
本文概述
-
论文的主要研究内容和目的: 这篇论文介绍了一个名为DeepUnifiedMom的深度学习框架,旨在通过多任务学习和多门控混合专家(Multi-Gate Mixture of Experts)的方法来增强投资组合管理。其核心在于创建统一的动量投资组合,这些投资组合能够整合不同时间框架下的时间序列动量(TSMOM)动态,这是传统动量策略中常常缺失的一个特征。
-
研究背景和在现有金融文献中的位置: 论文的研究背景基于时间序列动量(TSMOM)策略,这是一种在金融中利用资产回报随时间持续的系统性方法。这些策略通过在上升趋势中建立多头头寸,在下降趋势中建立空头头寸来利用潜在趋势的延续。TSMOM策略在金融文献中受到了广泛关注,因其在不同资产类别中展现出的稳健性和风险调整后的回报而被认为是重要的。
本文亮点
- 创新的深度学习框架:作者提出了一个多任务学习和多门控混合专家(MoMME)的深度学习框架,这在投资组合构建领域是一个新颖的方法。
- 资本分配网络(CAN):提出的资本分配网络能够为不同动量投资组合分配权重,构建最终的统一动量投资组合,是一种近来关注较多的端到端(end-to-end)网络,这种方法在风险调整回报方面显示出优越性。
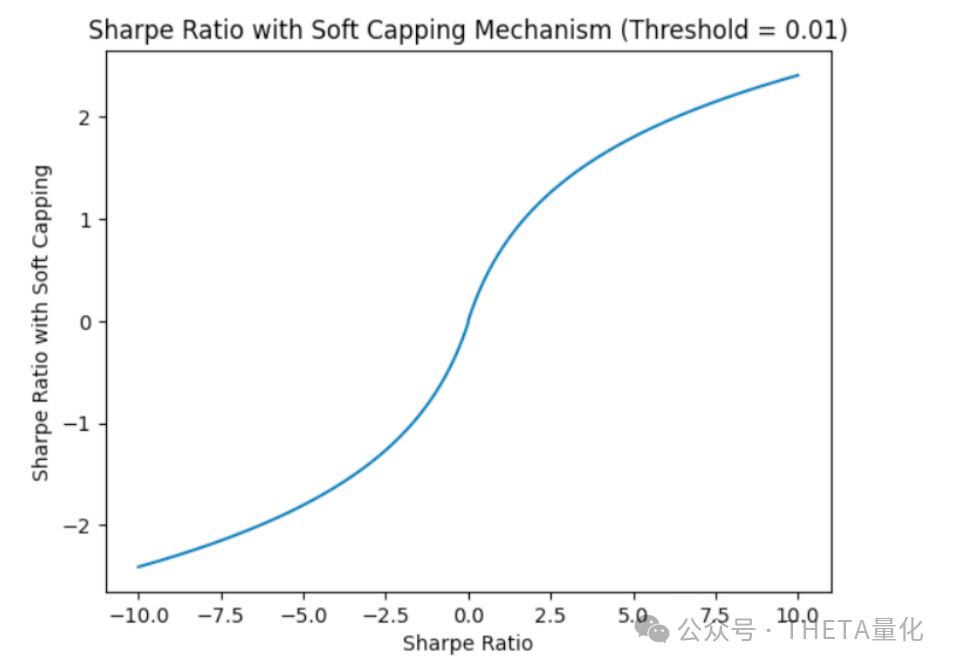
- 夏普比率软封顶机制:为了减少过拟合的风险,作者引入了夏普比率软封顶机制作为训练过程中的目标函数,这有助于模型专注于数据中更一致和可靠的模式。
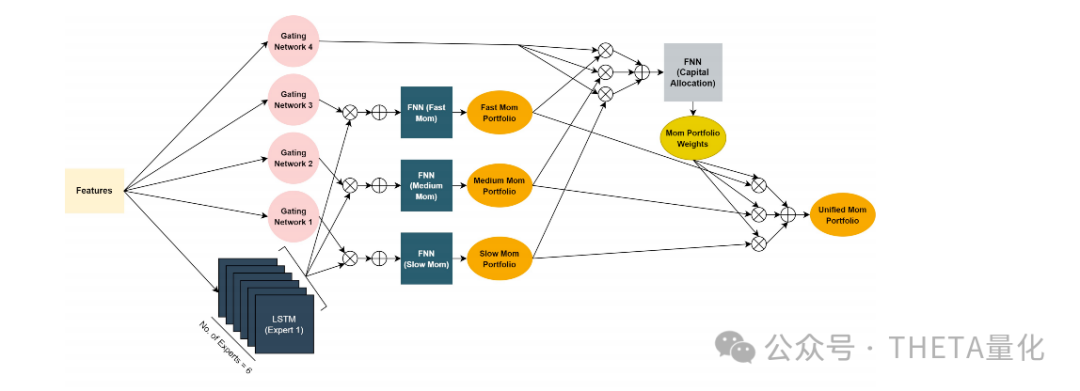
●这些LSTM单元作为多任务学习框架的核心,为不同的任务共享,以实现参数共享和学习效率的提升。
●共享的LSTM专家可以捕捉不同任务间的共性,加速训练过程,并提高模型的泛化能力。
●每个任务特定网络都有一个专用的门控网络(Gating Network),这些网络是单层前馈神经网络(FNN),具有softmax激活函数。
