
今天开始——因子挖掘。
无论是监督学习,还是强化学习,模型其实现在是过剩的。模型的学习能力是足够的,关键是数据和因子。
数据其实是最重要的,你有别人没有的另类数据,那才是alpha的来源。当然这个很难,所以,更多可以发力之处是因子挖掘,同样的数据,构造出不一样的因子来。
其实传统量化的规则,也是基于因子的。比如20日动量,就是一个因子,只是规则表达为 “20日动量大于0.08,则买入”。你也会问为什么是0.08,而不是0.02,这就比较尴尬了。
传统量化要复合很多因子基本是不太可能,多因子的一类做法是,对因子进行综合排序,或者加权等合成新的因子,然后按新的总因子进行排序打分。
这种方法就是太主观,而且因子的数量不能太多。
而使用机器学习的方式,可以消化成百上千个因子,人为主观判断的工作较少。但要求就是好的数据,好的因子。
所以——因子挖掘就变成一个非常重要的工作。
今天我们来讲讲这个遗传算法库gplearn——它是目前Python内最成熟的符号回归算法实现。它是一种监督学习方法,符号回归(symbolic regression)试图发现某种隐藏的数学公式,以此利用特征变量预测目标变量。
下面一个例子先说明一下gplearn是如何使用的:
我们定义适应性函数,这里是希望残差的平方和最小。
# 此文档将简要说明gplearn的使用方法 import numpy as np import pandas as pd from gplearn import fitness from gplearn.genetic import SymbolicRegressor from datetime import datetime def score_func_basic(y, y_pred, sample_weight, **args): # 适应度函数:策略评价指标 return sum((pd.Series(y_pred) - y) ** 2 ) # 这里是最小化残差平方和 m = fitness.make_fitness(function=score_func_basic, # function(y, y_pred, sample_weight) that returns a floating point number. greater_is_better=False, # 上述y是输入的目标y向量,y_pred是genetic program中的预测值,sample_weight是样本权重向量 wrap=False) # gplearn.fitness.make_fitness(function, greater_is_better, wrap=True) cmodel_gp = SymbolicRegressor(population_size=500, # 每一代公式群体中的公式数量 500 generations=10, # 公式进化的世代数量 10 metric=m, # 适应度指标,这里是前述定义的通过 大于0做多,小于0做空的 累积净值/最大回撤 的评判函数 tournament_size=50, # 在每一代公式中选中tournament的规模,对适应度最高的公式进行变异或繁殖 50 function_set= ('add', 'sub', 'mul','abs', 'neg', 'sin', 'cos', 'tan'), # 用于构建和进化公式使用的函数集 const_range=(-1.0, 1.0), # 公式中包含的常数范围 parsimony_coefficient='auto', # 对较大树的惩罚,默认0.001,auto则用c = Cov(l,f)/Var( l), where Cov(l,f) is the covariance between program size l and program fitness f in the population, and Var(l) is the