
1000天行动计划之第101天,开启第2个100天计划进程!
我们回到主线——backtrader。
AI量化框架的主体是backtrader的事件驱动回测以及实盘能力。外加wxPython的GUI,支持csv、hdf5,Arctic(mongo),qlib的数据存储能力——这里也会把qlib框架整合进来,但不会用它的全流程——我把它的“因子表达式”能力独立拆分出来,不依赖它自有的数据格式,可以兼容csv,hdf5,mongo等。
01 backtrader策略
为了与“向量化回测”整合:qlib的AI导向的框架与backtrader的事件驱动与实盘做对比,使用backtrader来走一下“双均线”的策略流程。
-
初始化大脑(默认是1万,可以通过broker的setcash把初始资金改为10万)
-
取初始投资组合总市值
-
运行大脑
-
取投资组合总市值
cerebro = bt.Cerebro(maxcpus=1) # 在notebook里运作,maxcpus=1很重要
cerebro.broker.setcash(100000.0) #
print('初始总市值: %.2f' % cerebro.broker.getvalue())
cerebro.run()
print('期末总市值: %.2f' % cerebro.broker.getvalue())
添加数据源,使用pandasdata
-
使用HDFStore从hdf5存储中读出数据
- 初始化为bt的格式,只需要多一列openinterest
- 使用bt.feeds.PandasData封装后,添加给大脑
import pandas as pd from datetime import datetime symbol = 'SPX' start = datetime(2010,1,1) end = datetime(2022,9,23) with pd.HDFStore('../../data/hdf5/index.h5') as store: df = store[symbol] df['openinterest'] = 0 df = df[['open', 'high', 'low', 'close', 'volume', 'openinterest']] data = bt.feeds.PandasData(dataname=df, name=symbol, fromdate=start, todate=end) cerebro.adddata(data)
双均线策略:
class SMAStrategy(bt.Strategy): def __init__(self): self.sma_short = bt.indicators.SMA(period=42) self.sma_long = bt.indicators.SMA(period=252) #self.sma = btind.SimpleMovingAverage(period=15) def next(self): #print(self.data0[0], self.sma_short[0], self.sma_long[0]) if self.sma_short[0] > self.sma_long[0]: self.buy() else: self.close()
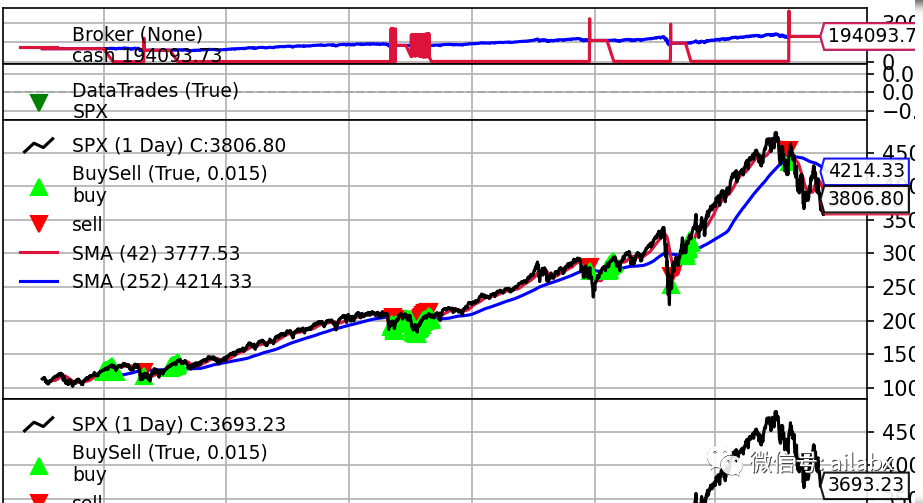

02 backtrader通用模板
# encoding:utf8 from datetime import datetime import backtrader as bt import pandas as pd from loguru import logger class BacktraderEngine: def __init__(self, init_cash=1000000.0, benchmark='000300.SH', start=datetime(2010, 1, 1), end=datetime.now().date()): self.init_cash = init_cash self.start = start self.end = end self.benchmark = benchmark cerebro = bt.Cerebro() cerebro.broker.setcash(init_cash) # 设置手续费 cerebro.broker.setcommission(0.0001) # 滑点:双边各 0.0001 cerebro.broker.set_slippage_perc(perc=0.0001) self.cerebro = cerebro self.cerebro.addanalyzer(bt.analyzers.PyFolio, _name='_PyFolio')
添加数据:
def add_data(self, code): # 加载数据 df = self.feed.get_df(code) df = to_backtrader_dataframe(df) data = bt.feeds.PandasData(dataname=df, name=code, fromdate=self.start, todate=self.end) self.cerebro.adddata(data) self.cerebro.addobserver(bt.observers.Benchmark, data=data) self.cerebro.addobserver(bt.observers.TimeReturn)
策略模板:
策略里,notify_order, notify_trade两个函数,一个是订阅提交时触发,一个是交易产生时触发,这个在策略调试时特别有用,而且是通用的,直接写在基类里,另外就是基数实现log函数
