
在机器学习中,优化模型是一个关键的任务,我们希望通过调整模型参数来最小化损失函数。通常情况下,我们会使用梯度下降等优化算法来进行参数更新。然而,如果我们的损失函数是非凸函数,那么模型的收敛可能会受到一些挑战。非凸函数具有多个局部最小值,这意味着在优化过程中,我们可能会陷入局部最小值而错过全局最小值。这会导致模型无法达到最优状态,无法收敛到最佳的参数值。本文将探讨凸函数和非凸函数的含义以及它们在机器学习中的重要性。
一. 函数的最小值或最大值
函数的最大值和最小值分别指函数图像上的最高点和最低点。从数学角度来说,我们可以通过对函数求导并将导数置零来找到函数的最大值和最小值。导数等于零的点被称为临界点。然后我们分析这些临界点附近的函数行为,以确定它们是最大值还是最小值。为了对凸函数和非凸函数有一个良好的理解,理解局部最小值、全局最小值和鞍点等概念至关重要。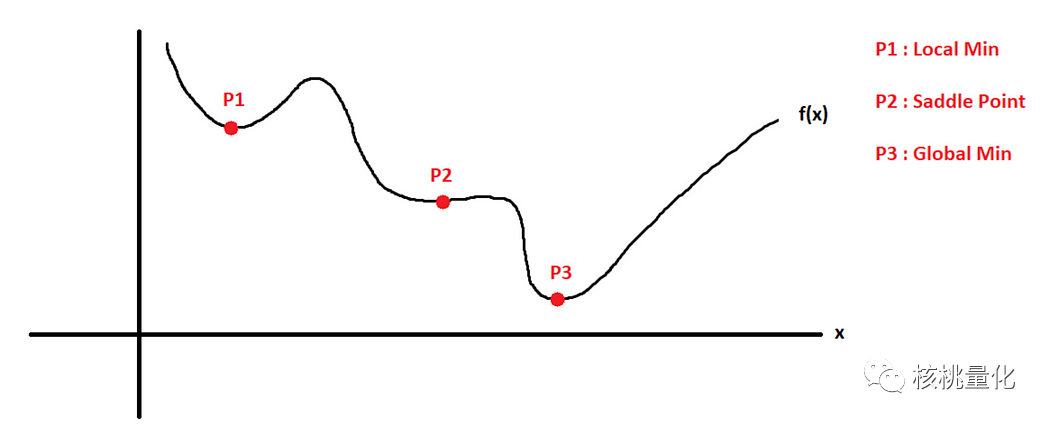

局部最小值
局部最小值指优化算法在参数空间的某个小区域内找到对应于损失函数最小值的一组模型参数的情况。然而,这个最小值可能不是损失函数的全局最小值,全局最小值是指在整个参数空间内损失函数的最小值。
全局最小值
全局最小值是损失函数的绝对最低点,对应于模型的最佳参数集。任何优化算法的目标都是找到全局最小值,以产生给定问题的最佳结果。
鞍点
鞍点是参数空间中的一个点,损失函数在一个方向上具有最小值,在另一个方向上具有最大值。在鞍点处,损失函数的梯度为零,这意味着优化算法可能会陷入困境,无法收敛到全局最小值。鞍点对于优化算法来说可能是有问题的,已经提出了各种方法来处理鞍点,例如基于动量的方法和随机梯度下降。
二. 损失最小化
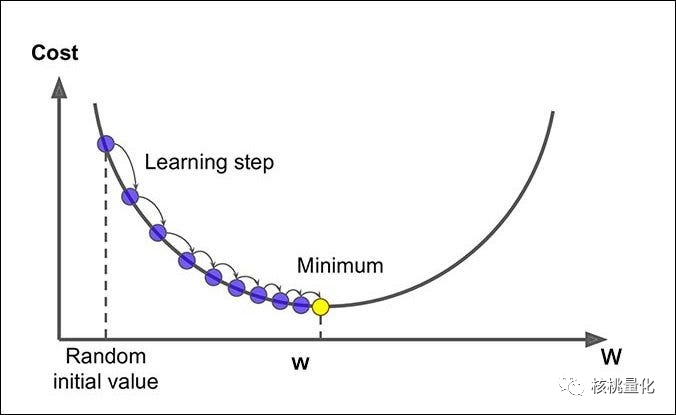
损失最小化是机器学习中一个重要的目标,它涉及调整模型的参数以减小模型的误差或损失。在机器学习中,我们使用损失函数来衡量模型的预测输出与实际输出之间的差异。通过最小化损失函数,我们可以提高模型的准确性和性能。
为了实现损失最小化,我们使用优化算法来迭代地调整模型的参数。最常用的优化算法之一是梯度下降,它通过计算损失函数关于参数的梯度来确定参数的更新方向,并沿着梯度的反方向更新参数。通过多次迭代和参数更新,我们可以逐渐降低损失函数的值,从而实现损失最小化的目标。
在选择优化算法时,我们需要考虑损失函数的性质。如果损失函数是凸函数,意味着它只有一个全局最小值,没有局部最小值。这样的情况下,我们可以使用较简单的优化算法,因为它们可以保证找到全局最小值。但如果损失函数是非凸函数,它可能同时具有多个局部最小值和鞍点,那么我们需要使用更复杂的优化算法来找到全局最小值。
通过损失最小化,我们能够找到最佳的模型参数,从而使机器学习模型更准确地进行预测和分类。这对于解决实际问题、改善模型性能以及推动机器学习的应用具有重要意义。因此,在机器学习中,损失最小化是一个核心概念,值得我们深入理解和研究。
三. 凸函数
凸函数在机器学习中非常重要,因为它们具有特殊的全局最小值。这意味着当我们要优化一个凸函数时,我们可以确定通过寻找函数的最小值来找到最佳解决方案。这使得优化过程更加容易和可靠。
