
今日策略——沪深300”高低价通道“突破
策略的思路——择时策略。
买入规则:收盘价 突破 1天前60日内最高价。
卖出规则:收盘价 跌存 1天前60日内最低价。
与昨天的策略类似,昨天是布林带,是收盘价上两个标准差;今天是60日的最高价与最低价为通道。看在我们的框架里如何实现。
这里我们需要一个N天最高与N天最低的函数:
def rolling(se, N, func):
se = pd.Series(se)
ind = getattr(se.rolling(window=N), func)()
return ind
def max(se, N):
return rolling(se, N, 'max')
def min(se, N):
return rolling(se, N, 'min')
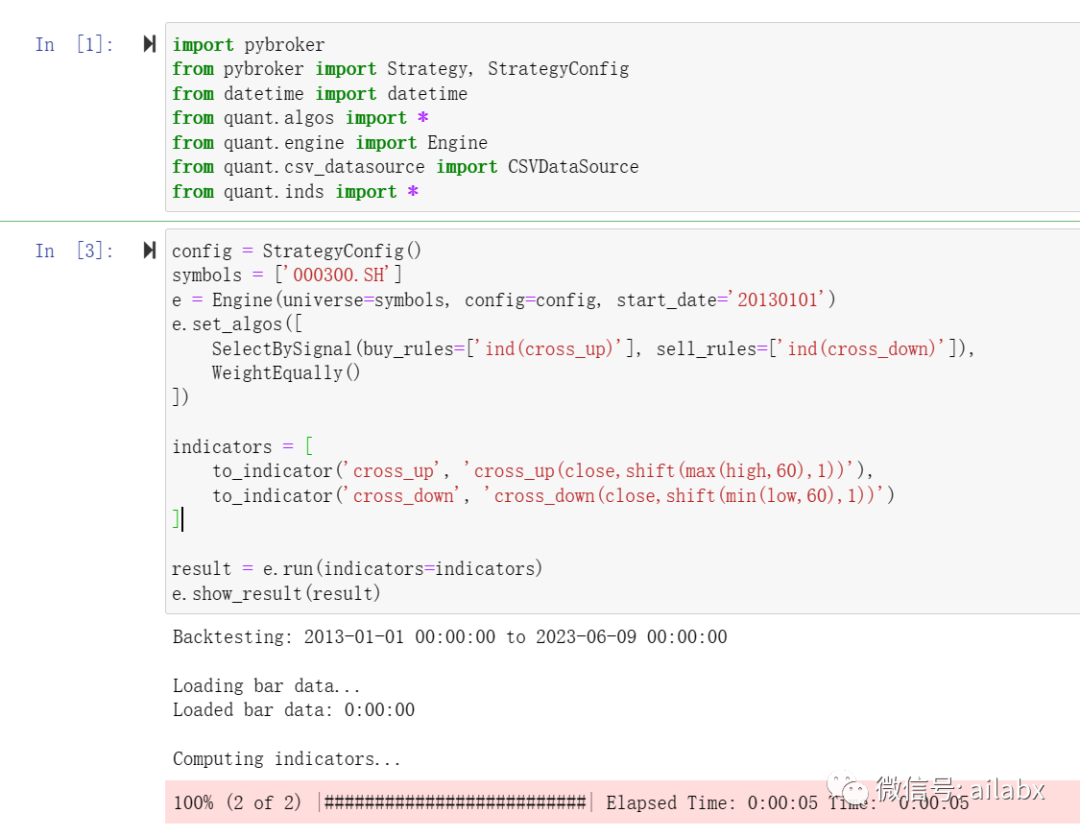

主要是看看,我们的“因子表达式”,结合“积木式”策略开发的便利性。
代码已经发布至星球:我的开源项目及知识星球
StockRanker梯度提升树——排序模型
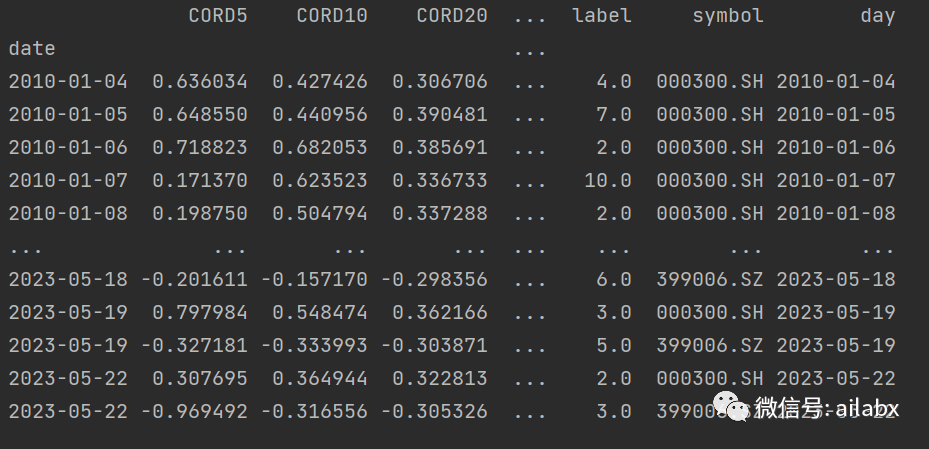
因子计算与数据自动标注
import os import pandas as pd from quant.inds import to_indicator from datetime import datetime from sklearn.model_selection import train_test_split class Alpha: def __init__(self): pass def get_feature_config(self): return self.parse_config_to_fields() def get_label_config(self): return ["shift(close, -5)/shift(open, -1) - 1","qcut(shift(close, -5)/shift(open, -1) - 1,20)" ], ["label_c", 'label'] @staticmethod def parse_config_to_fields(): # ['CORD30', 'STD30', 'CORR5', 'RESI10', 'CORD60', 'STD5', 'LOW0', # 'WVMA30', 'RESI5', 'ROC5', 'KSFT', 'STD20', 'RSV5', 'STD60', 'KLEN'] fields = [] names = [] windows = [5, 10, 20, 30, 60] fields += ["corr(close/shift(close,1), log(volume/shift(volume, 1)+1), %d)" % d for d in windows] names += ["CORD%d" % d for d in windows] fields += ['close/shift(close,20)-1'] names += ['roc_20'] return fields, names class DataSet: def __init__(self, symbols, handler=None, start_date='20100101', end_date=datetime.now().strftime('%Y%m%d')): self.handler = handler self.symbols = symbols self.start_date = start_date self.end_date = end_date self._load() def _process(self, df): if not self.handler: return df fields, names = self.handler.get_feature_config() self.features = names label_fields, label_names = self.handler.get_label_config() self.label_names = label_names for field, name in zip(fields, names): ind = to_indicator(name, field) df[name] = ind(df) for field, name in zip(label_fields, label_names): ind = to_indicator(name, field) df[name] = ind(df) return df def _load(self, ): dfs = [] for s in self.symbols: # dirname去掉文件名,返回目录 path = os.path.dirname(__file__) # print(path) df = pd.read_csv('{}/data/{}.csv'.format(path, s), dtype={'date': str}) #for col in ['open', 'high', 'low', 'close']: # df[col] = df[col] / df[col][0] df.set_index('date', inplace=True) df.index = pd.to_datetime(df.index) df.sort_index(ascending=True, inplace=True) df = self._process(df) # 如果有handler,同使用handler标注 dfs.append(df) df = pd.concat(dfs) # df['date'] = pd.to_datetime(df['date']) df.dropna(inplace=True) df.sort_index(ascending=True, inplace=True) cols = self.features.copy() cols.extend(self.label_names) cols.extend(['symbol']) df = df[cols] data = df[(df.index >= self.start_date) & (df.index <= self.end_date)] data['day'] = data.index #print(g_data) # self.data['qid'] = self.data.groupby('date').apply(lambda x: ) self.data = data def get_feature_names(self): return self.features def get_label_name(self): return 'label' def get_split_data(self, train_size=0.6): df = self.data X_train, X_test, y_train, y_test = train_test_split(df[self.get_feature_names()], df[self.get_label_name()], shuffle=False, train_size=train_size) return X_train, X_test, y_train, y_test if __name__ == '__main__': ds = DataSet(['000300.SH', '399006.SZ'],handler=Alpha()) print(ds.data)
排序模型
from quant.dataset import DataSet import lightgbm import numpy as np class LGBModel: def __init__(self, dataset: DataSet): self.ds = dataset def _prepare_groups(self, df): df['day'] = df.index group = df.groupby('day')['day'].count() return group def fit(self): X_train, X_test, y_train, y_test = self.ds.get_split_data() y_test = y_test.astype(int) y_train = y_train.astype(int) g_train = self._prepare_groups(X_train.copy(deep=True)) g_test = self._prepare_groups(X_test.copy(deep=True)) # Creating the ranker object ranker = lightgbm.LGBMRanker( objective="lambdarank", boosting_type="gbdt", n_estimators=5, importance_type="gain", metric="ndcg", num_leaves=10, learning_rate=0.05, max_depth=-1, label_gain=[i for i in range(max(y_train.max(), y_test.max()) + 1)]) # Training the model ranker.fit( X=X_train, y=y_train, group=g_train, eval_set=[(X_train, y_train), (X_test, y_test)], eval_group=[g_train, g_test], eval_at=[4, 8]) lightgbm.plot_importance(ranker, figsize=(12, 8)) import matplotlib.pyplot as plt scores = ranker.predict(X_test.iloc[:-20]) rankings = np.argsort(-scores) print(rankings) # plt.show() if __name__ == '__main__': from quant.dataset import Alpha from quant.dataset import DataSet etfs = [ '159870.SZ', '512400.SH', '515220.SH', '515210.SH', '516950.SH', '562800.SH', '515170.SH', '512690.SH', '159996.SZ', '159865.SZ', '159766.SZ', '515950.SH', '159992.SZ', '159839.SZ', '512170.SH', '159883.SZ', '512980.SH', '159869.SZ', '515050.SH', '515000.SH', '515880.SH', '512480.SH', '515230.SH', '512670.SH', '515790.SH', '159757.SZ', '516110.SH', '512800.SH', '512200.SH', ] ds = DataSet(etfs, handler=Alpha()) LGBModel(ds).fit() # lightgbm.plot_importance(ranker, figsize=(12, 8))
后续使用模型输出的排序结果进行ETF行业轮动回测,请大家继续关注。
代码均上传到星球,请自行下载。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104120
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!