●门控网络接收与LSTM专家相同的输入特征,并输出一组权重,这些权重加起来等于1,决定了对相应LSTM专家的依赖程度。
●该框架允许每个任务特定网络通过门控网络选择性地激活相关的LSTM专家,从而提高特定任务网络的性能。
●这是一个任务特定网络,由门控网络支持,用于确定不同动量投资组合的权重分配。
●门控网络接收特征输入,并为每个任务特定网络的输出分配适当的权重,然后这些加权输出被送入资本分配网络。
●资本分配网络的输出作为分配给由任务特定网络生成的快速、中等和慢速动量投资组合的权重集合。
●这些权重决定了不同投资组合之间的资本分配,反映了模型对每个动量投资组合相对重要性和潜在盈利性的评估。
●符号“⊕”表示由门控网络通过LSTM专家或任务特定网络输出的加权和。
●任务特定网络的目标是最小化预测的TSMOM信号和实际前瞻性TSMOM信号之间的均方根误差(RMSE)。
●资本分配网络的训练目标是最大化夏普比率,这通过一个修改后的夏普比率目标函数来实现,该函数包括软封顶机制以减少过拟合的风险。
本文使用了Pinnacle Data Corp CLC数据库,涵盖了1990年1月至2023年12月的49种不同资产类别的期货合约的每日数据。本文未提供原始数据集,若读者想要复现需根据论文格式自行准备数据集。
●文中从连续期货合约的日常结算价格中提取了一系列包括过去不同时间段(3天、5天、10天、21天、63天、126天和252天)的对数收益率(log returns)。

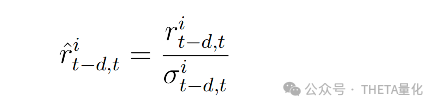
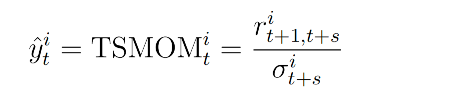
●标签是资产在未来某个时间窗口 𝑠s 的收益率,调整了其波动率。