# encoding: utf8 import backtrader as bt from loguru import logger import pandas as pd class StrategyBase(bt.Strategy): def log(self, txt, dt=None): dt = dt or self.datas[0].datetime.date(0) logger.info('%s, %s' % (dt.isoformat(), txt)) def get_current_dt(self): return self.datas[0].datetime.date(0) # 打印订单日志 def notify_order(self, order): order_status = ['Created', 'Submitted', 'Accepted', 'Partial', 'Completed', 'Canceled', 'Expired', 'Margin', 'Rejected'] # 未被处理的订单 if order.status in [order.Submitted, order.Accepted]: self.log('未处理订单:订单号:%.0f, 标的: %s, 状态状态: %s' % (order.ref, order.data._name, order_status[order.status])) # 已经处理的订单 if order.status in [order.Partial, order.Completed]: if order.isbuy(): self.log( 'BUY EXECUTED, 状态: %s, 订单号:%.0f, 标的: %s, 数量: %.2f, 价格: %.2f, 成本: %.2f, 手续费 %.2f' % (order_status[order.status], # 订单状态 order.ref, # 订单编号 order.data._name, # 股票名称 order.executed.size, # 成交量 order.executed.price, # 成交价 order.executed.value, # 成交额 order.executed.comm)) # 佣金 else: # Sell self.log( 'SELL EXECUTED, status: %s, ref:%.0f, name: %s, Size: %.2f, Price: %.2f, Cost: %.2f, Comm %.2f' % (order_status[order.status], order.ref, order.data._name, order.executed.size, order.executed.price, order.executed.value, order.executed.comm)) elif order.status in [order.Canceled, order.Margin, order.Rejected, order.Expired]: # order.Margin资金不足,订单无法成交 # 订单未完成 self.log('未完成订单,订单号:%.0f, 标的 : %s, 订单状态: %s' % ( order.ref, order.data._name, order_status[order.status])) self.order = None def notify_trade(self, trade): logger.debug('trade......',trade.status) # 交易刚打开时 if trade.justopened: self.log('开仓, 标的: %s, 股数: %.2f,价格: %.2f' % ( trade.getdataname(), trade.size, trade.price)) # 交易结束 elif trade.isclosed: self.log('平仓, 标的: %s, GROSS %.2f, NET %.2f, 手续费 %.2f' % ( trade.getdataname(), trade.pnl, trade.pnlcomm, trade.commission)) # 更新交易状态 else: self.log('交易更新, 标的: %s, 仓位: %.2f,价格: %.2f' % ( trade.getdataname(), trade.size, trade.price))
这样我们在写一个新策略时,直接继承使用,代码就非常简洁:
class StrategyPickTime(StrategyBase): params = ( ('long', 252), ('short', 42), ) def __init__(self): # bt.ind.EMA(self.data, period=self.p.ema_period) self.long = bt.ind.SMA(period=self.p.long) self.short = bt.ind.SMA(period=self.p.short) def next(self): if self.short[0] > self.long[0]: self.buy() else: self.close()
运行时,可以打印出所有的日志:

03 “模块化算子”
这个才是“积木式”策略开发的精华。
我们连上面的代码都不想写,想直接从“仓库”里复用。
我们把策略逻辑拆解成:选标的、按信号筛选,排序,仓位分配等等。
先从最简单的“等权重买入并持有,每个季度动态再平衡”,这个经典的资本配置策略开始。
这里拆分成“算子”会是:
1、每个季度运行一次(含首次)
2、选标的(选择所有)
3、仓位分配(等权)
我们在策略模板的基础上,再继承实现”算子策略模板“。
传入一个算子列表,在策略next函数里,逐个执行每个algo,若遇到某个algo返回True,则本次运行结果。
class StratgeyAlgoBase(StrategyBase): def __init__(self, algo_list=None): self.algos = algo_list def next(self): context = { 'strategy': self } for algo in self.algos: if algo(context) is True: # 如果algo返回True,直接不运行,本次不调仓 return
有了这个模板,结合前面说的三个步骤:
我们不需要写代码就可以完成这个策略!