从直观上看,凸函数的图像呈现出一种向上弯曲的碗形。这意味着函数图像上任意两点之间的连线都位于函数图像的上方或者正好在函数图像上,而不会在下方。这种凸形状的特点保证了函数只有一个全局最小值,没有局部最小值,这使得优化问题更加简化。我们可以通过想象一个碗形曲线来更直观地理解凸函数的性质。在这个曲线上,函数的值随着我们离开碗底而增加。这种曲率确保了只有一个全局最小值,而没有其他局部最小值,从而使得优化过程更加简单。

在机器学习中,许多常见的损失函数都是凸函数,包括L2损失、对数损失以及L1和L2正则化等。因此,凸函数在机器学习中具有重要作用。它们的凸性质确保了全局最小值的存在性和唯一性,使得我们能够更轻松地找到最佳解决方案。这为机器学习问题的优化提供了可靠的基础。
四. 非凸函数
非凸函数是指不满足凸性质的函数。从几何的角度来看,非凸函数的图像呈现出向下弯曲或者具有多个峰和谷的形状。非凸函数面临的挑战在于可能存在多个局部最小值,即函数值低于其相邻点的点。这意味着当我们尝试优化非凸函数时,可能会陷入局部最小值,错过全局最小值,而全局最小值正是我们所寻求的最优解。
从更数学的角度来看,如果对于函数f(x)的定义域中的任意两个点x1和x2以及范围[0,1]中的任意t,以下条件成立,则函数f(x)是非凸的:
f(tx1 + (1-t)x2) > tf(x1) + (1-t)f(x2)
让我们用一个简单的例子来理解上述表述。想象一个函数,其中间有一座像钟形曲线一样的“山”。如果我们选择山的两侧不同点,这些点之间的连线将在某个点与山相交。现在,如果函数在该交点处的高度小于与该点处连线的高度,则该函数是非凸的。这意味着函数上存在一些点,其中曲线下降到连接其他两个点的直线下方。这就是函数中出现丘陵和山谷的原因,并且这使得寻找全局最小值变得更加困难。
许多常见的损失函数也是非凸函数,包括二元或分类交叉熵损失函数以及在生成模型中使用的对抗性损失函数。因此,非凸函数在机器学习中具有挑战性。它们的非凸性质导致存在多个局部最小值,这增加了优化过程中找到全局最小值的难度。解决非凸优化问题需要使用更复杂的算法和策略。
五. 总结
凸函数和非凸函数是机器学习中的重要概念,尤其在优化问题中起着关键作用。凸函数具有独特的全局最小值,使得优化问题更容易和可靠。而非凸函数则可能存在多个局部最小值,使得优化问题更具挑战性。当我们处理非凸函数时,选择合适的优化算法非常重要,这可以帮助我们避免陷入局部最小值。例如,使用随机初始化和退火的梯度下降算法,即使在非凸优化问题中,也能够帮助我们找到好的解决方案。
了解凸函数和非凸函数之间的区别对于希望在机器学习中高效可靠地优化函数的从业者来说至关重要。凸函数的全局最小值特性使得优化问题更加直观和可行,而非凸函数的多个局部最小值则需要更复杂的算法和策略来解决。通过选择合适的优化方法,我们可以更好地处理非凸函数并找到最佳解决方案。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111109
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!