
一 本文简介
本文提出了一种新的方法来处理时间序列数据,这是一种按时间顺序排列的数据,比如股票价格或天气预报。以前的方法通常需要手动选择特征或设计特征来进行预测,但这样的方法很容易受到“噪声”的影响。本文提出了一种新的模型,能够更有效地处理这些噪声,并使用特殊的运算符来提取有用的信息。同时,本文还提出了一种特征编程框架,可以自动生成大量特征,提高预测的准确性。这种方法的优点是更具通用性和高效性,能够解决时间序列建模问题。实验结果显示,和基准相比,本文方法获得的模型在R2分数和Pearson相关系数均有所提高,改进的幅度在1.3%到5.85%之间。
二 背景知识
时间序列建模
时间序列建模是一项复杂的任务,因为时间序列数据通常具有高度的自相关性和非线性性,并且受到来自顺序结构的噪声敏感性的影响。这使得时间序列预测变得非常具有挑战性,尤其是在需要准确性和可解释性的领域,如金融、医疗和工业等。因此,提取有意义的特征非常关键,因为这有助于提高模型的预测准确性和可解释性。传统的方法通常是通过手工设计特征来处理时间序列数据,这需要专业知识和经验,并且很难适应不同的领域和数据类型。另一种方法是使用端到端的深度神经网络模型,这些模型可以自动学习特征,但其黑盒特性使得预测结果缺乏可解释性,并且很难发现数据中的隐藏模式和规律。
为了解决这些问题,近年来出现了许多自动化特征工程的方法,例如基于遗传算法、贝叶斯优化和深度学习的特征选择和特征生成方法。这些方法可以自动生成特征,但是如果没有基本原则的指导,它们可能会生成无用或冗余的特征,从而导致过拟合或降低模型的预测准确性。因此,需要一种基于理论原则的自动特征工程方法,可以从时间序列数据中提取有意义的特征,提高模型的预测能力和可解释性,并且适用于不同的领域和数据类型。这种方法应该能够自动发现数据中的规律和模式,同时还能够处理噪声和缺失数据等常见问题。
多变量时间序列预测
多变量时间序列预测问题是指对于一个包含多个相关变量的时间序列数据集,通过建立模型来预测未来时间步的变量值。在这个问题中,每个时间步的变量值不仅仅是单独的数值,而是由多个相关变量组成的向量。因此,需要考虑这些变量之间的相关性和相互作用,以便更好地预测未来的值。
通常,多变量时间序列预测问题包括以下步骤:
-
数据预处理:包括数据清洗、缺失值处理和数据归一化等步骤。 -
特征提取:从原始时间序列数据中提取有意义的特征,以便更好地描述变量之间的相关性和相互作用。 -
模型选择:选择适当的模型来预测未来时间步的变量值,如自回归模型、神经网络模型等。 -
参数优化:通过训练模型并对其参数进行调整来提高预测准确性。 -
模型评估:通过比较预测结果和真实值来评估模型的性能,并确定是否需要进一步改进。
Glauber Dynamics
