生成交易信号 predictions = clf.predict(data) # 将信号转换为可回测的格式 signals = signals_to_df(predictions) # 运行回测 backtest_results = run_backtest( signals=signals, prices=data['Close'], # 此处可以添加交易成本和滑点的参数 ) return backtest_results# 性能评估def evaluate_performance(backtest_results): # 计算关键绩效指标 sharpe = sharpe_ratio(backtest_results.pnl) total_return = annualized_return(backtest_results.pnl) max_dd = max_drawdown(backtest_results.pnl) # 可以添加更多的性能指标 return sharpe, total_return, max_dd# 主函数def main(): # 加载数据 icici_data, yahoo_data = load_data(icici_breeze_api, yahoo_finance_api) # 数据调整和同步 adjusted_data = adjust_and_sync_data(icici_data, yahoo_data) # 计算技术指标 indicators = calculate技术指标(adjusted_data) # 准备训练数据集 X = indicators # 特征集 y = adjusted_data['Signal'] # 目标变量,需要根据实际情况定义 # 训练决策树模型 clf = train_decision_tree(X, y) # 回测策略 backtest_results = backtest_strategy(clf, adjusted_data) # 评估性能 sharpe, total_return, max_dd = evaluate_performance(backtest_results) # 打印结果 print(f"Sharpe Ratio: {sharpe}") print(f"Total Return: {total_return}") print(f"Max Drawdown: {max_dd}")
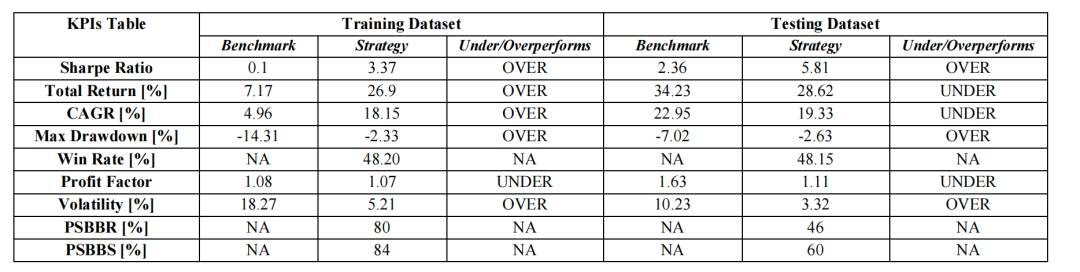
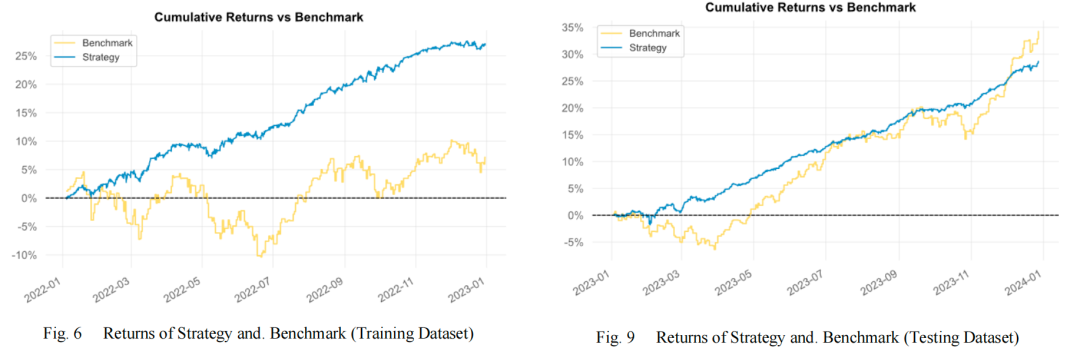
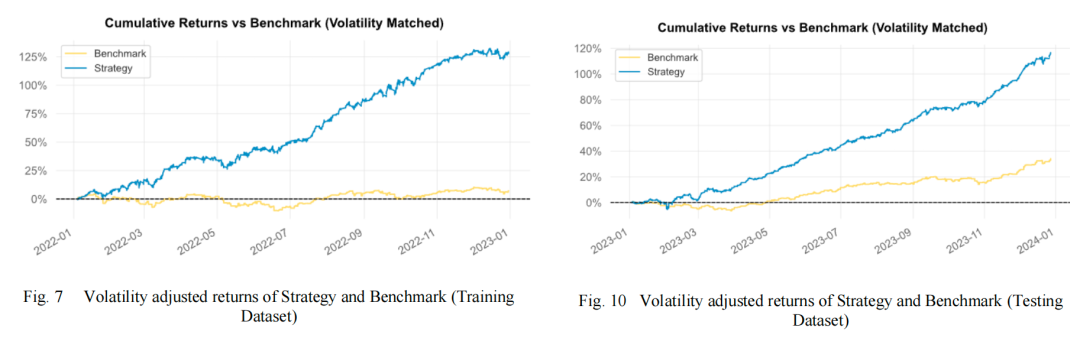
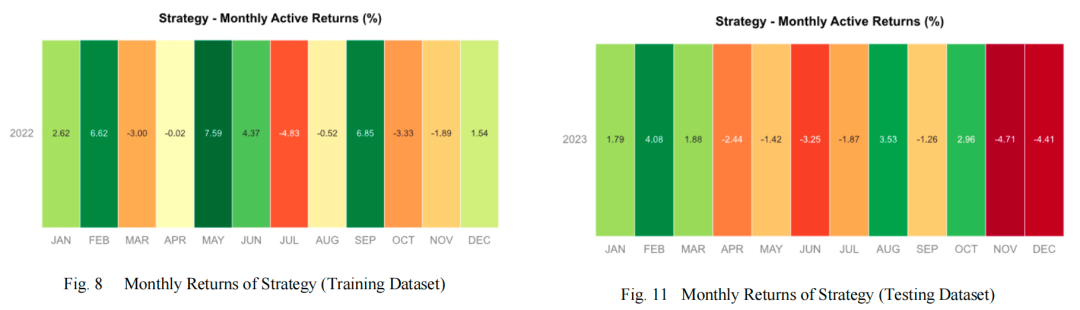
上图展示了策略的月度回报,这有助于观察策略在不同市场环境下的一致性和稳定性。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111122
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





