
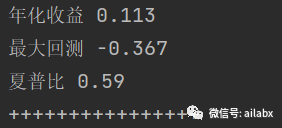
星球里同学们有一些反馈,关注说策略的夏普比以及实盘的问题。
其实我之前说过,我们的目标肯定是要实盘。但实盘不是指一个策略。
没有永远有效的策略,更没有永远有效的因子。而是你的策略可以尽可能的,大概率的捕捉市场的变化,顺势而变,顺势而为。
因为我们一开始花更多的时间,搭建一个体系化的架子很重要,而不是编一个看起来夏普比很高的策略——事实上这有点不负责任。
另外,策略的好坏一定程度上因了而异的,有人对于波动,回撤没那么敏感,有人可以做好自己的止盈止损。
到目前,我们的框架实现了几个小目标:
1、支持csv/hdf5本地数据存储;
2、支持“因子”表达式,可以快速计算几百个特征,包含所有的ta-lib指标, numpy, pandas里的函数。
3、一个简洁的回测系统,支持“积木式策略”开发,一个策略我把它们拆成不同的部分,尽量让这里子部分通用化,像搭积木一样开始。
4、兼容传统规则型量化,机器学习——集成学习(lightGBM, xgboost等),深度强化学习(stable-baseline3)——当前正在折腾的。
代码都是完全开源了,其实希望大家读懂细节,然后可以发挥自己的策略。我的开源项目及知识星球——而不是等一个所谓高夏普的策略,尽管时不常我们会提供一个。
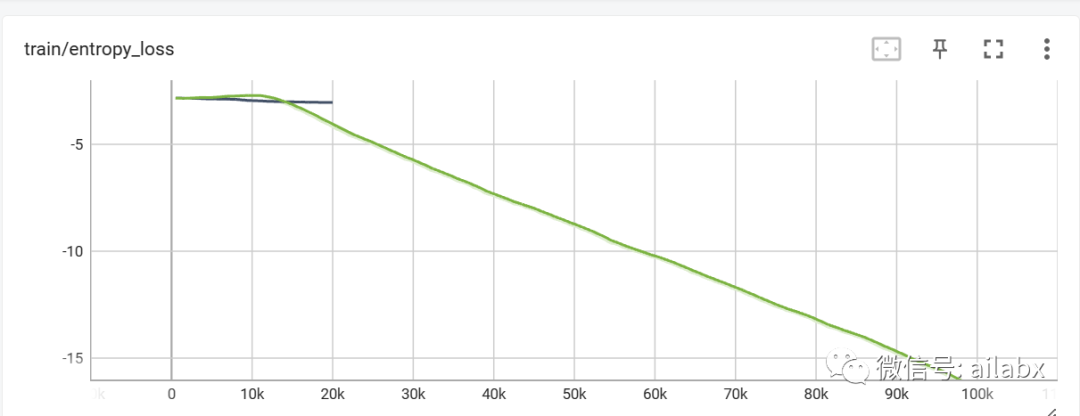
强化学习产生的训练数据记录:

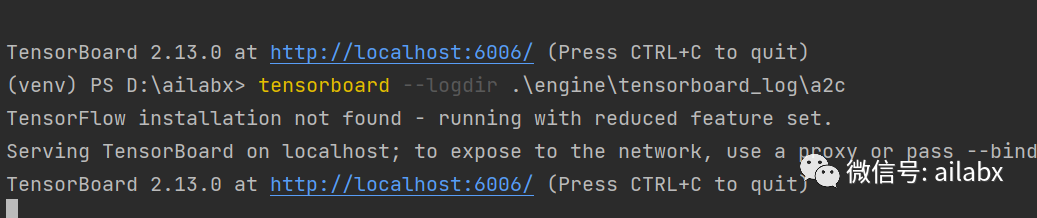
使用tensorboard –logdir .\engine\tensorboard_log\a2c启动tensorboard查看训练记录。
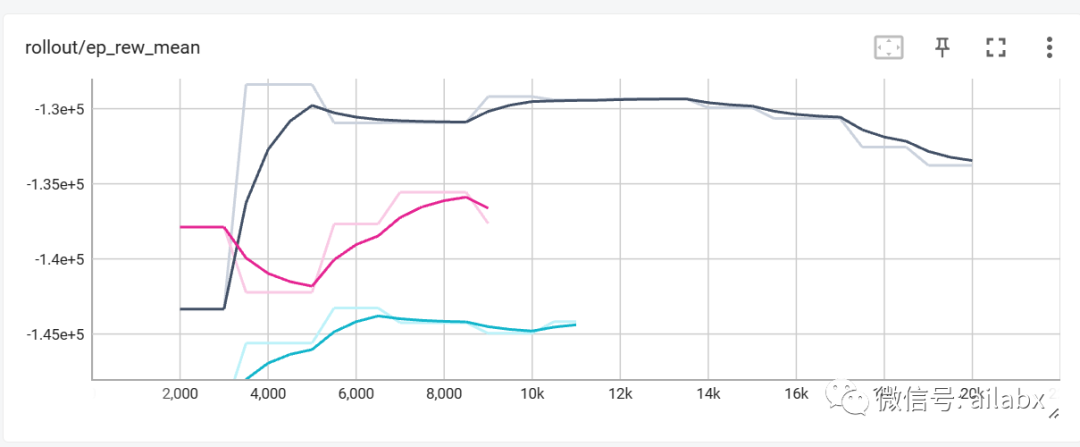
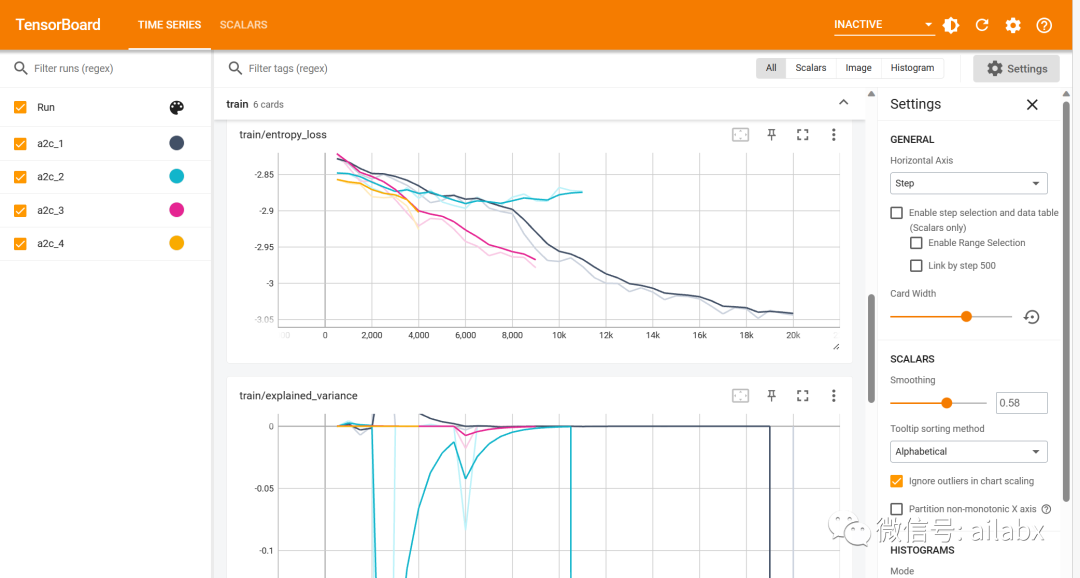
加一段随机action的代码,测试一下环境:
def random(self): logger.info('开始随机测试:{},{}'.format(self.env.dates[0], self.env.dates[-1])) self.reset() done = False while not done: action = self.action_space.sample() logger.debug(action) obs, reward, done, info = self.step(action) if done: e.env.show_results() logger.info('随机测试完成!')
话说,在大盘的时候,随机跑效果也不错。
调用stable-baseline3进行训练非常容易。不过要想深入了解算法本身,以期能够对它们进行改过,还是需要把这个黑箱打开,这只能算是一个benchmark,需要自行设计网络、算法和模型。
深度神经网络的好处就在于此,网络你自己是可以重新设计的,这与集成学习不同,我们不太可能,也没有必要重新设计lightGBM——学会调参就好了。而神经网络不同,这里可以发挥的空间巨大。
def train(self, model_name='a2c'): from engine.models.rl_models import get_model, train_model model = get_model(e, model_name) train_model(model, tb_log_name=model_name, total_timesteps=100000) model.save(model_name)
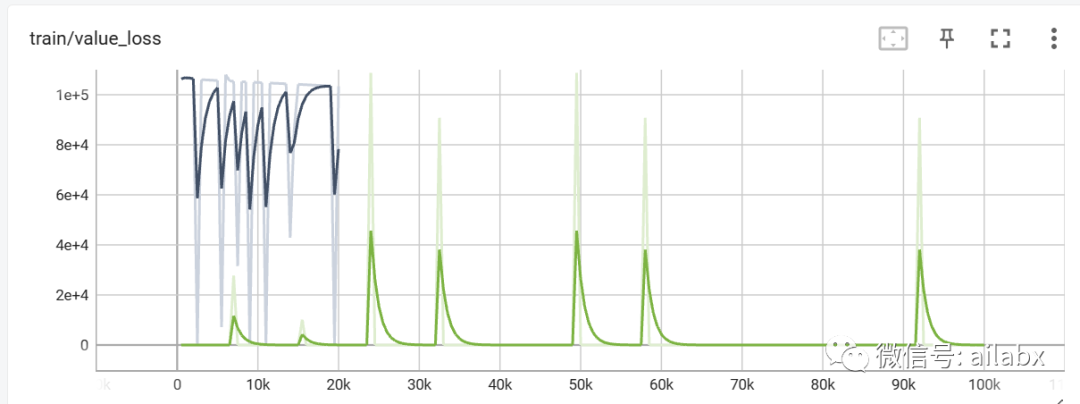
眉间放一指宽,看一段人世风间,到头来输赢又何妨——允许一切事情发生,缘起缘尽,顺其自然。
谈不上放飞自我,但做人可以更加洒脱一点。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104106
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!