
python编程中,经常会遇到两个或多个列表比较,或查找共有元素的问题,需要把两个或多个长度相等或长度不等的列表中的共有元素找出来,并保存到一个新的列表。解决这一问题,常见的方法有以下 6 种方法。
def intersection(lst1, lst2):
lst3 = [value for value in lst1 if value in lst2]
return lst3
# Driver Code
lst1 = [4, 9, 1, 17, 11, 26, 28, 54, 69]
lst2 = [9, 9, 74, 21, 45, 11, 63, 28, 26]
print(intersection(lst1, lst2))结果如下:
[9, 11, 26, 28]方法2,使用 set() 函数
def intersection(lst1, lst2):
return list(set(lst1) & set(lst2))
# Driver Code
lst1 = [15, 9, 10, 56, 23, 78, 5, 4, 9]
lst2 = [9, 4, 5, 36, 47, 26, 10, 45, 87]
print(intersection(lst1, lst2))结果如下:
[9, 10, 4, 5]方法3:使用set()函数处理较长的列表,然后使用内置函数intersection() 计算出交集列表,其中 intersection() 是set的一级类方法。
def Intersection(lst1, lst2):
return set(lst1).intersection(lst2)
# Driver Code
lst1 = [ 4, 9, 1, 17, 11, 26, 28, 28, 26, 66, 91]
lst2 = [9, 9, 74, 21, 45, 11, 63]
print(Intersection(lst1, lst2))
结果如下:
{9, 11}方法4 :这是一种混合方法,运行效率比较高。
def intersection(lst1, lst2):
# Use of hybrid method
temp = set(lst2)
lst3 = [value for value in lst1 if value in temp]
return lst3
# Driver Code
lst1 = [9, 9, 74, 21, 45, 11, 63]
lst2 = [4, 9, 1, 17, 11, 26, 28, 28, 26, 66, 91]
print(intersection(lst1, lst2))结果如下:
[9, 9, 11]方法 5 : 这种方法可以处理二维列表,查找其中一个一维列表与二维列表中的子列表的交集,使用filter() 函数
def intersection(lst1, lst2):
lst3 = [list(filter(lambda x: x in lst1, sublist)) for sublist in lst2]
return lst3
# Driver Code
lst1 = [1, 6, 7, 10, 13, 28, 32, 41, 58, 63]
lst2 = [[13, 17, 18, 21, 32], [7, 11, 13, 14, 28], [1, 5, 6, 8, 15, 16]]
print(intersection(lst1, lst2)) 结果如下:
[[13, 32], [7, 13, 28], [1, 6]]方法6:使用 pandas 中的 merge() 函数。这是一个较复杂的实例,从项目中提取。
问题:
从allstocks.csv、symbol_findata.csv 和
shenwan2_category_stocks.csv 文件中,找出申万二级分类所包含的股票。
文件 allstocks.csv 包括4292个股票代码,格式如下:


编码 1600000 的含义:
1 – 市场代码,1 表示沪市,0表示深市,600000 – 股票代码
文件 symbol_findata.csv 包括 4950 只股票及其总股本、流通股本和市净率,格式如下:
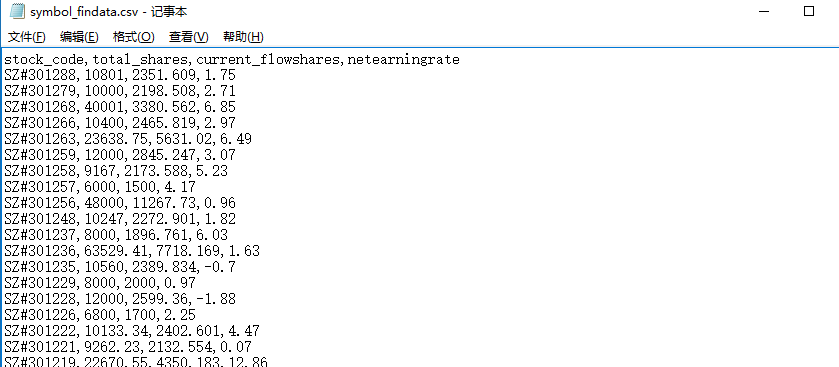
文件
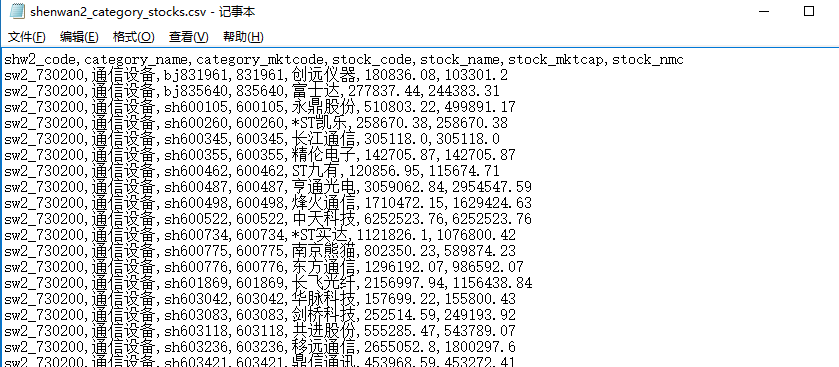
shenwan2_category_stocks.csv, 包括4416只股票的申万二级分类名称和编码、交易市场及股票代码、股票名称、总市值和流通市值,格式如下:
import pandas as pdimport csvimport functools as ftwith open('.\\work_data\\allstocks.csv','r',encoding='utf-8') as f: reader = csv.reader(f) allstocks_lst = [] for line in reader: #遍历 #print(line[0]) allstocks_lst.append(line[0][1:]) print(allstocks_lst[0:10])print('allstocks_lst len:',len(allstocks_lst))allstocks_df = pd.DataFrame(allstocks_lst, columns =['symbol']) print(allstocks_df[0:4])##2. symbol_findata.csv中的列: 'stock_code','total_shares','current_flowshares','netearningrate'symbol_financialdata = pd.read_csv('.\\work_data\\symbol_findata.csv',header = 0, dtype = {'stock_code':str,'total_shares':float,'current_flowshares':float,'netearningrate':float})print(symbol_financialdata[0:3])stockcode_lst1 = [x[3:] for x in symbol_financialdata.stock_code.iloc[:].values.tolist() if x[3:5] !='68']print('symbol_financialdata len:',len(stockcode_lst1))symbol_financialdata[['marketID','symbol']] = symbol_financialdata.stock_code.str.split("#",expand=True)print(symbol_financialdata[0:3])##3. shenwan2_category_stocks.csv中的列:shw2_code,category_name,category_mktcode,stock_code,stock_name,stock_mktcap,stock_nmcshw2_category_stocks = pd.read_csv('.\\work_data\\shenwan2_category_stocks.csv',header = 0, dtype = {'stock_code':str,'category_name':str,'category_mktcode':str,'stock_code':str, 'stock_mktcap':float,'stock_nmc':float})print(shw2_category_stocks[0:3])stockcode_lst2 = shw2_category_stocks.stock_code.iloc[:].values.tolist()print('shw2_category_stocks len:',len(stockcode_lst2))shw2_category_stocks['symbol'] = shw2_category_stocks['stock_code']print(shw2_category_stocks[0:3])# filtered1_stockcode = [x for x in stockcode_lst2 if any(y in x for y in stockcode_lst1)]# print('filtered1_stockcode len:',len(filtered1_stockcode))df_merged = ft.reduce(lambda left, right: pd.merge(left, right, on='symbol'), [allstocks_df,symbol_financialdata,shw2_category_stocks])for i in range(0,5): # len(df_merged) print(df_merged.symbol.iloc[i],df_merged.stock_code_x.iloc[i], df_merged.total_shares.iloc[i],df_merged.current_flowshares.iloc[i], df_merged.netearningrate.iloc[i],df_merged.marketID.iloc[i], df_merged.shw2_code.iloc[i],df_merged.category_name.iloc[i], df_merged.category_mktcode.iloc[i],df_merged.stock_code_y.iloc[i], df_merged.stock_name.iloc[i],df_merged.stock_mktcap.iloc[i], df_merged.stock_nmc.iloc[i])print(len(df_merged)) groups = df_merged.groupby(['category_name']) positions_list = []everygroup_len = []for group_key, group_value in groups: group = groups.get_group(group_key) #quantity_tmp = sum(group['quantity']*group['buy_sell']) print('------------------------------') print(group) everygroup_len.append([group_key,len(group)])print('groups len:',len(groups))for itm in everygroup_len: print(itm)运行结果如下,截图1:
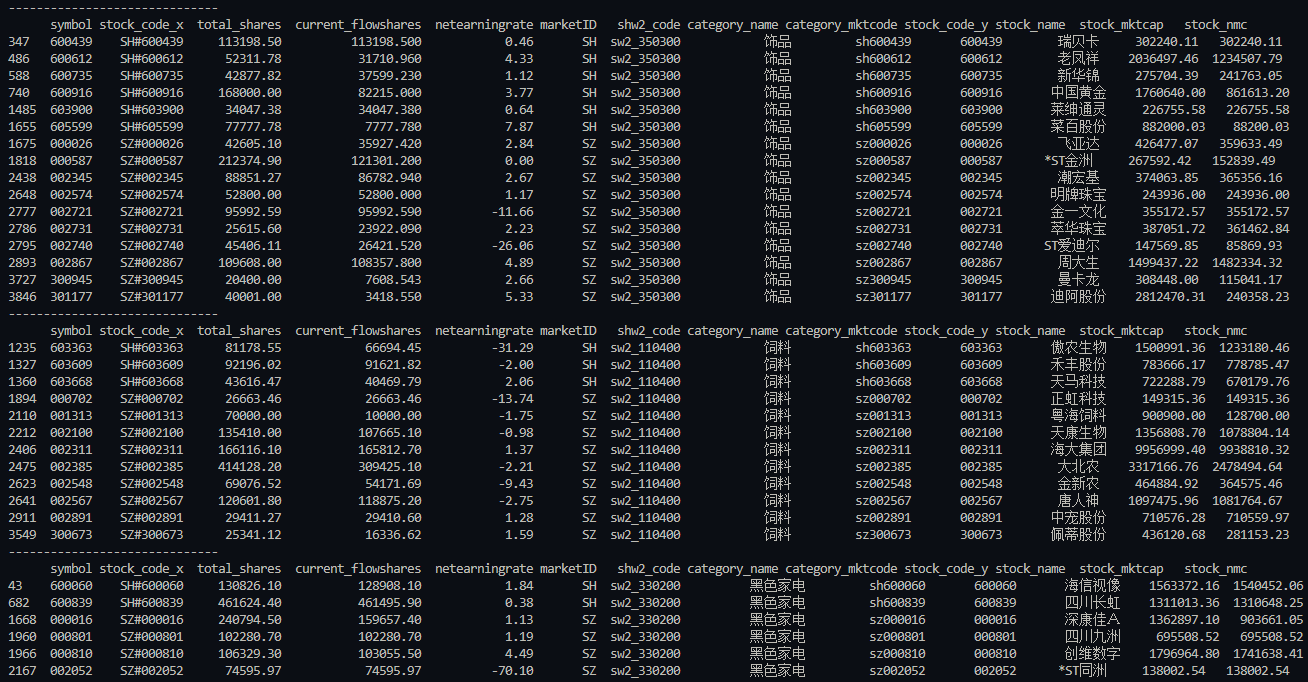
运行结果如下,截图2:

(截图2 显示 申万二级分类的名称及其所属的股票个数)
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/76353
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!