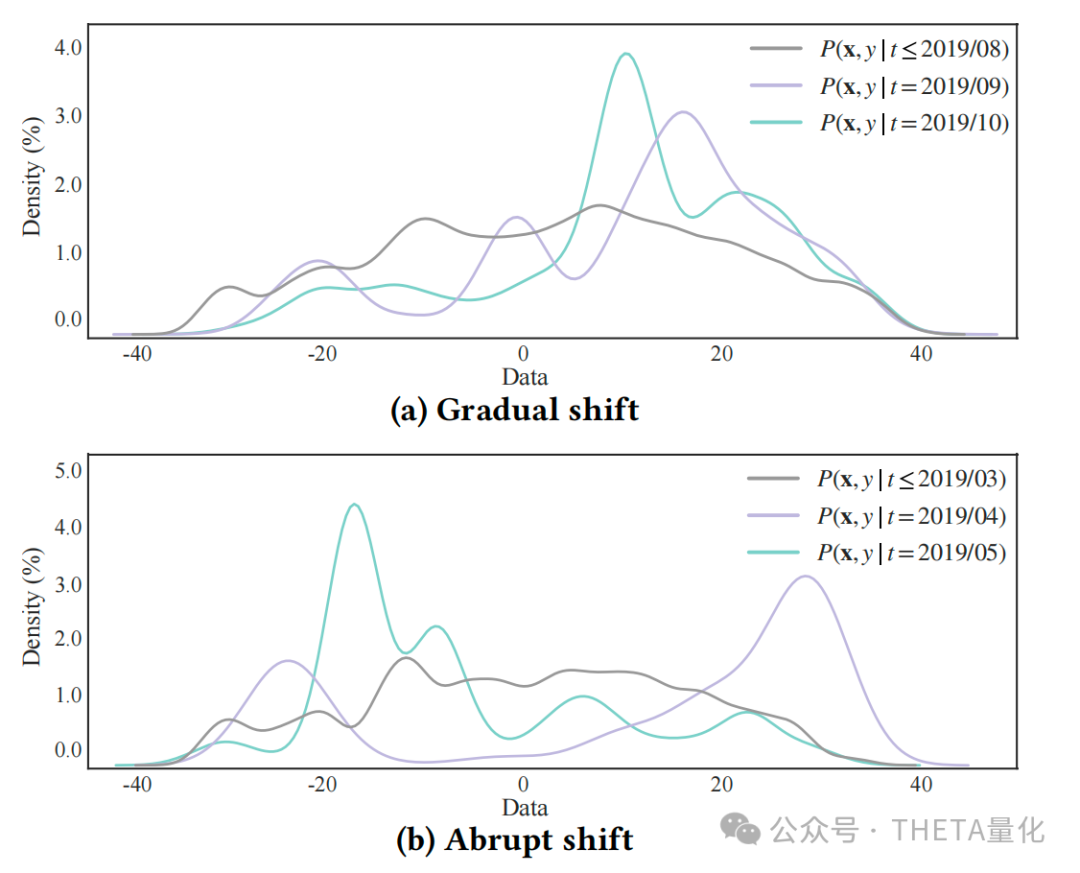
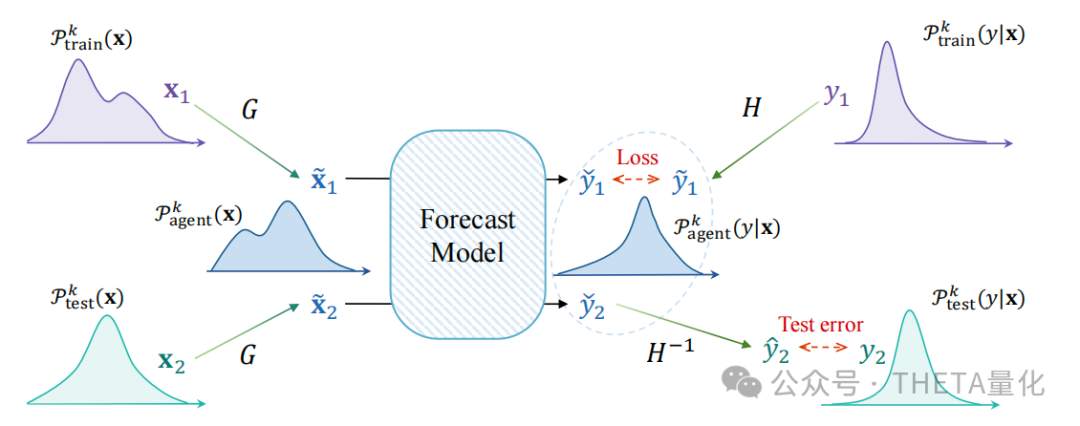
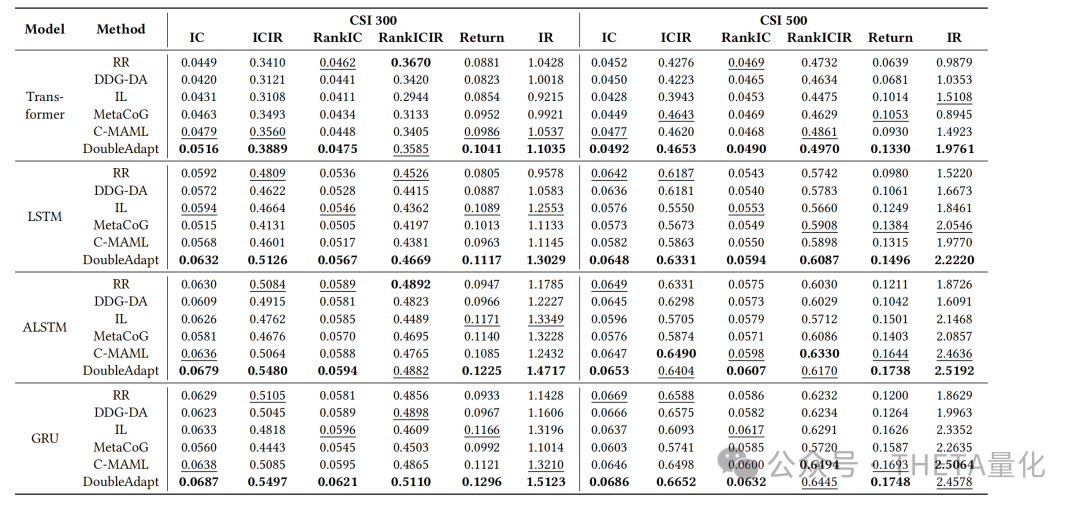
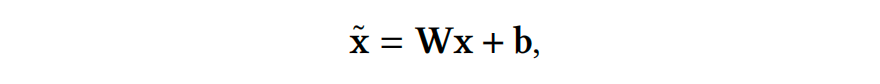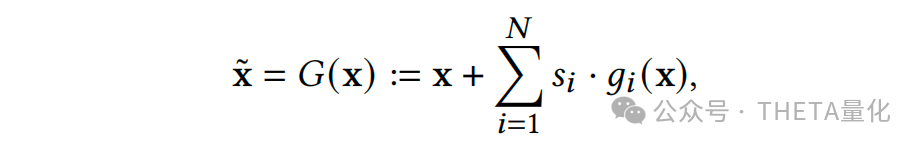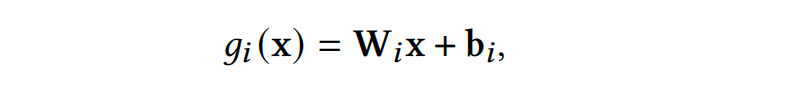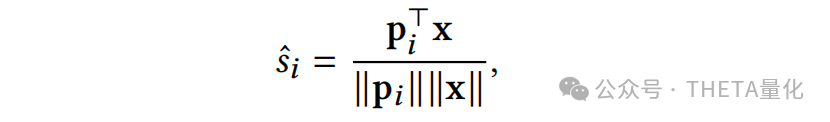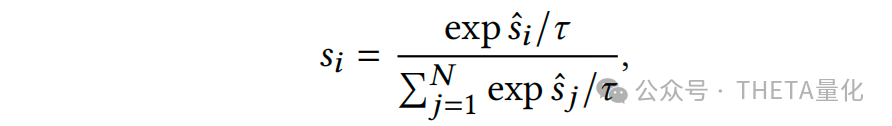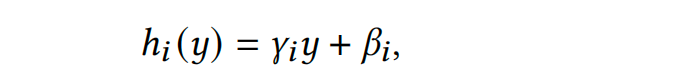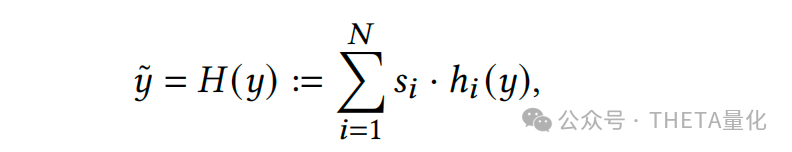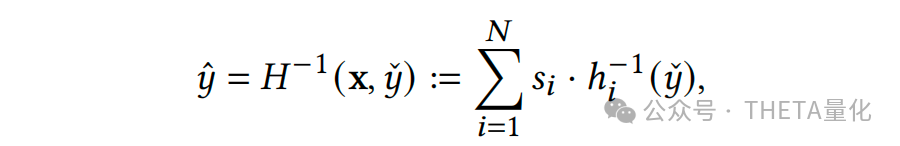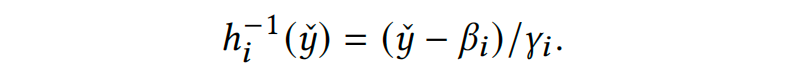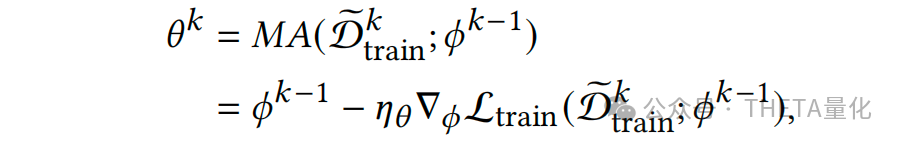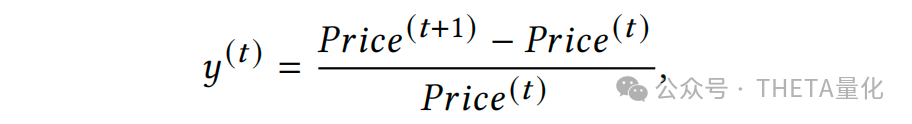本文概述:本文提出了一个名为DoubleAdapt的端到端框架,用于增量学习在股票趋势预测中的应用。关键词DoubleAdapt即两个适配器(data adapter和model adapter)的框架来适应数据和模型,以减轻分布偏移(distribution shifts)的影响;这也是本文的重要亮点。DoubleAdapt背后的思考是自动学习如何将股票数据适应到一个局部平稳分布中,以便于进行更有效的更新。