e.cerebro.addstrategy(StratgeyAlgoBase, algo_list=[ RunQuarterly(), SelectAll(), WeightEqually ])
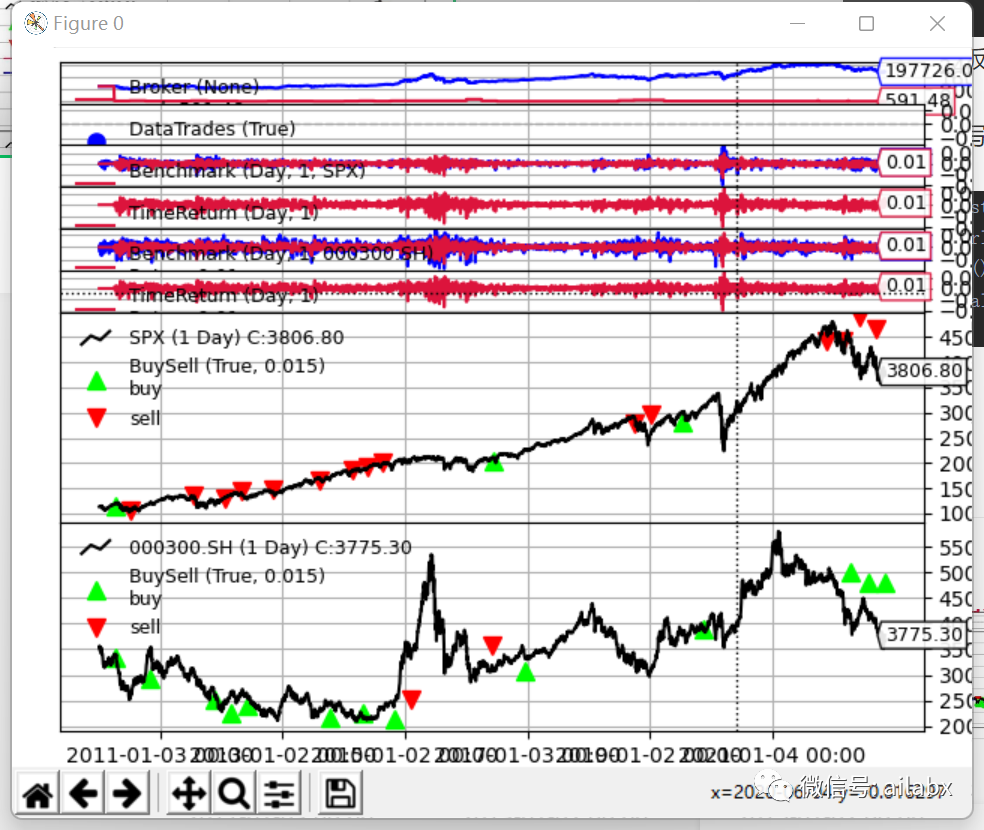
我们只需要持续封装算子库,可以最大化减少开发策略所需要的时间,把时间多多用在策略的思想上吧。
后续我们再来介绍每个“算子”如何设计。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104209
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!