
这是来自某ETF软件的策略,我用咱们的框架复现一下。
01 一个还不错的策略


年化收益 0.175,最大回测 -0.226,夏普比 1.187。
我们用于轮动的ETF集合如下:
etfs = [
‘511220.SH’, #城投债
‘512010.SH’, # 医药
‘518880.SH’, #黄金
‘163415.SZ’, #兴全商业
‘159928.SZ’, # 消费
‘161903.SZ’, # 万家行业优选
‘513100.SH’ # 纳指
from engine.env import Env from engine.algo.algo_weights import * from engine.algo.algos import * e = Env(df) e.set_algos([ # RunMonthly(), SelectBySignal(buy_rules=['ind(roc_20)>0.02'], sell_rules=['ind(roc_20)<-0.02']), # SelectTopK(K=1, order_by='roc_20'), WeightEqually() ]) e.backtest_loop() e.show_results()
对比等级作为基准比较:
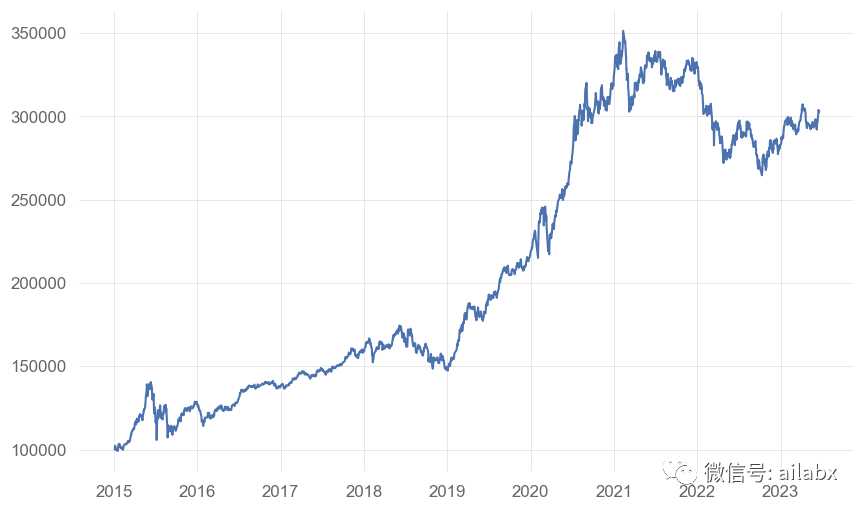
年化收益 0.146,最大回测 -0.248,夏普比 0.986。
代码与数据在工程的这个位置,投资难不难,其实还好,看你的预期,认知正确与否。
02 xgboost机器学习模型应用于量化金融
xgboost与lightGBM类似,表格数据时代的王者。
- 学新模型最好从具体例子开始,用模型的默认值先
- 尝试不同类型的数据,用编码技巧,处理缺失值
- 用提前终止来防止过拟合
- 能画图就画图,一图胜千字
- 能并行就并行,时间就是生命
- 调参是门艺术,没有捷径只能积累,多看大师的推荐,从重要的参数开始,先粗调再细调
pip install xgboost
from sklearn.metrics import accuracy_score from xgboost import XGBClassifier from engine.datafeed.dataset import DataSet from engine.models.model_base import ModelBase class XgBoostModel(ModelBase): def __init__(self, feature_cols): self.feature_cols = feature_cols def train(self, df): X_train, X_test, y_train, y_test = self.get_split_data(df, feature_cols=self.feature_cols, train_size=0.8) model = XGBClassifier() model.fit(X_train, y_train) y_pred = self.model.predict(X_test) accuracy_train = accuracy_score(model.fit(X_train), y_train) accuracy_test = accuracy_score(y_test, y_pred) print('训练集上的准确论:{},测试集上的准确率:{}'.format(accuracy_train, accuracy_test)) self.model = model def predict(self, data): # make predictions for X data = data[self.feature_cols] y_pred = self.model.predict(data) y_pred.index = data.index return y_pred
03 单因子分析
from typing import Tuple import pandas as pd def calc_ic(pred: pd.Series, label: pd.Series, date_col="date", dropna=False) -> Tuple[pd.Series, pd.Series]: df = pd.DataFrame({"pred": pred, "label": label}) ic = df.groupby(date_col).apply(lambda df: df["pred"].corr(df["label"])) ric = df.groupby(date_col).apply(lambda df: df["pred"].corr(df["label"], method="spearman")) if dropna: return ic.dropna(), ric.dropna() else: return ic, ric if __name__ == '__main__': from engine.datafeed.csv_dataloader import CSVDataloader symbols = [ '159870.SZ', '512400.SH', '515220.SH', '515210.SH', '516950.SH', '562800.SH', '515170.SH', '512690.SH', '159996.SZ', '159865.SZ', '159766.SZ', '515950.SH', '159992.SZ', '159839.SZ', '512170.SH', '159883.SZ', '512980.SH', '159869.SZ', '515050.SH', '515000.SH', '515880.SH', '512480.SH', '515230.SH', '512670.SH', '515790.SH', '159757.SZ', '516110.SH', '512800.SH', '512200.SH', ] loader = CSVDataloader(symbols, start_date="20120101") df = loader.load(fields=['close/shift(close,120)-1','shift(close,-20)/close-1'], names=['roc_20','return_20']) print(df) ic, ir = calc_ic(pred=df['return_20'], label=df['roc_20'],dropna=True) print(ic.mean(), ir.mean()) ic.plot() import matplotlib.pyplot as plt plt.show()
很容易计算出每个因子的ic/ric值。
其实打开很多量化包的代码来看,什么ic/ir,其实就是一个线性相关系数。你说有道理嘛?有,如果一个因子和你要预测的值没有相关关系,意味着二者没有关系,那这个因子自然无效。但完全有道理吗?不一定,非线性的关系呢?人脑识别不了的关系呢?
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104109
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!