●这是模型试图预测的目标变量,用于训练模型以识别未来的动量趋势。上述公式左侧y是资产 i 在 t 日的前瞻性时间序列动量信号,公式右侧r为 t+1 到 t+s 日的收益率,分母是该期间的波动率。
●文中将动量信号分为快速(Fast-20日动量)、中等(Medium-60日动量)和慢速(Slow-120日动量),并为每个类别训练一个特定的网络,以预测相应时间框架的动量信号。最后根据网络输出的各信号权重进行加权。
●保持特征的简洁性:作者有意限制了特征工程的复杂性,以确保投资组合的性能主要归功于模型架构的有效性,而不是来源于特征工程(高情商学到了)。
●与现有文献一致:特征的构建与Moskowitz等人(2012)在构建时间序列动量投资组合时使用的特征保持一致。
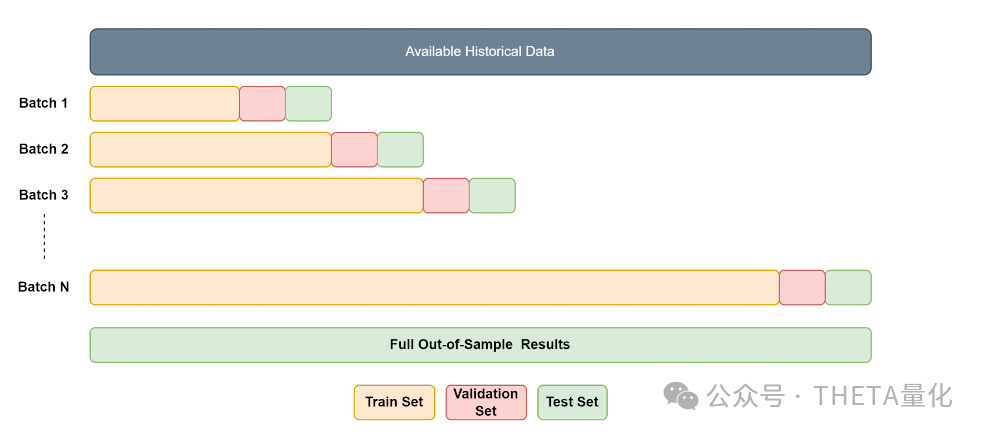
●上图为作者在模型训练过程中使用的“扩展窗口交叉验证”(Expanding Window Cross-Validation)方法。可以看到训练数据被划分为多个时间段,每个时间段用于一次模型训练。第一个训练批次涵盖了从1990年1月到1999年12月(10年)的数据。
●在每个训练批次中,20%的数据被用作验证集,以评估模型在未见过的数据上的表现,并进行超参数调整。一旦模型在训练集上训练完成,并且使用验证集进行了评估,它就会被用来构建下一个时间段的投资组合。这个过程是滚动进行的,每个新的时间周期都会包括更多的数据。
●每个训练周期结束后,模型会使用前一年的数据进行样本外测试,这意味着模型将尝试预测下一个时间周期的投资组合表现。
●这个过程从2000年1月开始,一直重复到2023年12月,从而提供了24年的样本外测试结果。这样做可以评估模型在长期内的表现,并检验其稳健性。
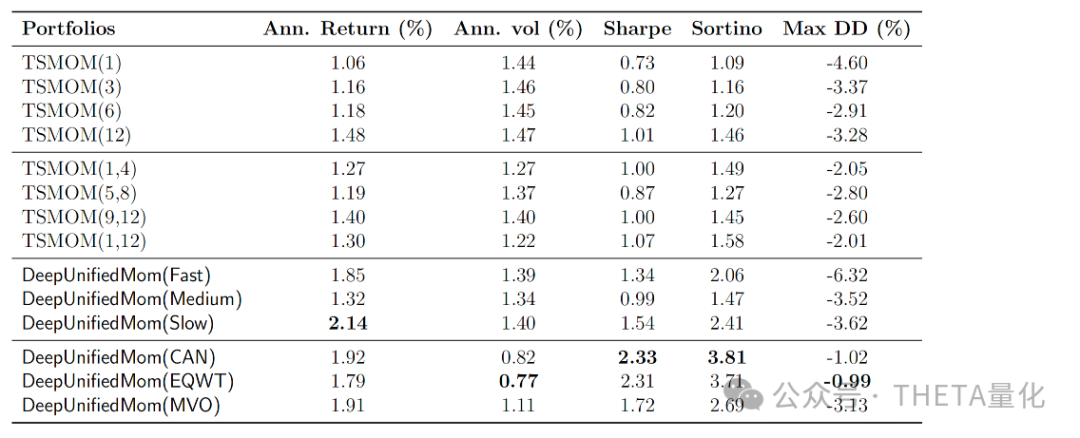