通过数据适应,作者能够自信地在减轻的分布偏移下适应模型参数。此外,作者将每个增量学习任务视为一个元学习任务,并自动优化适配器以实现理想的数据适应和参数初始化。在真实世界的股票数据集上的实验表明,DoubleAdapt在预测性能上达到了最先进的水平,并且显示出相当的效率。本文贡献:●端到端增量学习框架:提出了DoubleAdapt,这是一个端到端的增量学习框架,用于股票趋势预测。它能够适应数据和模型,以应对在线环境中的分布变化。●双层优化问题:将每个增量学习任务构建为双层优化问题。底层是使用模型适配器初始化的预测模型,并使用适应的增量数据进行微调。上层包括数据适配器和模型适配器作为两个元学习器,它们被优化以最小化在适应的测试数据上的预测误差。●实际数据集上的实验:在真实世界的数据集上进行了实验,证明了DoubleAdapt在不同种类的分布变化下都能有效工作,并且与滚动重新训练(RR)方法和元学习方法相比,达到了最先进的预测性能。以往的股票预测任务往往是采取滚动向前训练的方式,这会遇到两方面的问题。首先在多次滚动训练后模型会遗忘之前的数据,其次由于每次的滚动窗口较长,retrain的时间消耗都比较巨大;针对上述这两类问题,增量训练的方式可以比较好地解决。所谓元学习,本文提出的核心框架即为DoubleAdapt方法。后文会着重介绍这一部分。DoubleAdapt上面提到了增量学习的好处,那是完全什么都不用做直接训练就好了吗?显然不是。增量学习所面对的最大挑战就是分布偏移(distribution shifts)问题,比较明显的是新进来的增量数据很可能与原始模型训练使用的数据分布差异很大,直接拿去用可能导致模型学了半天啥有用的信息都没学到。为了解决上述偏移的问题,本文提出的DoubleAdapt方法即两步调整,分为调数据的data adaptation和调模型的model adaptation。