
很多开源代码里的示例代码本身也不复杂,但由于它们把回测系统给耦合在里边,所以看起来特别乱。
今天我们来看看深度强化学习框架。
原本打算使用清华本科生那个“天授”,原因是qlib里使用的框架竟然是它。但看了一下官方文档,竟然没有tutorial。然后知乎上读了一些文章,弃用了。试下elegantRL吧。实在不行,兜底stable-baseline3是肯定没有问题的。
一个框架好不好用,第一观感就是它的quick start和tutorial。
pip install stable-baselines3[extra]
从官网上看,还是stable-baselines3成熟,安装也简单。
stable-baselines3,要求action_space这个可以理解,因为动作空间长度是确定的;但要求observation_space这个比较奇怪,每次观察的状态的shape必须一致?在投资里做不到啊,比如A股/美股的投资日历不同,那么有些天就不是所以的标的都可以“观察”到数据,在机器学习里,我们的输入仅要求“列”相同即可,输入的行数是可变的。
from stable_baselines3 import A2C
from stable_baselines3.common.env_checker import check_env
check_env(e) model = A2C("CnnPolicy", e).learn(total_timesteps=1000)
强化学习包不是太少,而是太多,乱花渐欲迷人眼。另外像tensortrade, finrl这样,就是把强化学习应用于金融,已经开发出了自己一个完整的框架,还带来数据的,也不在少数。
from abc import abstractmethod import gym import numpy as np from gym import spaces from numpy import infty from engine.datafeed.csv_dataloader import CSVDataloader from engine.env import Env class EnvRL(gym.Env): def __init__(self, env: Env, feature_cols: list): super().__init__() self.env = env self.feature_cols = feature_cols self.symbols = env.df_data['symbol'].unique() self.symbols.sort() #print(self.symbols) len_symbols = len(self.symbols) self.action_space = spaces.Box(low=0, high=1, shape=(len_symbols,)) # 不分配权重就是0, 全仓就是1 self.observation_space = spaces.Box( low=-np.infty, high=np.infty, shape=(len_symbols, len(feature_cols)), dtype=np.float64) def _softmax_normalization(self, actions): numerator = np.exp(actions) denominator = np.sum(np.exp(actions)) softmax_output = numerator / denominator return softmax_output def step(self, action): bar_df = self.env.step() obs = bar_df[self.feature_cols] actions = self._softmax_normalization(action) * 0.99 weights = {s: a for s, a in zip(self.symbols, actions)} self.env.portfolio.order_target_weights(weights) #reward = self.env.portfolio.get_total_mv() - self.env.portfolio.init_cash reward = self.env.calc_sharpe() is_done = self.env.curr_step == len(self.env.dates) - 1 if is_done: import matplotlib.pyplot as plt self.env.show_results() #print('reward',reward) return obs.values, reward, is_done, {} def reset(self): bar_df = self.env.reset() obs = bar_df[self.feature_cols] return obs.values if __name__ == '__main__': from engine.env import Env symbols = ['000300.SH', '399006.SZ'] loader = CSVDataloader(symbols, start_date="20120101") df = loader.load(fields=['close/shift(close,20)-1'], names=['roc_20']) from engine.env import Env from engine.algo.algos import * from engine.algo.algo_weights import * trading_env = Env(df) e = EnvRL(trading_env,['roc_20']) o = e.reset() done = False from stable_baselines3 import A2C from stable_baselines3.common.env_checker import check_env #check_env(e) model = A2C("MlpPolicy", e).learn(total_timesteps=10000) #print(e.env.portfolio.get_total_mv()) print('开始预测') vec_env = model.get_env() obs = vec_env.reset() while not done: action, _state = model.predict(obs, deterministic=True) obs, reward, done, info = vec_env.step(action) if done: print('预测完成。') #vec_env.render("human") # VecEnv resets automatically #e.env.show_results() ''' while not done: action = e.action_space.sample() obs, reward, done, info = e.step(action) print(obs) '''
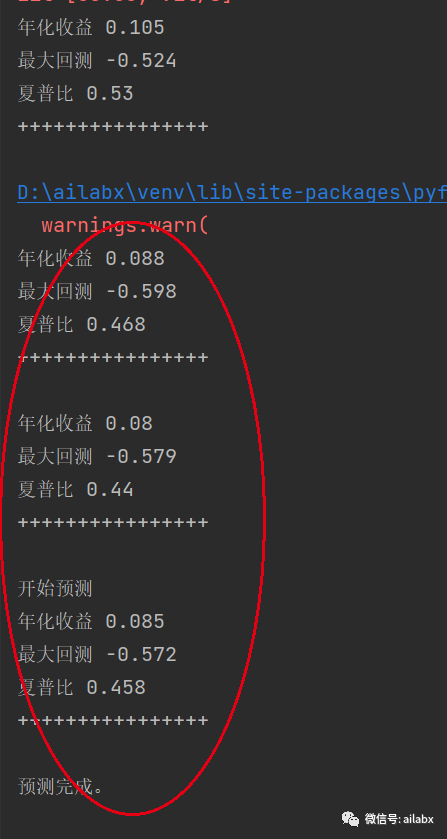

可前往星球下载全部代码,数据。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104108
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!