下图为从2000年1月到2023年12月期间的回测结果,考虑了3个基点的交易成本。表格列出了不同投资组合的年化回报率(Ann. Return)、年化波动率(Ann. vol)、夏普比率(Sharpe)、索提诺比率(Sortino)和最大回撤(Max DD)。
DeepUnifiedMom(CAN)的年化回报率为1.92%;夏普比率为2.33,远高于其他策略;索提诺比率为3.81,显示出其在控制下行风险方面的优势;TSMOM(1)的最大回撤为-4.60%,而DeepUnifiedMom(CAN)的最大回撤仅为-1.02%,显示出更好的风险控制能力。
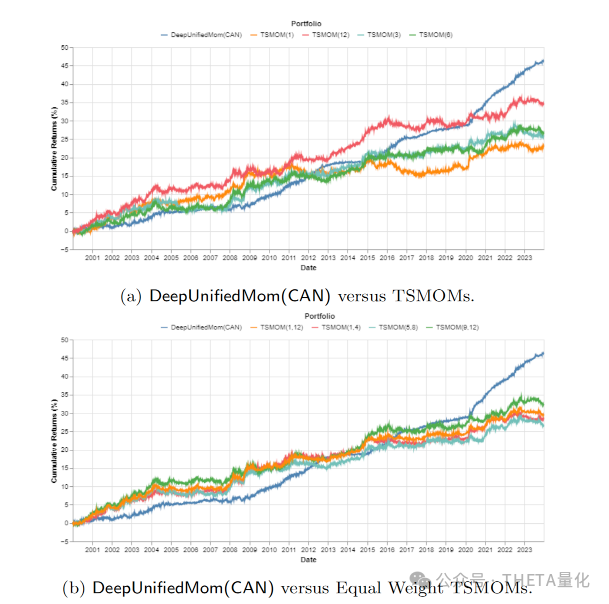
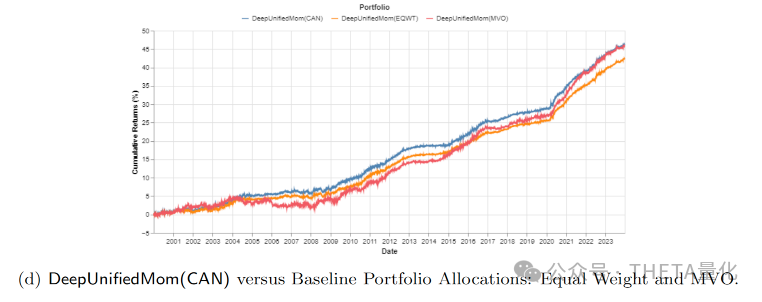
下图展示了不同投资组合从2000年1月到2023年12月的累积回报百分比。每一条曲线代表了一个不同的投资策略或模型的累积回报。

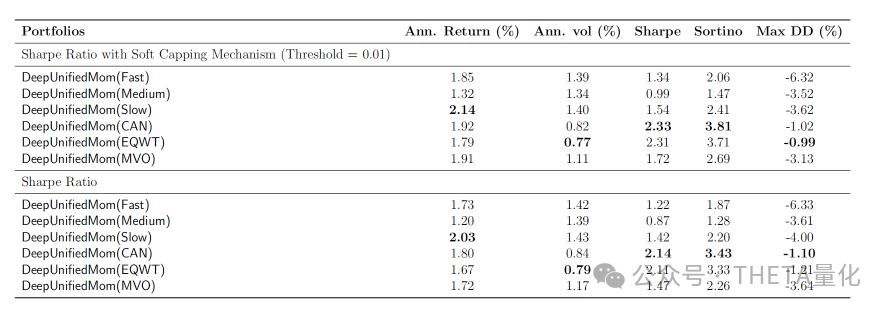
下表展示了DeepUnifiedMom模型使用不同目标函数进行训练后的回测结果。表格列出了几个不同的DeepUnifiedMom模型变体,包括Fast、Medium、Slow、CAN、EQWT和MVO。这些变体代表了不同的动量策略和资本分配方法。可以看到使用软封顶机制训练的DeepUnifiedMom(CAN)模型的夏普比率为2.33,而使用标准夏普比率训练的模型夏普比率为2.14。
表格结果表明,使用夏普比率软封顶机制训练的模型在整体性能上优于使用标准夏普比率训练的模型,表明软封顶机制有助于提高模型的稳健性。
1
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111125
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





