
我觉得这个特别酷,但自己尝试去做时,发现特别难。
要理解中文,分词这一关基本就过不去。再到后面的词性标注,命名实体识别,三元组抽取,知识图谱等,每一个环节的损失都非常高。
直到大模型横空出世。
端对端的训练,丰富的世界知识,对语义的理解力,可控的文本生成能力。自然而然,垂直领域而言,金融大模型我相信很多人都想到这个机会。
FinGPT,之前他们团队做强化学习。FinRL到后来Fin-Meta,FinNLP,挺有情怀的一个团队。
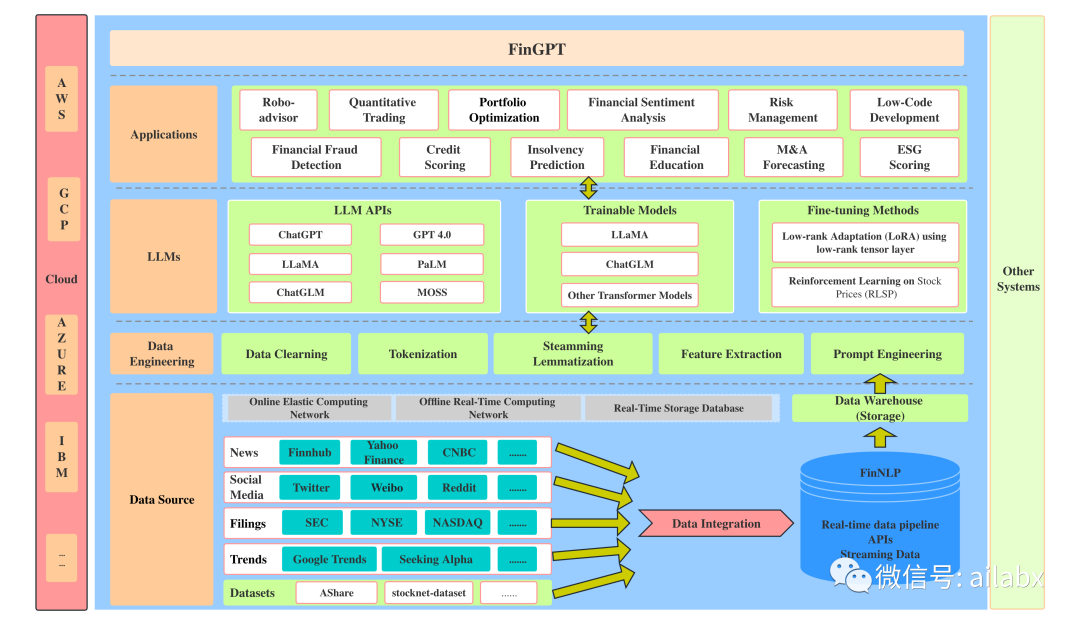

轻量级适应在金融领域非常有利。FinGPT可以快速微调以与新数据保持一致,而不是随着金融环境的每一次重大变化从头开始重新训练模型,这是一个昂贵而耗时的过程(适应成本大幅下降,估计每次训练不到300美元)。对标BloombergGPT太过昂贵。
允许使用自动数据管理管道进行及时更新(每月或每周更新)。但是,BloombergGPT拥有特权数据访问和API。FinGPT提供了一个更容易获得的替代方案。它优先考虑轻量级适应,利用一些最好的开源LLM的优势,然后将财务数据输入这些LLM并为财务语言建模进行微调。
从数据源,到数据处理,到通过大模型的LLM APIs能力,可训练的模型,还有一部分微调。
- 第一部分是数据源,在这里,我们从互联网上收集历史和流媒体数据。
- 第二部分是数据工程,在这里我们会对数据进行清洗,标记化处理和提示工程。
- 第三部分是大语言模型(LLMs)。在这里,我们可以以不同的方式使用LLMs。我们不仅可以使用收集到的数据来训练我们自己的轻量级微调模型,还可以使用这些数据和训练好的模型或LLM API来支持我们的应用程序。
- 最后一部分是应用程序部分,我们可以使用数据和LLMs来制作许多有趣的应用程序
关于人生感悟和体验
这些年,一些事。
有一些比较神奇却普遍。一些事情是单向不可逆的,比如一线城市毕业时候的户口,错过就是一生。
我们毕业那会,高新技术企业是很容易获得这个一线城市户口的,当年没概念,也没有长辈和师长告诉过我们。然后,错过,数年后回来,发现,这个城市多数事情与你无关,飞涨的房价与五年社保绑定着。
好多朋友,同事在结婚生子后,在孩子教育上遇到的问题更加突显。孩子进入初中,他们不得不考虑随孩子到某一方的老家去定居,随之要考虑的,还有双方的工作变动以及未来全家的规划与人生安排。
——这些起点,都在于当年那一个不可逆的选择。