Glauber Dynamics是一种用于时间序列数据生成的模型。它基于物理学中的自旋系统,可以描述多元时间序列的动态行为。该模型的基本思想是,将一个时间序列分成多个时间段,在每个时间段内,将时间序列的值看作自旋,并根据它们之间的相互作用建立一个自旋系统。自旋的动态行为可以通过Lagrangian函数来描述,从而可以得到一个路径积分表达式。对于连续时间极限,可以将路径积分表达式推广到连续时间上,得到一个连续模型的形式表达式。
在这个模型中,可以通过选择不同的Lagrangian函数来建立不同的时间序列模型。通过该模型可以建立一个粗粒化模型,用于描述两个时间点之间最可能的路径,并使用更细时间尺度的数据来考虑建模过程中的波动和去噪最可能的路径。此外,我们还可以使用导数数据来进一步完善模型,以更好地反映时间序列的动态行为。
三 本文贡献
本文探讨了在回归任务中自动化时间序列特征工程的问题,主要贡献可以分为以下三个部分:
-
提出了特征编程框架:本文提出了一个名为特征编程的框架,该框架允许从原始数据中自动生成有意义的特征。该框架还通过可定制的特征模板实现了领域知识的融入。这个特征编程框架以结构化和自动化的方式从时间序列数据中提取特征。 -
开发了动力学伊辛风格模型:本文开发了一种新颖的动力学伊辛模型用于时间序列数据生成。这个模型称为自旋气体格劳伯动力学,它将时间序列视为细粒度轨迹增量的累积和。这个模型提供了一种新的方法,使得特征编程框架可以从时间序列数据中自动生成有意义的特征。 -
进行了大量实验验证:本文通过对多变量时间序列预测任务的大量实验对生成的特征进行了实证验证。评估指标是预测值和真实值之间的R2分数和Pearson相关系数。此外,本文还讨论了该领域的相关工作,并计算了每个数据集的时间信噪比(TSNR),结果表明出租车数据集是最嘈杂的数据集,而本文的实验结果突出了扩展特征在处理这些嘈杂数据集方面的重要性。
四 本文方法
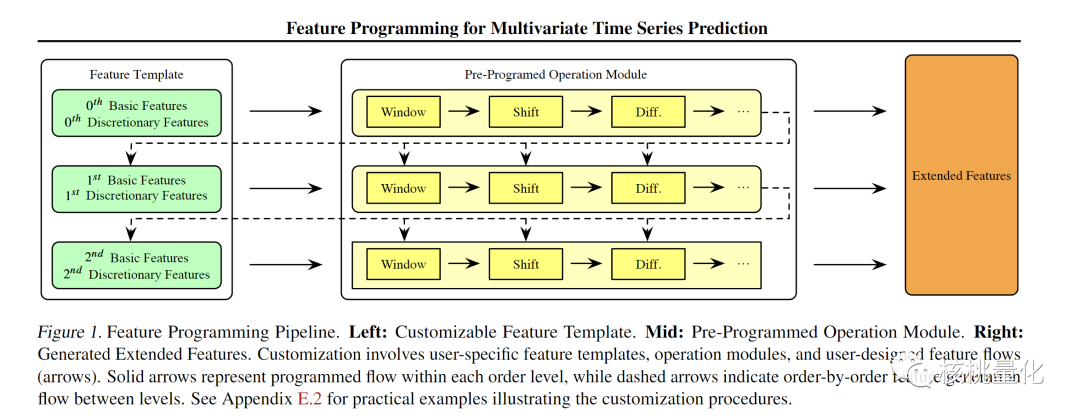
如上图所示,本文提出的特征编程框架包括三个关键组件:
• 一组可编程操作符(差分、窗口、移位),它们是生成特征的基础;
• 特征模板,使用户可以选择要使用的基本特征;
• 一个半自动的按顺序生成规则,编码在操作模块中,它会自动在每个级别和级别之间创建扩展特征,遵循升级规则。
特征程序(它会生成一组扩展特征)由用户特定的特征模板和预编程的操作模块组成。下面将介绍每个组件的作用。
可编程操作符
本文作者受到Glauber Dynamics的启发,提出了三个操作符用于从时间序列数据中提取特征:
-
差分操作符:差分操作符结合了连续和有限差分,并对任意两个系列执行系列差分。在操作方面,我们定义了差分操作符Difference[series1,series2],它执行首先平滑处理,然后减去两个输入序列(基本特征)的广义导数操作,并生成类似于物理学中的动量和加速度的曲率特征。通过差分操作符,我们将特征(基本和扩展)分成三个层次的类别,基于它们的导数阶数:0阶,1阶和2阶特征,分别对应于输入原始特征x_i,t的广义位置、动量和加速度的概念。 -