variance of program sizes. # stopping_criteria=100.0, # 是对metric的限制(此处为收益/回撤) init_depth=(2, 4), # 公式树的初始化深度,树深度最小2层,最大6层 init_method='half and half', # 树的形状,grow生分枝整的不对称,full长出浓密 p_crossover=0.2, # 交叉变异概率 0.8 p_subtree_mutation=0.2, # 子树变异概率 p_hoist_mutation=0.2, # hoist变异概率 0.15 p_point_mutation=0.2, # 点变异概率 p_point_replace=0.2, # 点变异中每个节点进行变异进化的概率 max_samples=1.0, # The fraction of samples to draw from X to evaluate each program on. feature_names=None, warm_start=False, low_memory=False, n_jobs=1, verbose=1, random_state=0 ) if __name__ == '__main__': start = datetime.now() LenD = 1000 X1 = pd.DataFrame(data = {'a' : range(LenD), 'b' : np.random.randint(-10,10,LenD)}) Y1 = X1.sum(axis = 1)#.values print("初始策略是Y1=X1.sum(axis=1)") cmodel_gp.fit(X1,Y1) print(cmodel_gp) print("------------------------------------------------------------------------------------") print(" ") print(" ") print(" ") print(" ") print(" ") print(" ") print("------------------------------------------------------------------------------------") LenD = 1000 X2 = pd.DataFrame(data = {'a' : range(LenD), 'b' : np.random.randint(0,10,LenD)}) Y2 = np.cos(X2['a']) - np.sin(X2['b']) cmodel_gp.fit(X2,Y2) print(cmodel_gp) print("------------------------------------------------------------------------------------") end = datetime.now() elapsed = end - start print("Time elapsed:", elapsed)
代码里我们拟合两个函数,一个Y=X[a]+X[b]


第二个是Y=cos(X[a] – sinX[b])
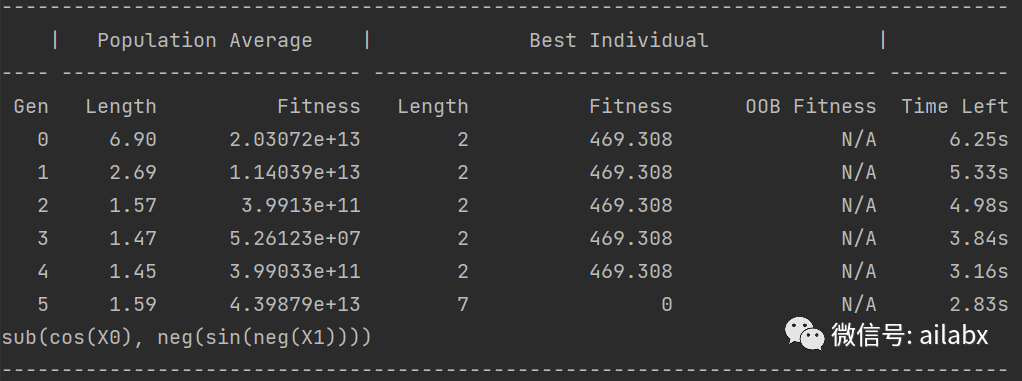
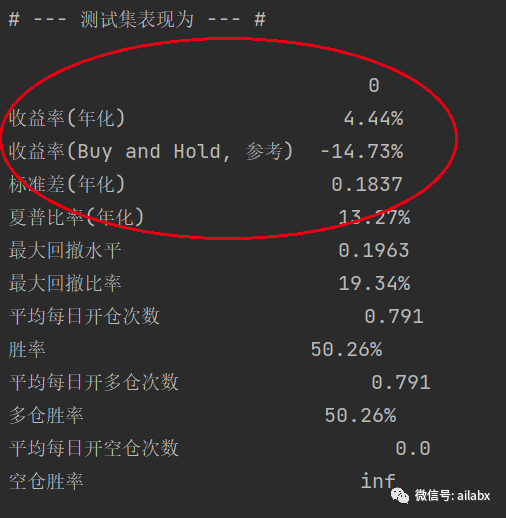
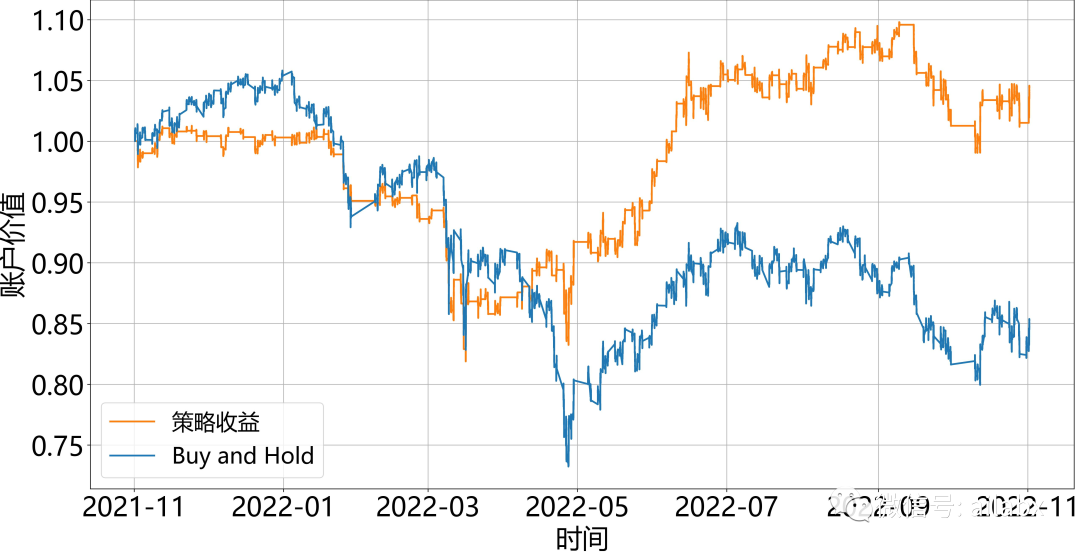
代码和数据在这个位置,明天继续:
这里下载:星球
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104104
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!