
论文 | Generating Synergistic Formulaic Alpha Collections via Reinforcement Learning
代码 | https://github.com/RL-MLDM/alphagen
一 本文导读
在量化交易领域,将历史股票数据转化为市场趋势的指示信号是一种常见的做法,这些信号通常被称为alpha因子。在实践中,通常会同时使用一组公式化的alpha因子以提高建模精度,因此需要找到能够良好配合的公式化alpha因子集。然而,大多数传统的alpha生成器都是单独一个一个地挖掘alpha因子,忽略alpha因子组合之后产生的影响。本文提出了一种新的alpha挖掘框架,使用强化学习直接利用下游组合模型的性能来优化alpha生成器以优先挖掘一组具有协同作用的alpha因子。在A股的CSI300和CSI500成份股上进行测试,相对基线的表现,本文方法挖掘到的因子的IC(信息系数)提升了80%,由0.0404提升到了0.0725。
二 相关工作
发现高回报的alpha因子一直是投资者和研究人员关注的热门话题,因为alpha因子和投资收益密切相关。发现alpha因子的方法大致可以分为两类,即基于机器学习和公式化alpha因子。最近的研究主要集中在前者上。通过深度学习模型获得复杂的alpha因子,例如使用LSTM等序列模型,或者集成非标准数据的更复杂模型,如HIST和REST等。另一方面,可以用简单的公式形式表示的alpha因子是传统上由人类专家利用他们的领域知识和经验构建的,通常表达明确的经济原则。