窗口操作符:窗口操作符使用经过去噪的统计数据(如最大值、最小值和平均值)从多个固定窗口的汇总信息。在操作上,窗口操作符Window[series,lookback size]被定义为一个函数,它接受输入系列和回溯大小,对于每个窗口,随后输出给定回溯窗口的汇总信息。通过使用不同的回溯大小应用窗口操作符,可以从输入系列的时间重新缩放特性中推导出信息丰富的特征。 -
移位操作符:移位操作符可以从任何现有系列创建具有任意时间差异的新系列,以补充其他操作符。移位操作符Shift[series,∆τ]允许将输入系列按任意所需的时间差异移动,以加入更多的自相关信息。
通过上述的差分操作符,我们可以通过将其应用于低阶特征来生成更高阶的特征。窗口和移位操作符可以用于从这些高阶特征创建汇总特征。例如可以通过将差分操作符应用于两个0阶特征来创建1阶系列,并通过将差分操作符应用于两个1阶系列来创建2阶系列。应用窗口和移位操作符于这些高阶系列可以创建汇总特征,而不改变系列的阶数。
特征模板
特征模板是特征编程框架的重要组成部分,它是特征生成过程的起点。特征模板包含三个基本系列列表,分别对应于特征的每个阶数(0阶、1阶和2阶),如图1中的绿色框所示。这些列表由一组基本特征和可自定义添加的手工制作特征的组合初始化,这些基本特征是从原始数据中提取出来的。随着特征生成过程的进行,这些列表会从前一个阶数中更新新特征,如图1中的虚线箭头所示。这种设计允许高度的灵活性和定制性,因为基本系列列表可以完全随意、完全默认或两者的组合。此外,基本系列列表被输入到预编程的操作符中以生成扩展特征(如图1中的实线箭头),使得在每个阶数的基本系列列表的设置是特征生成过程中的关键步骤。
自动按序生成特征
通过特征模板和可编程操作符,我们可以半自动地生成扩展特征,控制流程进入操作模块。我们从特征模板中指定的基本系列列表开始,将每个列表输入到包含预编程操作符的操作模块中。这个过程是按顺序进行的,对于每个阶数,该阶数的每个基本系列列表都会被相应阶数的操作符在模块中操作。这导致了一个分层的特征生成,它自动地在每个级别和级别之间生成扩展特征,遵循升级规则。通过操作模块中操作符的组合操作和计算流程(由箭头表示),我们的特征编程框架使得扩展特征可以从基本特征自动和可编程地生成。
特征生成示例
-
动量特征是时间序列中最简单常见的手工制作特征之一,它可以用来衡量时间序列在指定时间段内的变化率,通常用于识别预期继续沿着相同方向移动的趋势时间序列。在特征编程框架中,我们可以通过设置特定的特征模板和操作模块来实现类似于动量特征的功能。具体地说,我们可以使用Shift和Difference操作来计算序列的变化,并使用Ratio操作来计算变化的百分比。这些操作可以在特征编程框架中预先编程。 -
