
前面的工作,我们的框架基本完成了量化的基础工作,后续正式进入AI的部分。AI量化系统Quantlab V1.7代码更新,支持pybroker引擎,含大类资产风险平价及波动率策略源码集,平均年化15%
AI前沿已经进入了AutoML的阶段,就是让机器进行机器学习。
把这一部分技术用于赋能金融投资,是非常有意义的事情。自动化机器学习,仅需要提供数据,AI将进行特征工程,模型选择,参数优化,模型更新及自动化部署等一系列工作,意味着,机器可以根据最新的数据、市场环境自主进化。
想想是不是非常美好。
当然,金融与其他行业不同,一步到位是不可能的。
但这个方向一定是正确的,越早拥抱越好,传统投资一直有生命力,但很累对不对,建立好一个系统,让系统为我们工作,这本身不就是被动收入——“睡后收入”的定义么?
之前我们分享过autogluon相关的文章:
年化26.8%,夏普1.28,单向做多螺纹钢的期货策略,Autogluon机器自主调参(策略+代码下载)。
使用AutoGluon的话,代码特别简洁,我们的数据及特征是已经计算好的:
from autogluon.core import TabularDataset
from autogluon.tabular import TabularPredictor
from engine.algos import Algo
import os from loguru import logger from config import DATA_DIR_MODELS class ModelTrainer: def __init__(self, df, model_path="mymodel/", train_data_percent=0.8): self.df = df self.model_path = DATA_DIR_MODELS.joinpath(model_path) self.train_data_percent = train_data_percent def train(self): df = self.df split = int(len(df) * self.train_data_percent) train = df.iloc[:split].copy() test = df.iloc[split:].copy() label = 'label' # print('建议回测日期', test.index[0]) train_data = TabularDataset(train) test_data = TabularDataset(test) predictor = TabularPredictor(label=label, path=self.model_path.resolve()).fit(train_data) print(predictor.leaderboard(test_data, silent=True))
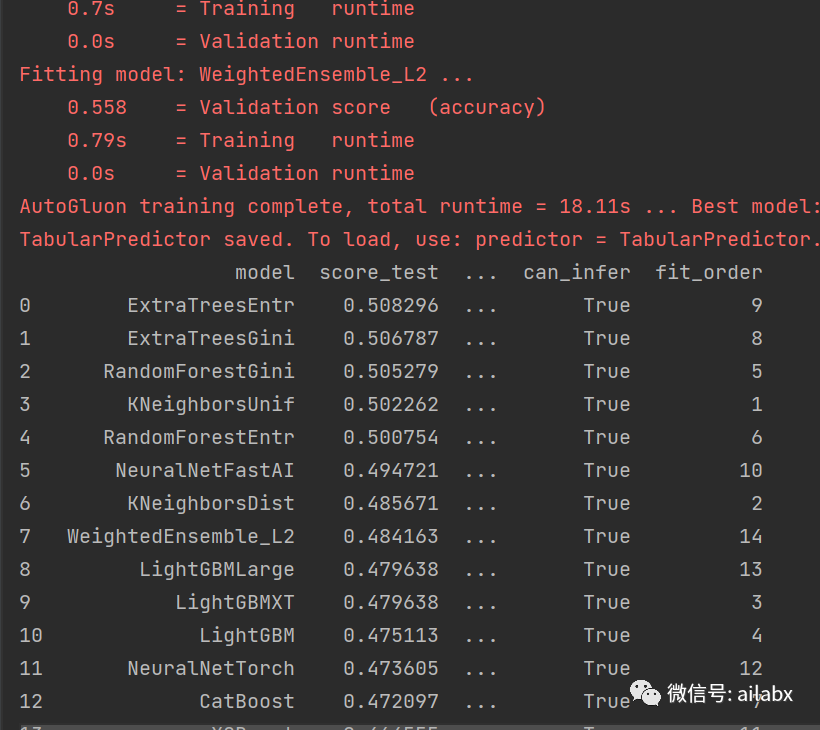
自动训练13个模型:
训练集55.8%,测试集50.8%(有一定的正概率,但还不明显,这是符合预期的,如果这么容易,那硅谷的大神岂不分分钟“攻陷”华尔街。。。)。

明天我们使用再引入深度神经网络,使用keras(tensorflow搭建深度网络),来分析,对比,优化。
代码和数据已经上传,请前往星球下载:
AI量化实验室社群
社群组织了两次小范围的线上例会,效果不错。
我们也一直在探索,如何最大化社群的力量,服务好大家。
我们计划每周邀请社群内外的有实战经验的同学来交流,分享,座谈。
上周主要是私募团队,尤其是小规模团队的实操经验,包括技术选型,团队分工,遇到的问题等等。纪要已经同步出来了。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103793
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!