尽管现有方法取得了显著的成功,它们仍然在不同方面存在缺点。基于机器学习的alpha因子天生复杂,有时需要比价格/成交量特征更复杂的数据。此外,虽然它们通常更具表现力,但它们往往缺乏相对较低的解释性和可解释性。因此,当这些“黑匣子”模型的性能意外地恶化时,人类专家很难相应地调整模型。因此,在某些情况下,这些算法不受欢迎,因为存在风险问题。另一方面,虽然公式化alpha因子更易于解释,但以往的研究往往集中于找到单个能够独立良好预测的alpha因子。然而,用简单规则描述股市等复杂混沌系统通常是不可能的。因此,实践中通常使用一组这些alpha因子,而不是单独使用它们。然而,用传统方法挖掘的独立alpha因子组合在一起时,最终预测性能可能不会显著提高,因为没有考虑因子之间的协同作用。
研究者面临的问题是如何找到一组自动发现的可解释alpha因子,使其与下游预测模型协同工作,而不会因alpha因子被广泛公开而可能导致性能下降。以往的工作大多尝试简化alpha因子集挖掘的问题,通过逐个挖掘alpha因子并根据某些相似性度量过滤出一个子集。互信息系数(IC)通常被用作相似度“度量”。然而,将一个具有高IC的新alpha因子添加到现有alpha因子池中可能仍然会为组合结果带来非常大的性能提升,反之亦然。即使将组合模型设置为简单的线性回归器,这种现象仍然存在。因此,传统的确定一组alpha因子是否具有协同作用的方法与预期的结果不一致。
三 本文工作
本文工作提出了一个利用强化学习来改善搜索空间的探索,并使用带有约束条件的序列生成器和基于策略梯度算法来生成有效的公式alpha因子的框架。该框架直接基于性能优化alpha因子的生成,而不是使用传统的互信息过滤方法。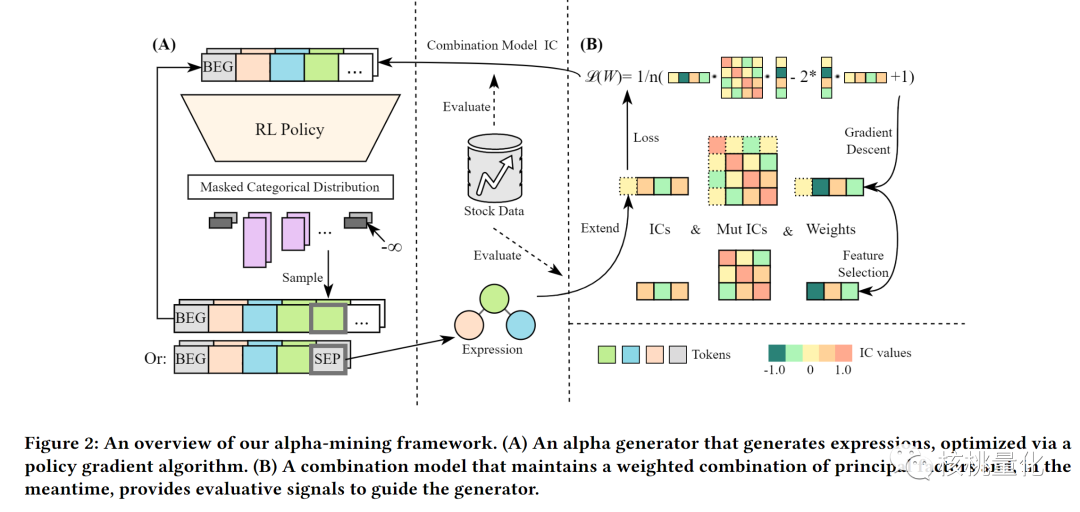
如上图所示,整个算法分为两部分:因子生成和因子评估,两部分交替运行。
因子生成
在股票市场中,每只股票有多维数据,每天有一个向量包含该股票在近几天的历史数据。为了研究股票的因子值,在这些数据上定义了一个与时间和具体数据无关的因子函数,作用于股票数据得到一个因子值的时间序列。这个因子函数是一个数学表达式,由算子、特征、常数、时间窗口和特殊符号组成。每个符号都与一棵表达式树等价,可以通过生成逆波兰表达式的方式来生成因子。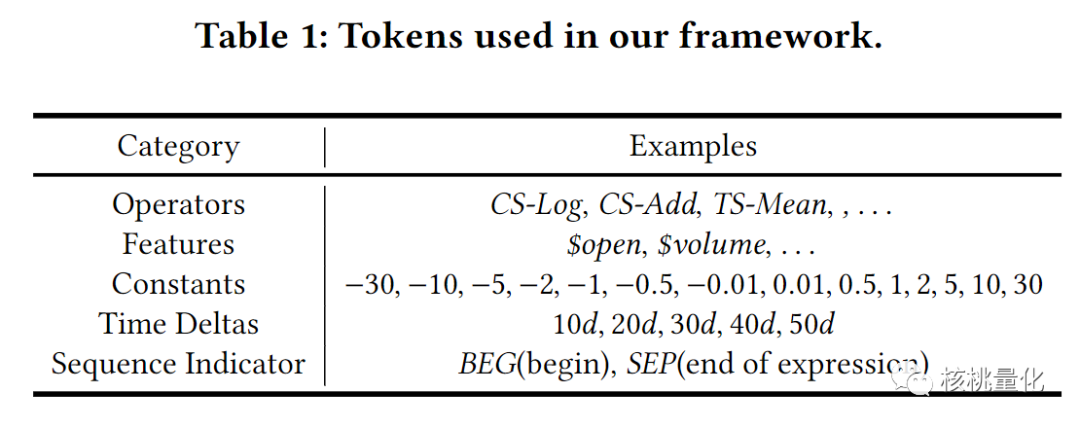
上表展示了因子表达式中可以用的算子,特征,常数,时间窗口以及特殊符号。下图展示了一个因子表达式和对应的逆波兰表达式。逆波兰表示法是一种数学表达式的表示方法,它将运算符写在操作数之后,而不是写在操作数之间,从而避免了使用括号。具体来说,每个因子都可以转换为一个逆波兰表达式,其中操作数是股票数据中的特征、常数和时间窗口,操作符是算子。对于每个股票样本,在时间序列上应用逆波兰表达式,就可以得到对应的因子值序列。这种表示方法可以使因子的生成和计算更加高效和方便。在逆波兰表达式中,每个元素都必须是一个操作数或操作符,且操作数和操作符的数量必须满足特定的规则。如果表达式不符合这些规则,就是一个不合法的表达式。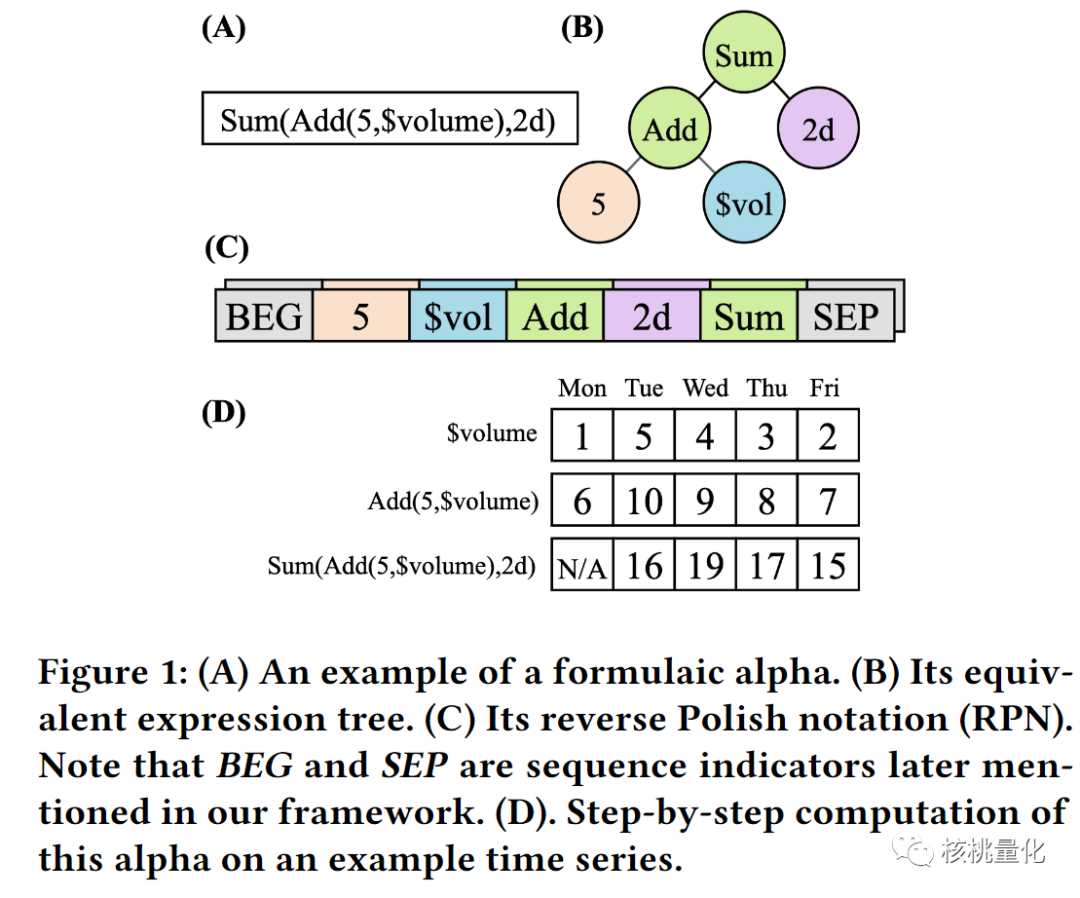
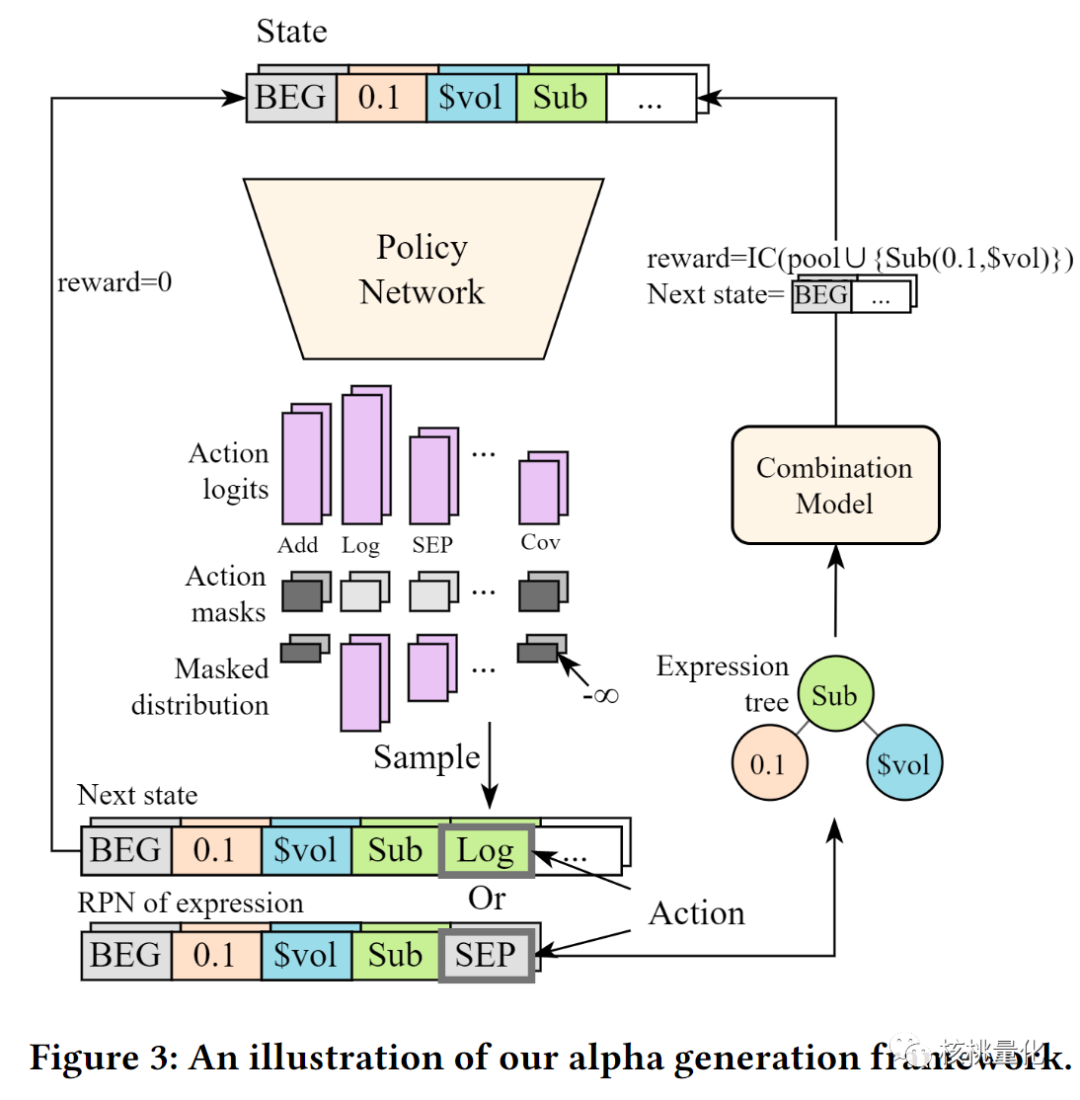
本文使用强化学习来生成因子的逆波兰表达式,步骤如下:
-
定义状态(State),包括当前已经部分生成的序列和其他相关信息(例如历史数据等)。 -
定义行动(Action),即将要添加到序列尾部的下一个Token。 -
定义状态转移(Dynamic),即将行动对应的Token添加到状态的末尾,得到新的状态。 -
定义奖励(Reward),即序列仅在结束时有非0的奖励,将序列转换为因子即为结束状态。合法因子的奖励为集成模型更新后的IC(信息系数),非法因子的奖励为-1。 -
定义动作掩蔽(Action Mask),为了保证因子的形式有效性,我们能够根据状态判断一个动作是否合法,不合法的动作将被掩蔽。 -
使用动作掩码PPO算法来训练因子的生成器。在每个时间步,根据当前状态选择一个行动,并生成新的状态和奖励。根据这些信息,更新生成器的策略,使其能够更好地生成合法的逆波兰表达式,从而获得更高的奖励。
对应的伪代码如下:
因子评估
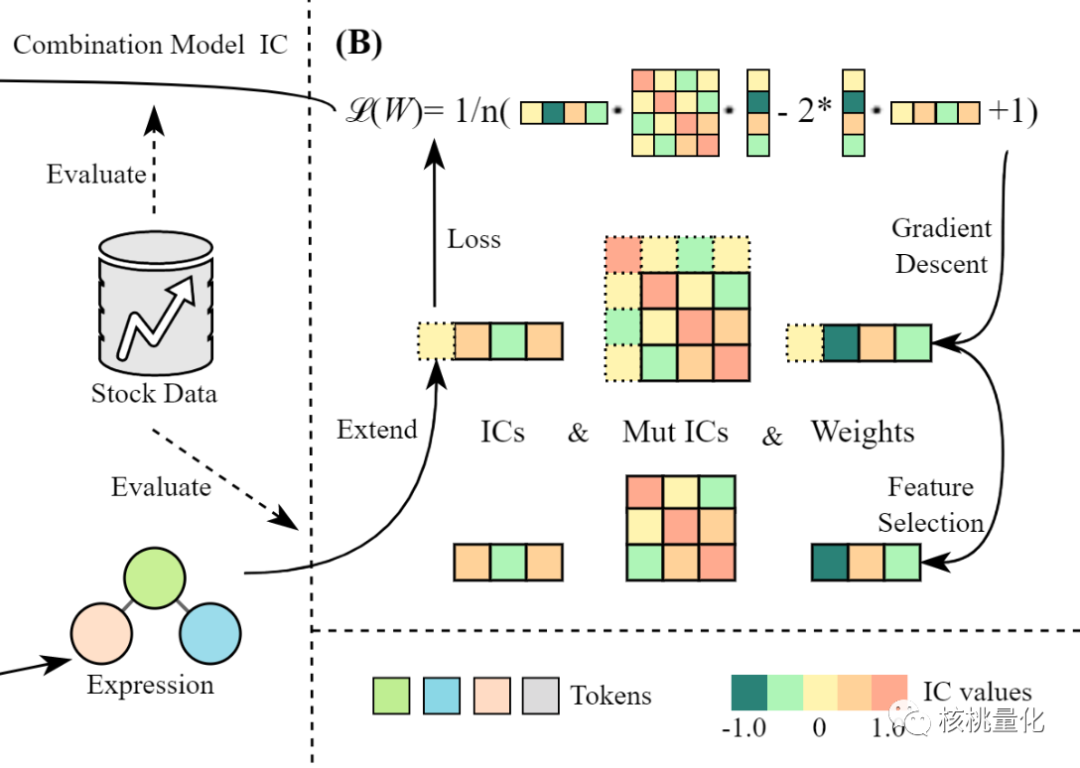
为了将不同因子的计算值进行集成,本文采用了一个线性模型来组合因子值,其中每个因子在因子池中都有一个特定的权重。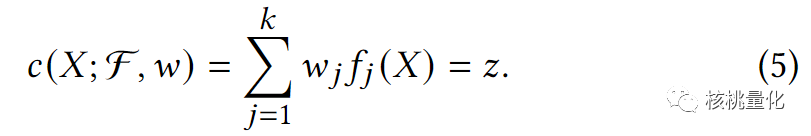
这个集成模型的主要目的是将多个因子的信息整合在一起,以获得更准确的股票价格预测。由于不同因子的计算值可能有数量级的差别,通过对因子进行了归一化,以避免数量级差异对模型的影响。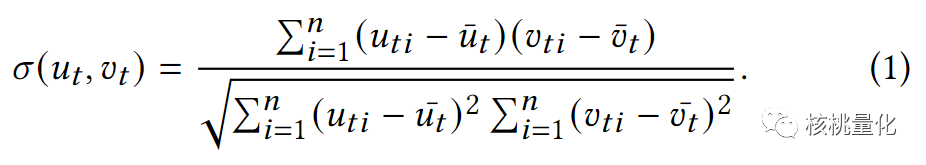
定义了一个损失函数来衡量模型输出和未来收益率之间的相关性,即因子值与未来收益率的Pearson相关系数的按日平均。这个损失函数是通过对每个股票的未来20天收益率进行统计得到的。使用梯度下降算法来更新模型中每个因子的权重,以最小化损失函数。集成模型可以是任何类型的模型,本文使用了一个线性模型,因为它易于解释和调整。下面是损失函数的详细计算公式,其中包括单个因子与未来收益率的按日平均以及因子间相互IC的按日平均。这种方法可以显著降低计算复杂度,能够在实践中更好地处理大规模数据集。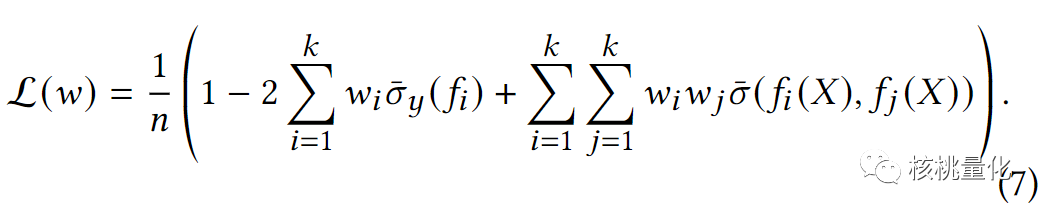
对应的伪代码如下:
四 实验结果
本文使用中国A股市场的原始数据进行实验,选择了6个原始特征作为alpha的输入,目标是股票的20天收益率。数据集按日期划分为训练集(2009年1月1日至2018年12月31日)、验证集(2019年1月1日至2019年12月31日)和测试集(2020年1月1日至2021年12月31日),并使用CSI300和CSI500指数的成分股作为股票集。作者实现了两种方法来生成alpha,分别是基于遗传编程的GP模型和基于强化学习的PPO模型。为了避免过拟合,作者构建了由两个单个alpha生成器生成的alpha集合,并使用相同的组合模型应用于这些alpha集合。为了评估模型性能,作者将其方法与在开源库Qlib中实现的几个端到端机器学习模型进行比较,包括XGBoost、LightGBM和MLP。
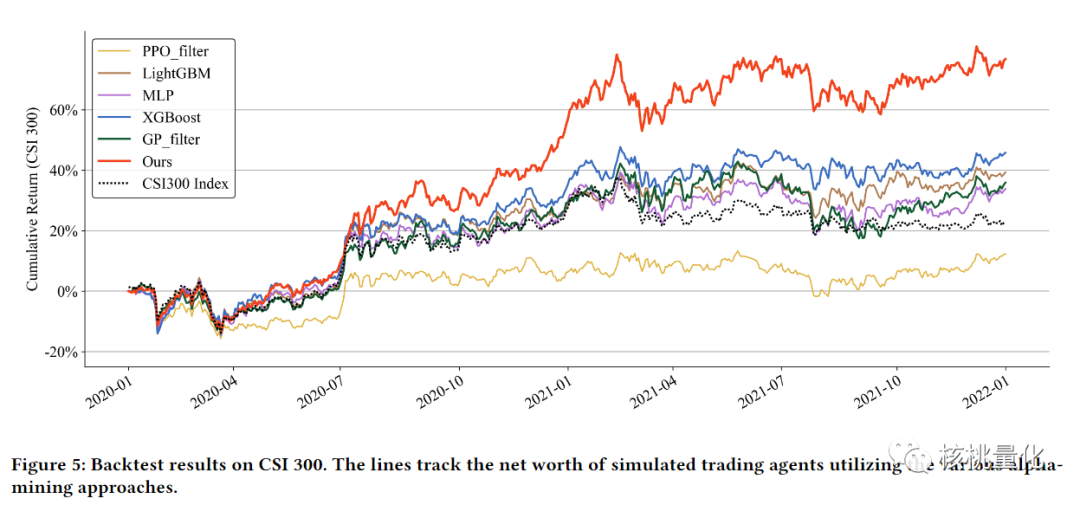


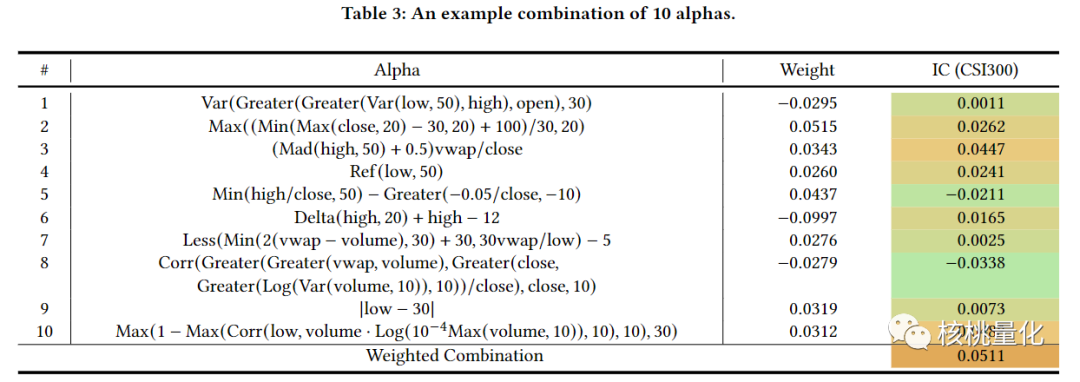
五 总结展望
本文介绍了一种新的alpha挖掘框架,使用强化学习直接利用下游组合模型的性能来优化alpha生成器以挖掘具有协同作用的alpha因子。该框架通过使用序列生成器和基于策略梯度算法来生成有效的公式alpha因子,并利用强化学习来改善搜索空间的探索。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/110978
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