当然婚姻是为数不多的,可以“弥补”的机会。很多人没想明白,错过后终将引入太多的麻烦。
还有一些小事,值得注意。很多年轻人离开老家,在一线城市筑梦。如果你“一不小心”在老家办了张手机卡,如果你想注销,可能需要自己亲自跑一趟,如果家在小镇,可以还是去城里才有解决方案。——开号30秒,销号可不轻松。
互联网如此昌明的时代,很多事情已经极尽便利,比如可以跨省办护照,补身份证之类的。但总有一些时代印记的东西,在提醒我们,一些事情要慎重。
“有惊而无险”,却可以让我们实实在在学到东西。
所谓“岁月静好”,最好的状态是“财富自由”。
而且最好不是靠网红、流量走红的自由。
国民老公不必在乎网友的评论,因为人家不靠流量赚钱;网红明星不一样,需要承担很高的道德成本。
那天与朋友聊天,前字节程序员郭宇才是普通人自由的样板。
——通过互联网公司股权、投资而财富自由。
在昨天代码的基础上,我们新增model的保存:
import pandas as pd
import cloudpickle
from gplearn.fitness import make_fitness
from gplearn.genetic import SymbolicTransformer
import gplearn as gp
import time
from engine.alpha.funcs import funcs_set
from engine.alpha.metrics import _my_metric_backtest
my_metric = make_fitness(function=_my_metric_backtest, greater_is_better=True)
def gp_fit(df_train, label):
init_function = ['add', 'sub', 'mul', 'div', 'sqrt', 'abs', 'sin', 'cos', 'tan']
init_function.extend(list(funcs_set))
trans = SymbolicTransformer(
generations=5, # 整数,可选(默认值=20)要进化的代数
population_size=1000, # 整数,可选(默认值=1000),每一代群体中的公式数量
hall_of_fame=100,
n_components=100, # 最终生成的因子数量
function_set=init_function, parsimony_coefficient=0.0005, max_samples=0.9, verbose=1, const_range=(10.0, 20.0), feature_names=list('$ ' + n for n in df_train.columns), random_state=int(time.time()), # 随机数种子 n_jobs=-1, #metric=my_metric, ) trans.fit(df_train, label) print(trans) best_programs = trans._best_programs best_programs_dict = {} for p in best_programs: factor_name = 'alpha_' + str(best_programs.index(p) + 1) best_programs_dict[factor_name] = {'fitness': p.fitness_, 'expression': str(p), 'depth': p.depth_, 'length': p.length_} best_programs_dict = pd.DataFrame(best_programs_dict).T best_programs_dict = best_programs_dict.sort_values(by='fitness') print(best_programs_dict) filename = 'factors.pkl' with open(filename, 'wb') as f: cloudpickle.dump(trans, f) if __name__ == '__main__': from engine.config import etfs from engine.datafeed.dataloader import CSVDataloader symbols = etfs loader = CSVDataloader(symbols, start_date="20100101") df = loader.load(fields=['shift(close,-20)/close-1'], names=['label']) df.dropna(inplace=True) cols = ['open', 'high', 'low', 'close', 'volume'] gp_fit(df[cols], df['label'])
看这个fitness值(默认就是因子IC),看起来还不错,当然这些因子有点长,我们后续会优化。
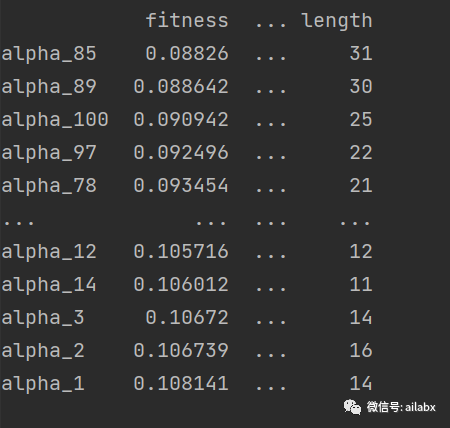
从本地加载训练好的模型,可以直接计算因子值:
if __name__ == '__main__': import cloudpickle filename = 'factors.pkl' with open(filename, 'rb') as f: est_gp = cloudpickle.load(f) best_programs = est_gp._best_programs best_programs_dict = {} for p in best_programs: factor_name = 'alpha_' + str(best_programs.index(p) + 1) best_programs_dict[factor_name] = {'fitness': p.fitness_, 'expression': str(p), 'depth': p.depth_, 'length': p.length_} best_programs_dict = pd.DataFrame(best_programs_dict).T best_programs_dict = best_programs_dict.sort_values(by='fitness') print(best_programs_dict)
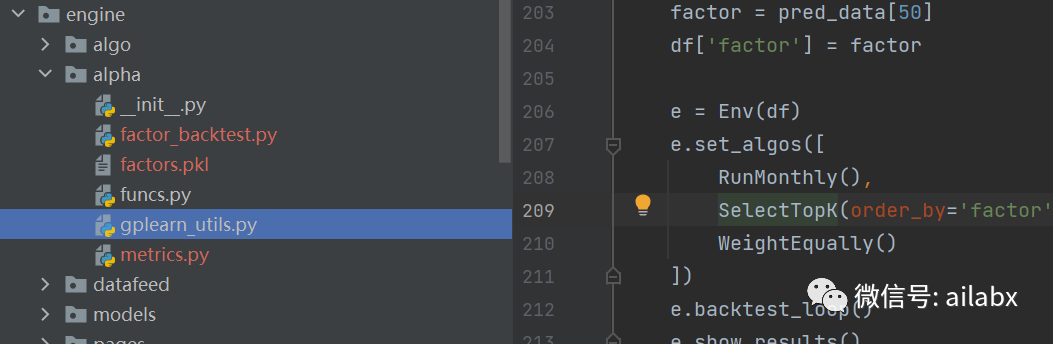
按因子值从大到小轮动,接入我们自己的回测系统:
pred_data = pd.DataFrame(factors_pred).T.T pred_data.index = df.index factor = pred_data[50] df['factor'] = factor e = Env(df) e.set_algos([ RunMonthly(), SelectTopK(order_by='factor', b_ascending=False, K=3), WeightEqually() ]) e.backtest_loop() e.show_results()

(仅做单因子回测评估之用)
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104098
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!