
Ensemble PyTorch 是什么
集成学习通过组合多个模型来帮助提高机器学习结果。与单一模型相比,这种方法可以产生更好的预测性能。基本思想是学习一组分类器(专家)并让他们投票。
Ensemble PyTorch 是 PyTorch实现的集成学习框架,可轻松提高深度学习模型的性能和稳健性。它具有以下的优点:
-
提高深度学习模型性能和稳健性的简单方法。 -
用于训练和评估集成的易于使用的 API。 -
并行化训练效率高。
Ensemble PyTorch 支持的算法
Ensemble-PyTorch中支持下面几种集成方法:
-
Fusion(融合):使用所有基估计器的平均输出作为最终输出。 -
投票和Bagging:独立训练多个基估计器,并将它们的预测结果进行平均。Bagging在每个数据批次上使用有放回抽样。 -
Gradient Boosting(梯度提升):顺序训练基估计器,每个基估计器的学习目标与之前拟合的基估计器的输出相关。基于负梯度更新基估计器的参数。 -
Snapshot Ensemble(快照集成):通过将单个基估计器收敛到不同的局部最小值多次生成集成。使用循环退火调度训练基估计器,将快照的预测结果进行平均。 -
Adversarial Training(对抗训练):使用对抗样本来改进基估计器的性能。每个基估计器独立训练,并使用快速梯度符号方法生成对抗样本。基于原始样本和对抗样本的训练损失来优化基估计器的参数。 -
Fast Geometric Ensemble(快速几何集成):使用自定义的学习率调度程序生成基估计器,类似于快照集成。该方法受到深度神经网络损失曲面的几何洞察的启发。
Ensemble PyTorch安装使用
使用pip进行安装
nbsp;pip install torchensemble
使用Mnist数据集进行分类集成模型训练
import torch
import torch.nn as nn
from torch.nn import functional as F
from torchvision import datasets, transforms
from torchensemble import VotingClassifier
from torchensemble.utils.logging import set_logger
# Define Your Base Estimator
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.linear1 = nn.Linear(784, 128)
self.linear2 = nn.Linear(128, 128)
self.linear3 = nn.Linear(128, 10)
def forward(self, data):
data = data.view(data.size(0), -1)
output = F.relu(self.linear1(data))
output = F.relu(self.linear2(output))
output = self.linear3(output)
return output
# Load MNIST dataset
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train = datasets.MNIST('../Dataset', train=True, download=True, transform=transform)
test = datasets.MNIST('../Dataset', train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train, batch_size=128, shuffle=True)
test_loader = torch.utils.data.DataLoader(test, batch_size=128, shuffle=True)
# Set the Logger
logger = set_logger('classification_mnist_mlp')
# Define the ensemble
model = VotingClassifier(
estimator=MLP,
n_estimators=10,
cuda=True,
)
# Set the criterion
criterion = nn.CrossEntropyLoss()
model.set_criterion(criterion)
# Set the optimizer
model.set_optimizer('Adam', lr=1e-3, weight_decay=5e-4)
# Train and Evaluate
model.fit(
train_loader,
epochs=50,
test_loader=test_loader,
)
实验结果
如下图,在MNIST数据集上,单个LeNet-5估计器的测试准确率超过99%。在这种情况下,投票和Bagging是最有效的集成方法。Bagging比投票更好,因为它通过对训练数据进行自助采样来增加集成的多样性。然而,融合方法在这种情况下表现不佳,可能是因为单个LeNet-5估计器的模型复杂度已经足够应对MNIST数据集,简单地将它们封装到一个大模型中只会加剧过拟合问题。因此,对于MNIST数据集,更好的选择是使用Bagging或投票来提高性能和鲁棒性。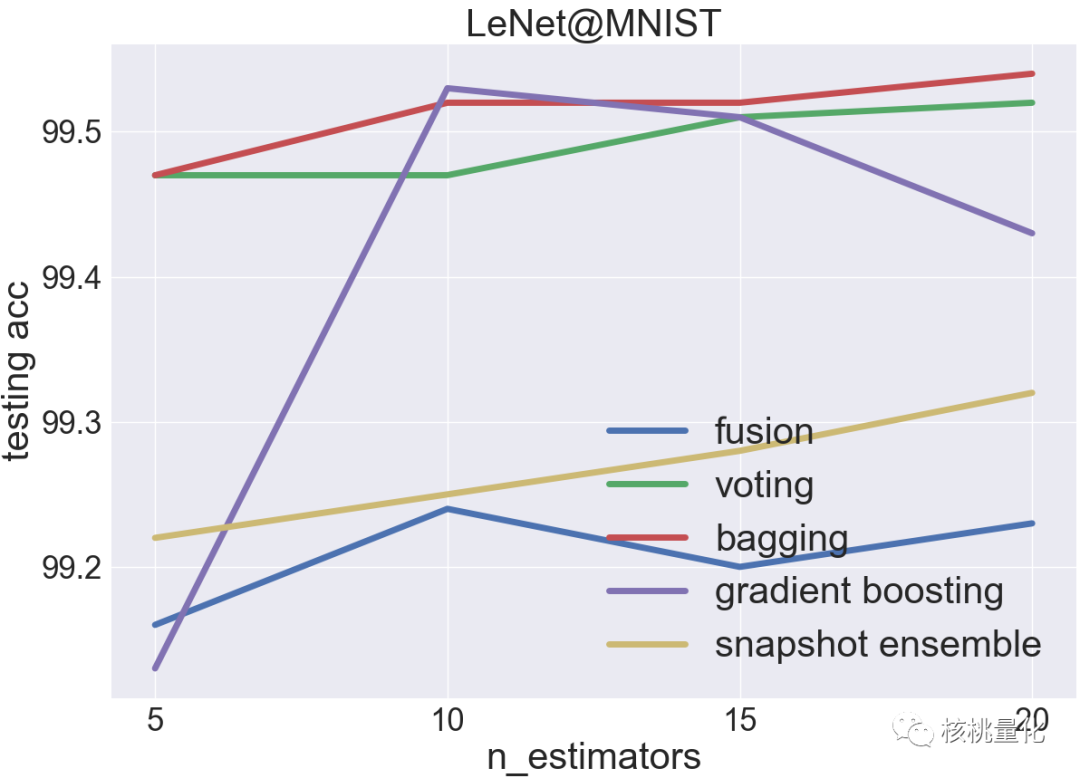
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111110
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