1. data adaptation为了减轻增量数据分布偏移的问题,作者提出了一种细粒度的方式来调整所有的feature和label,背后的核心思想是一些分布偏移的模式会在历史数据中重复多次出现且可以被模型所学习。例如,在牛市中出现利多新闻,市场情绪往往过热从而反映在股价中,此时股价往往会经历异常波动后在未来几周内趋于正常。一方面,我们会希望从feature和label中剔除这些反应过度的成分,以接近未来的倾向;另一方面,当我们假设原始的增量数据是可靠的(reliable),那么具有不同分布的测试数据可以被视为一个有偏的数据集,则将测试数据的分布适应增量数据的分布具有去偏效果。
解释完data adaptation的动机和作用后,其具体做法可分两步走。第一步去解决协方差偏移(covariate shifts),利用映射函数G细粒度地调整train、test特征,使得train和test的特征分布向代理分布agent靠拢;第二步解决条件分布偏移(conditional distribution shifts),同样的,利用映射函数H去调整train的label以期望其条件分布向代理agent条件分布靠拢;最后有个逆映射的过程即将模型输出的预测agent条件分布转换为test的条件分布。
2. data adaptation首先我们会实现训练好一个模型,MA在做的事就是将这个训练好的模型参数去调整适应新增数据集(incremental data)。当我们拿到一个新的训练集train,首先会根据上面data adaptation步骤将其调整为train_hat。现在有了预测模型F,有了train_hat训练集,我们会在train_hat上对模型F进行fine-tune。求解的损失函数如下: