
一. 为什么需要元标注
元标注(Meta-Labeling)尝试通过增加辅助模型的方法来过滤错误的预测以达到改善模型和策略性能指标的目的。实验部分展示,在标普500上使用元标注,策略的年化收益由17.7%提升到35.3%,最大回撤由61.9%降低到36.8%。
金融任务中的一个普遍现象是我们往往知道是否要买卖某一特定的资产,但是不确定应该买卖多少。确定仓位方向的模型可能并不是确定该仓位大小的最佳模型。仓位大小可能应该是模型最近表现的一个函数,而模型最近表现与预测仓位方向无关。因此拥有一个良好的选择下注大小 的模型是非常重要的。考虑一种精确率为60%、召回率为90%的投资策略。90%的召回率意味着,在100个真实投资机会中,该策略可以预测出其中的90个。60%的精确率意味着,在该策略产生的100个预测的机会中,有60个预测是正确的。如果对60个真阳性的下注规模较小,而对40个假阳性的下注规模较大,那么策略将是赔钱的。作为投资者,我们没有办法控制价格,我们能够而且必须做出的关键决定是,如何适当地下注。
元标注的目的是在一个主模型的预测结果上训练一个辅助模型。辅助模型并不预测方向。相反,辅助模型预测的是主模型在某一特定预测(元预测)上是成功(元标注为1)的还是失败(元标注为0)的。元标注可用于避免或减少投资者遭受假阳性的风险。它通过放弃一些召回率以换取更高的精确率。例如在上面的示例中,添加元标注也许可以使召回率达到70%、精确率达到70%,从而提高该模型的F1 Score(查准率和召回率的调和平均数)。
二. 如何使用元标注
我们首先先利用了一个常见的机器学习分类问题(MNIST手写数字图片分类)来更清楚地说明构成元标注的组件。
在二分类问题中,精确率衡量模型做出的预测中有多少是正确的,召回率度量了数据集中存在的正类样本中有多少被模型正确识别。一种度量标准是以另一种度量标准为代价的,更高的精确度需要一个更严厉的分类器,甚至怀疑数据集中实际的阳性样本,从而降低召回率。另一方面,更高的召回率需要一个宽松的分类器,允许任何类似于阳性类别的样本通过,这使得边界情况下的阴性样本被归类为“阳性”,但是回降低了精确度。理想情况下,我们希望最大化精确度和召回率指标,以获得完美的分类器。
F1 Score使用调和平均值结合了精确度和召回率,最大化F1 Score意味着同时最大化精确度和召回率。因此,F1评分已成为研究人员结合准确性评估其模型的选择。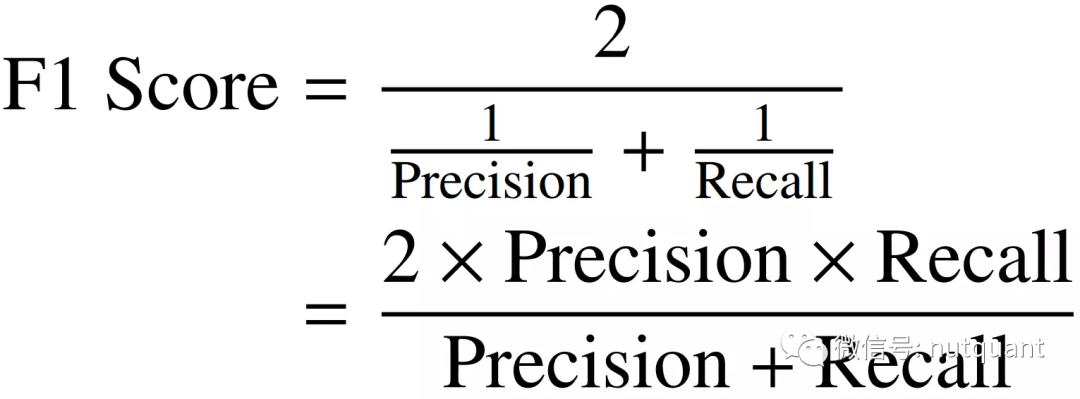
当你想获得更高的F1分数时,元标注特别有用。首先,我们构建一个精确率不是特别高但是召回率较高的模型,然后通过对主要模型预测的阳性结果应用元标注来提高精确率。
为了说明这个概念,我们利用MNIST数据集来训练二元分类器从仅包括数字3和5的集合中识别数字3。其原因是数字3看起来与5非常相似,我们预计数据中会有一些重叠,即数据不是线性可分的。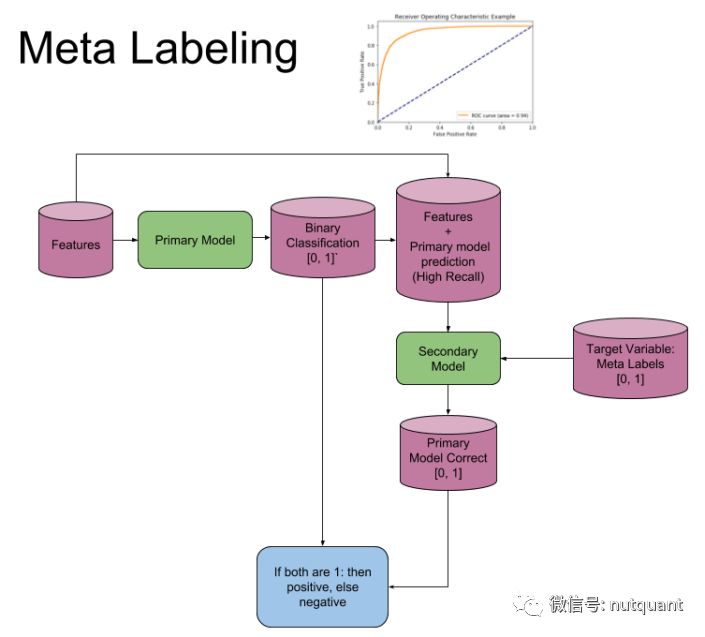
上图是使用的模型体系结,具体步骤如下:
第一步:训练具有高召回率的主要模型(二元分类器)。
第二步:确定主要模型具有高召回率的阈值水平,ROC曲线可用于帮助确定。
第三步,将第一模型输入的特征和第一模型的预测结果拼接在一起,构成辅助模型的特征集。使用元标注作为辅助模型Label,并训练第二个模型。
第四步,将来自辅助模型的预测与来自主要模型的预测相结合,只有在两者都为真的情况下,才判断最终预测为真。也就是说,如果主模型预测了3,而辅助模型判断主模型预测是正确的,那最终的预测结果是3, 否则就是5。
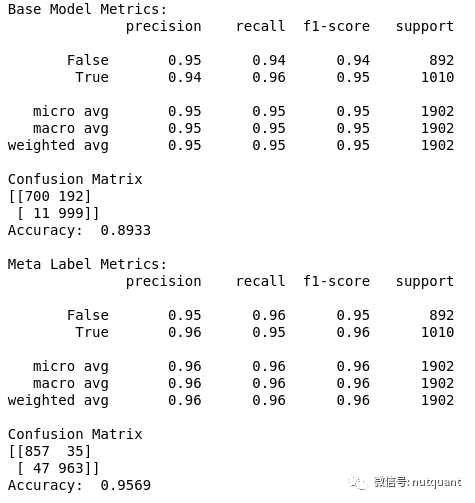
下面表格对比了MNIST数据集分类任务使用元标注方法前后的性能,可以看到各个指标性能均有提升。
三. 使用元标注改善交易策略
参考文献[2]尝试在标普500上训练模型来分析元标注方法在金融市场上的效果。在验证数据中,模型准确率从0.2增长到0.77,正确交易的精度也从0.21增长到0.39。在测试集上使用了布林线均值回归策略策略进行测试,可以发现使用元标注之后,策略的年化回报,夏普,最大回撤等各项指标均有较大改善。
四. 总结展望
元标注并不是一种具体的算法,它是一种解决问题的方法。在金融预测任务中,我们并不需要将所有都预测准确,只需要将我们下注的预测准备就可以保证策略的收益。本文展示的元标注使用方法只是示例,在具体的任务中可以进行合适的拓展改造,是可以获得更高的性能提升的。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/110943
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





