
本文概述:
本文提出了一种新颖的双阶段注意力机制的循环神经网络(DA-RNN),用于时间序列预测。时间序列预测是指根据过去的数据,预测未来的值。常见的时间序列预测方法包括自回归移动平均模型(ARMA)和其非线性扩展模型(NARX)。然而,这些传统方法在处理长时间依赖关系和选择相关输入特征时存在不足。为了解决这些问题,作者提出了DA-RNN模型,该模型结合了输入注意力机制和时间注意力机制,能够自适应地选择相关输入特征并捕获时间序列的长期依赖关系。实验表明,DA-RNN在两个公开数据集(SML 2010和NASDAQ 100股票数据集)上的预测性能优于现有的先进方法。
本文亮点:
-
双阶段注意力机制:模型引入了两种注意力机制,分别是输入注意力机制和时间注意力机制。输入注意力机制能够在每个时间步自适应地选择相关的驱动序列,而时间注意力机制能够在所有时间步中选择相关的编码器隐藏状态。
-
有效处理长时间依赖:传统的循环神经网络(RNN)在处理长时间依赖关系时存在梯度消失问题,作者通过结合长短期记忆(LSTM)单元和注意力机制,成功解决了这一问题,使得模型能够更好地捕获时间序列中的长期依赖关系。
-
易于解释:DA-RNN模型不仅能够进行高精度的时间序列预测,还能够通过注意力机制展示哪些输入特征和时间步对预测结果有重要影响,这使得模型具有较好的可解释性。
-
强大的预测性能:实验结果表明,DA-RNN在两个不同的数据集上(SML 2010用于室内温度预测,NASDAQ 100股票数据集用于股价预测)的表现均优于其他先进的时间序列预测方法,如传统的ARIMA模型、NARX RNN、编码器-解码器网络和单阶段注意力RNN等。
-
鲁棒性:通过在数据集中引入噪声,实验验证了DA-RNN对噪声数据具有良好的鲁棒性,能够在噪声环境中仍保持较高的预测精度。
本文主线:
本文的模型是是基于LSTM进行了优化,既然是优化就是解决了原模型的某些问题。具体而言有两点:一是未对输入特征的重要性加以区分,二是当输入的时间步长增加时编码-解码器网络性能会剧烈下降。针对此本文最重要的创新也分为输入注意力机制(Encoder with input attention)和时间注意力机制(Decoder with temporal attention)两块。
后文的网络结构部分会按照基础LSTM、输入注意力机制、时间注意力机制的顺序进行讲解。
网络结构:
1. rawLSTM
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN),专门用于解决标准RNN中的梯度消失和梯度爆炸问题。LSTM通过引入记忆单元和控制信息流动的三个门(输入门、遗忘门和输出门)来实现这一点。市面上介绍该网络的文章非常多,这里推荐这篇文章:
https://blog.csdn.net/v_JULY_v/article/details/89894058
下面就从6个步骤简单带过LSTM的数理逻辑:
遗忘门:
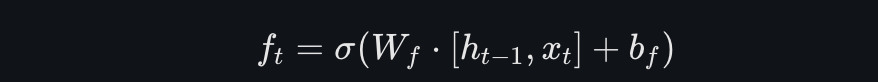

遗忘门决定了前一个记忆单元的状态𝐶𝑡−1在当前时刻应该被遗忘多少
输入门:
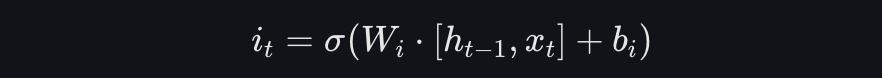 输入门决定了当前时刻的输入信息𝑥𝑡有多少需要被写入记忆单元
输入门决定了当前时刻的输入信息𝑥𝑡有多少需要被写入记忆单元
候选记忆单元:
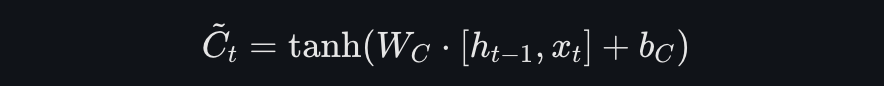
候选记忆单元是通过当前输入和前一个隐藏状态生成的新的记忆信息。
更新记忆单元:
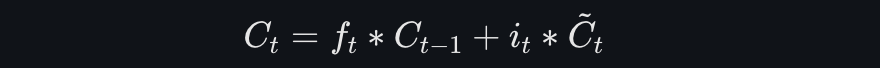
当前时刻的记忆单元状态由遗忘部分的旧记忆和写入部分的新记忆共同决定
输出门:
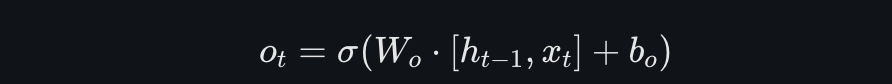
输出门决定了记忆单元的状态将如何影响隐藏状态
更新隐藏状态:

隐藏状态结合输出门和记忆单元状态,作为当前时刻的输出
2. 输入注意力机制:
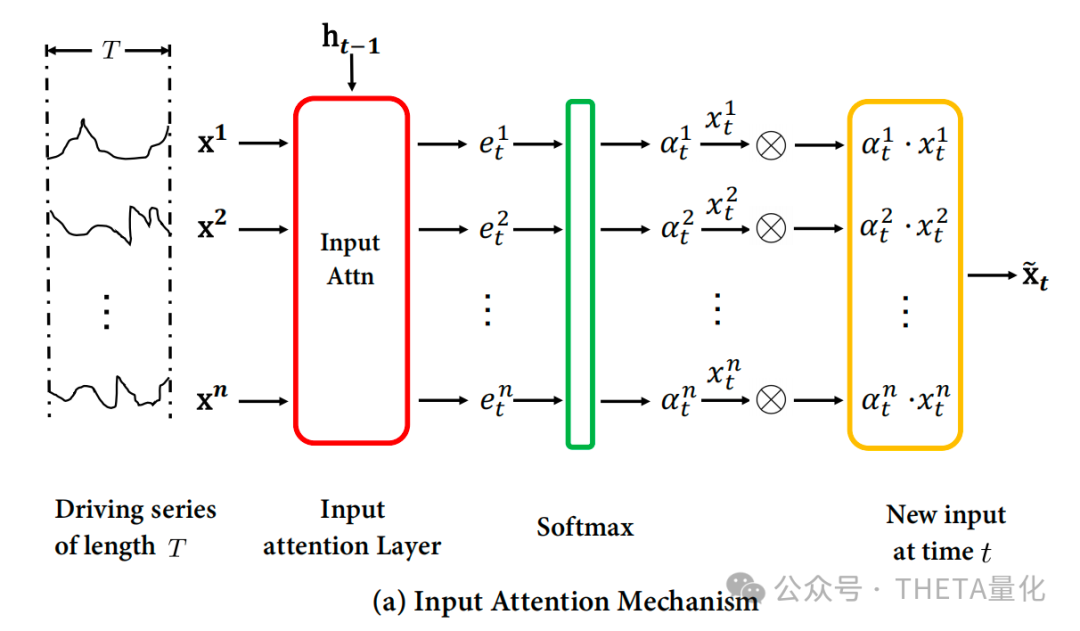
简单来说这一步是在特征输入模型之前进行操作,为了给多个特征赋予不同的权重(重要程度)再进行后续的模型训练。
从原始输入特征转换为新特征可以分三步进行:
1. 输入注意力得分:
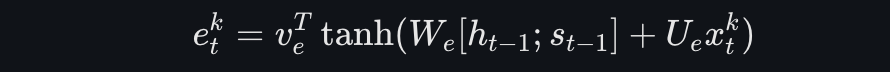
这里,𝑒𝑡𝑘表示第k个驱动序列在时间步t的注意力得分。公式里的v、W、U都是模型要去学习迭代的参数,注意这个公式中是省略了偏置项
- 输入注意力权重:
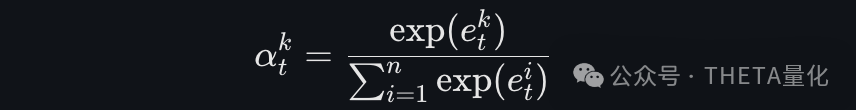
使用softmax函数计算每个驱动序列的注意力权重
- 计算新的输入特征:
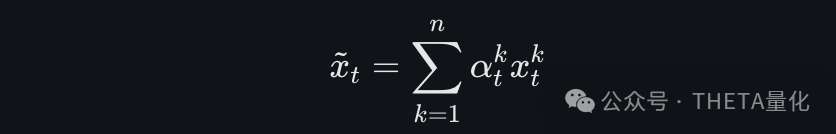
将注意力权重应用于各驱动序列,得到新的输入特征。于是新的特征序列可以表示如下:
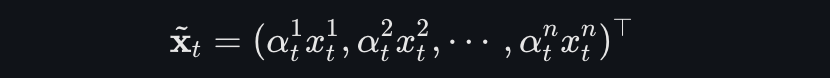
与传统LSTM类似,DA-RNN中的LSTM单元更新隐藏状态和记忆单元状态,但使用新的输入特征:
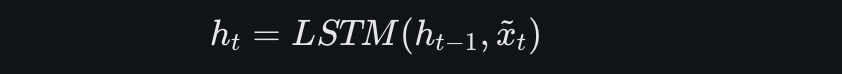
3. 时间注意力
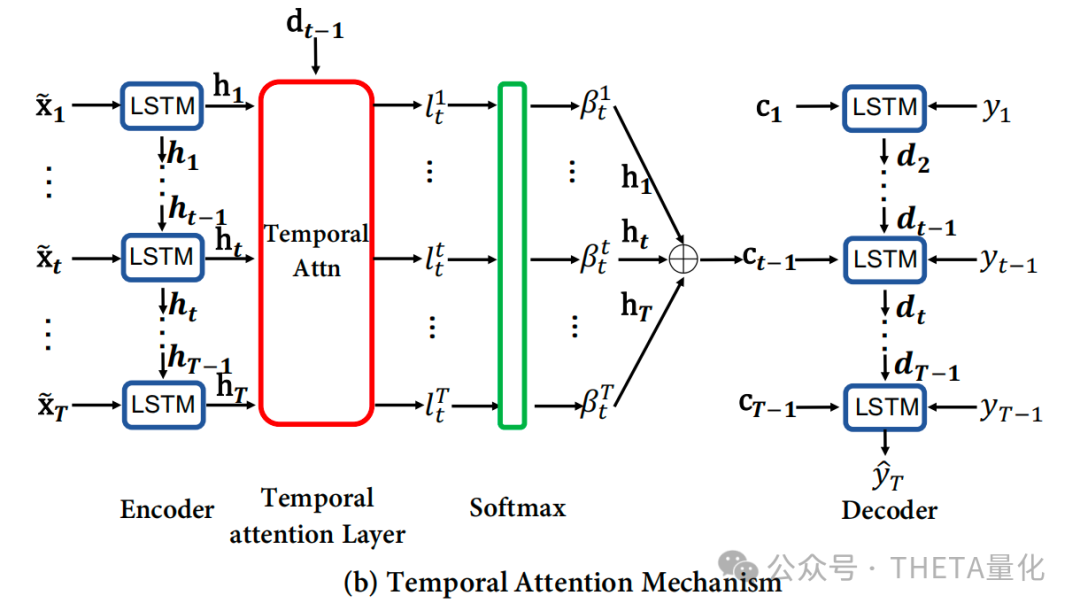
这个架构的设计是为了解决时间步长过多情况下导致的性能下降,即在所有时间步中自适应地选择相关的编码器隐藏状态。该部分也可解构为三步:
1. 时间注意力得分:
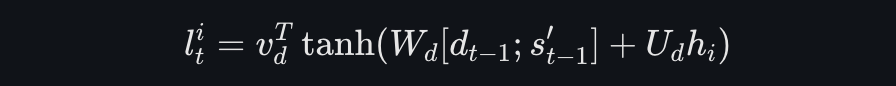
这里,l{t}表示第i个时间步的编码器隐藏状态在时间步t的注意力得分。可以从公式中看出在计算注意力得分时主要依赖的是前一步解码器的隐藏状态dt-1和
- 时间注意力权重:
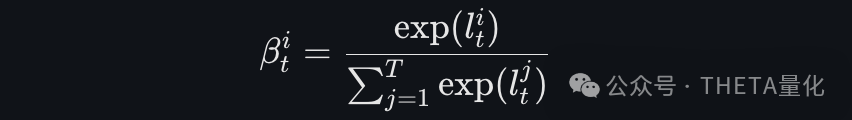
使用softmax函数计算每个时间步的注意力权重
- 计算上下文向量:
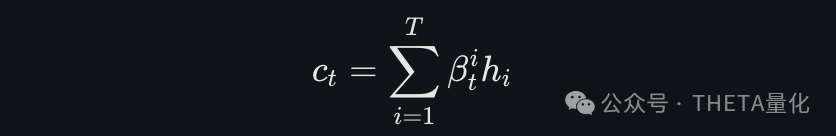
将时间注意力权重应用于各时间步的隐藏状态,得到上下文向量。
与传统LSTM类似,解码器LSTM单元使用上下文向量更新隐藏状态和记忆单元状态。
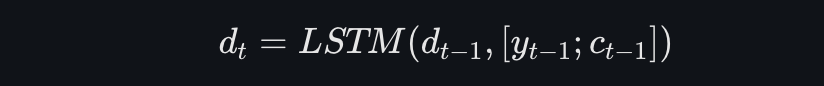
对此类非线性自回归外生模型(Nonlinear autoregressive exogenous),本文的目的是利用DA-RNN来近似 F 函数,以便在具备所有输入特征和之前的输入标签的情况下获取当前y的估计,具体可表示如下:
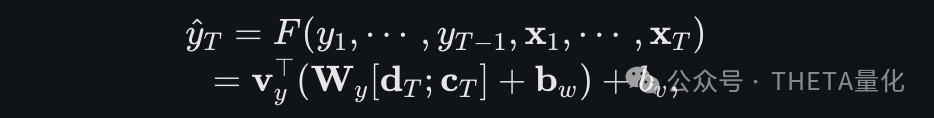
公式中 [d、c] 部分为解码器隐藏状态和上下文向量的拼接。
实验设计:
本文的实验部分通过两个公开数据集对所提出的双阶段注意力机制循环神经网络(DA-RNN)进行验证,并与多种基准方法进行比较。具体的实验步骤如下:
1. 数据集和设置
实验使用了两个不同的数据集:
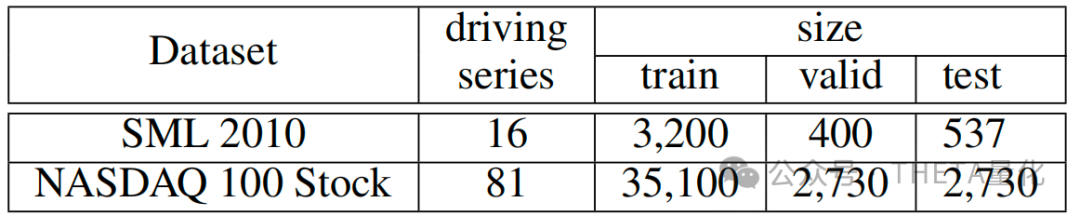
SML 2010 数据集:
-
-
- 该数据集用于室内温度预测
- 数据来自一个家庭监测系统,包含约40天的监测数据,每分钟采样一次
- 选择了16个相关的驱动序列(例如湿度、风速等)作为输入
- 数据经过平滑处理(15分钟平均)
- 分为3200个训练数据点,400个验证数据点和537个测试数据点
-
NASDAQ 100 股票数据集:
- 该数据集用于股票价格预测
- 包含NASDAQ 100指数下的81家主要公司的股价
- 数据频率为每分钟一次,覆盖从2016年7月26日到2016年12月22日的105天
- 分为35100个训练数据点,2730个验证数据点和2730个测试数据点
为了确定模型的最佳参数,作者进行了网格搜索(grid search),最终选择了窗口长度 T=10和隐藏状态的大小 m=p=64和 m=p=128。
2. 时间序列预测结果
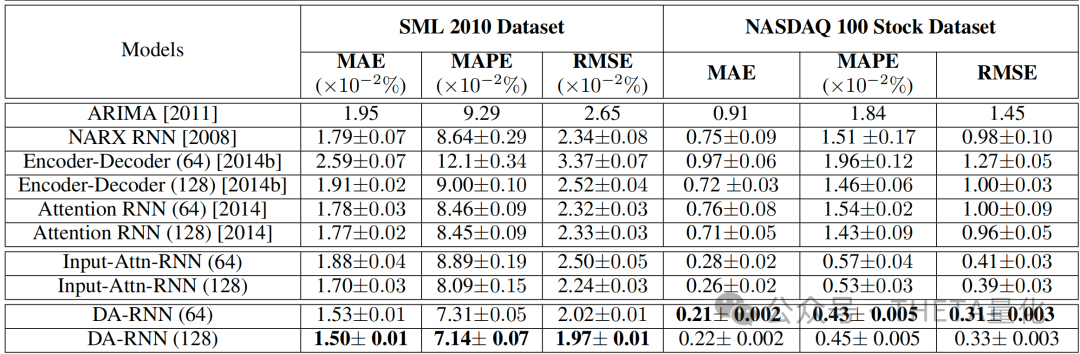
为了展示DA-RNN的有效性,本文将其与四种基准方法进行了比较:
- ARIMA模型:
- 一种传统的时间序列预测方法,只考虑目标序列的历史值,不考虑驱动序列
- NARX RNN:
- 经典的非线性自回归模型,适用于时间序列预测
- 编码器-解码器网络(Encoder-Decoder):
- 原用于机器翻译任务,这里改为时间序列预测
- 注意力RNN(Attention RNN):
- 原用于机器翻译任务,改为时间序列预测时,加入了注意力机制
此外,还进行了逐步验证:
- 仅输入注意力机制的RNN(Input-Attn-RNN):
- 只包含输入注意力机制,不包含时间注意力机制
- 双阶段注意力RNN(DA-RNN):
- 既包含输入注意力机制,也包含时间注意力机制
结果表明,DA-RNN在两个数据集上的表现均优于其他基准方法,展示了其在处理时间序列预测任务中的强大性能和鲁棒性。
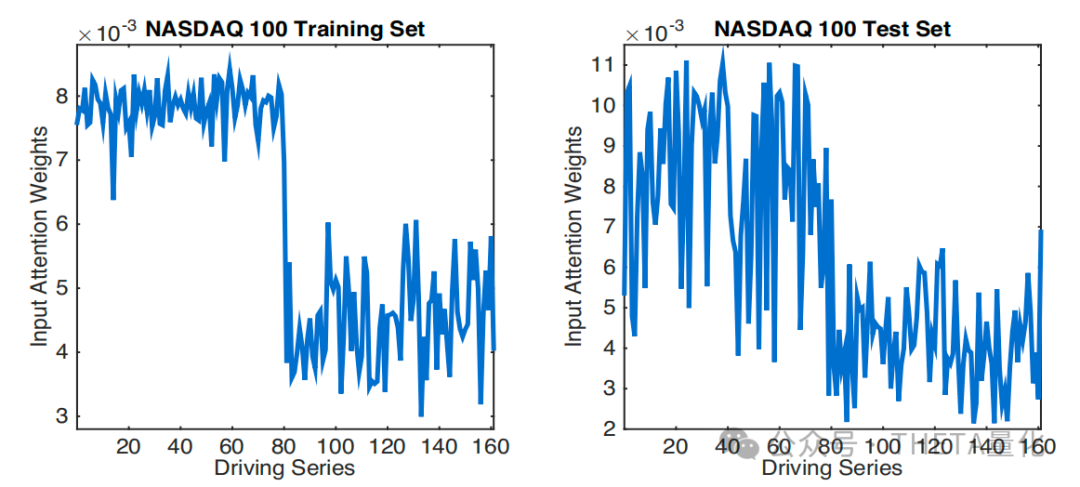
3. 结果解释
为了进一步研究输入注意力机制的有效性,作者在NASDAQ 100数据集中引入了噪声驱动序列。结果表明,DA-RNN能够自动分配较小的注意力权重给噪声序列,证明了其对噪声输入的鲁棒性。
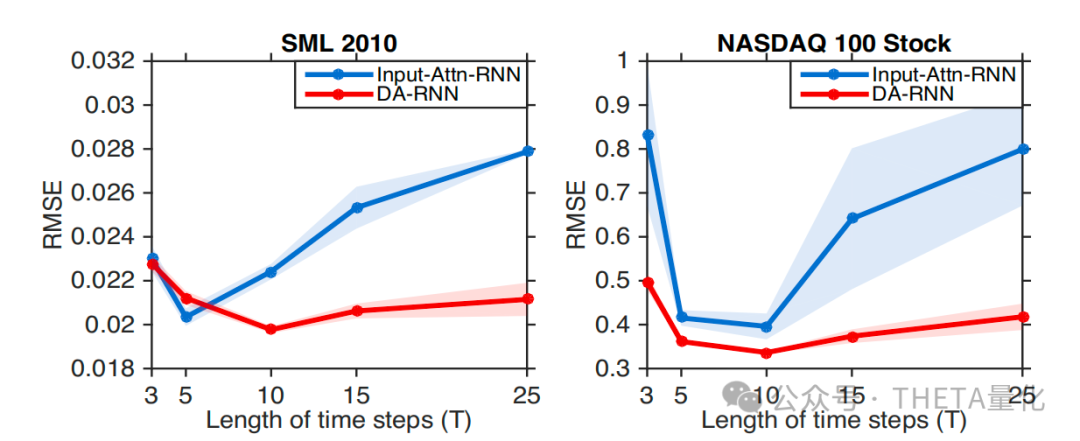
同时,为了验证时间注意力机制的有效性,作者对比了不同时间步长下DA-RNN和Input-Attn-RNN的表现。结果显示,当时间步长较大时,DA-RNN的表现显著优于仅有输入注意力机制的RNN,说明时间注意力机制能够有效捕捉长时间依赖关系。
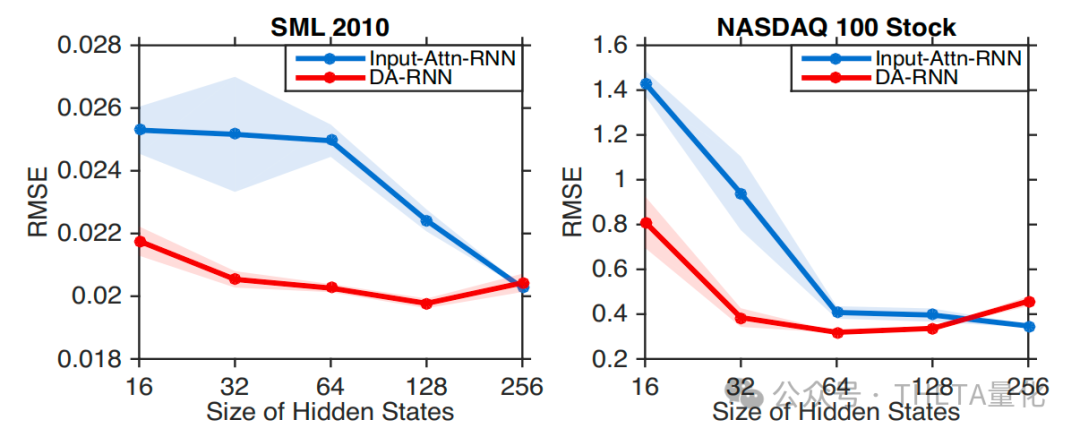
4. 参数敏感性分析
最后,作者分析了DA-RNN对不同参数设置的敏感性,包括时间步长𝑇和隐藏状态大小𝑚。实验结果表明,DA-RNN在不同参数设置下表现稳定,证明了其对参数选择的鲁棒性。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111128
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!