偏差特征是用来衡量时间序列当前趋势和潜在反转的一种手工制作特征。偏差特征的计算需要用到样本移动平均线,可以通过设置特定的特征模板和操作模块来实现类似偏差特征的功能。具体地说,我们可以使用Difference操作来计算序列与移动平均值之间的差,然后使用Ratio操作来计算差值与移动平均值的比例。这些操作可以在特征编程框架中预先编程,以实现对Bias[t,∆τ]的精确重现。这个过程可以帮助我们更好地理解和利用手工制作特征,并在需要时自定义和调整特征。 -
绝对能量特征是一种常用于信号处理,特别是用于识别信号能量内容的手工制作特征。在时间序列分析中,它也可以用于了解数据的整体强度或大小。绝对能量特征的计算需要对序列进行平方运算并求和。为了实现类似于AbsEnergy[t,∆τ]的特征,我们可以使用特征编程框架来设置特定的特征模板和操作模块。具体地说,我们可以将平方特征和求和特征分别包含在0级和1级基础特征中。然后,我们可以使用预编程的操作模块将平方特征传递给1级基础特征,并计算序列的和。这个过程可以帮助我们更好地理解和利用手工制作特征,并在需要时自定义和调整特征。
五 实验分析
这篇论文使用了四个监督回归数据集来测试所提出的框架。其中一个是合成数据集,用于验证方法的有效性,其余三个是真实数据集,包括出租车数据集、电力数据集和交通数据集。实验中,本文使用特征编程生成了45个扩展特征,并使用了平滑、差分和移位等操作符来处理数据噪声。评估指标是预测值和真实值之间的R2分数和Pearson相关系数。此外,本文计算了每个数据集的时间信噪比(TSNR),结果表明出租车数据集是最嘈杂的数据集,而本文的实验结果突出了扩展特征在处理这些嘈杂数据集方面的重要性。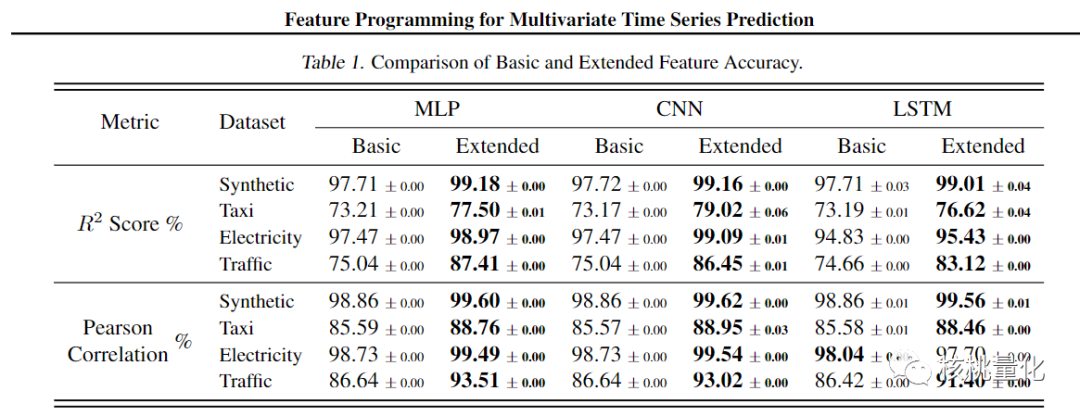
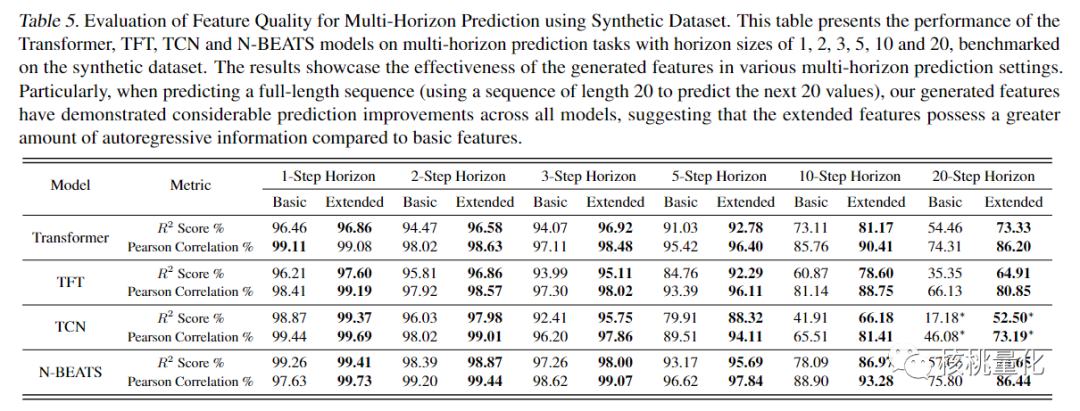
实验结果表明,在多变量时间序列预测模型中加入扩展特征后,R2分数和Pearson相关系数均有所提高。改进的幅度在1.3%到5.85%之间,具体取决于特定数据集和使用的模型。即使在最具挑战性的数据集(出租车数据集)中,加入扩展特征也显著提高了MLP/CNN/LSTM模型的性能。此外,特征生成的计算时间可以忽略不计,与训练下游模型所花费的时间相比较小。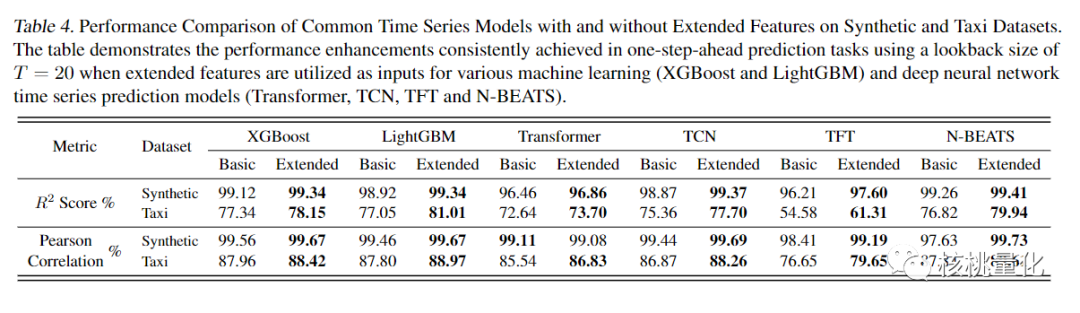
六 总结展望
本文提出了一种名为“特征编程”的方法,可以自动为多元时间序列建模生成特征。使用特征编程生成的特征,在理论和实证方面都可以有效地改善各种情况下的嘈杂多元时间序列预测。作者指出,特征编程的灵活性很高,但不包括除用户特定程序以外的任何特征选择或修剪机制。这意味着用户需要自己选择和调整输入的特征,以便获得最佳的预测结果。未来的研究方向是将特征选择机制整合到特征编程中以进一步提高预测精度和可解释性。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111121
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





