
在程序化交易中,经常需要计算平均值和方差,如在计算均线和波动率等指标。当我们需要高频率和长周期计算时,需要保留长时间的历史数据,这即没必要也耗时耗资源。本文介绍了一种在线更新算法,用于计算加权平均数和方差,这对于处理实时数据流和动态调整交易策略尤为重要,特别是高频策略。文章还提供了相应的Python代码实现,帮助交易者在实际交易中快速部署和应用这一算法。
简单平均和方差
如果我们用 μn 来表示第 n 个数据点的平均值,假设我们已经计算了 n−1 个数据点的平均数 μn−1,现在我们接收到一个新的数据点 xn。我们想要计算包含这个新数据点的新平均数 μn。下面为详细的推导。
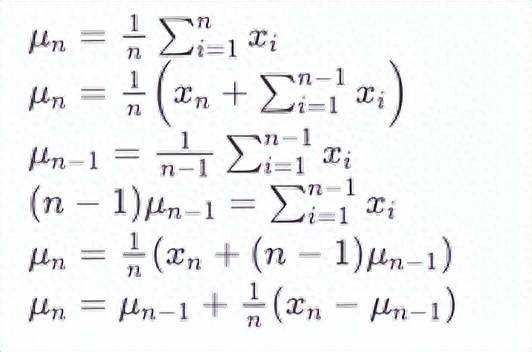

方差更新过程可以分解为以下步骤:
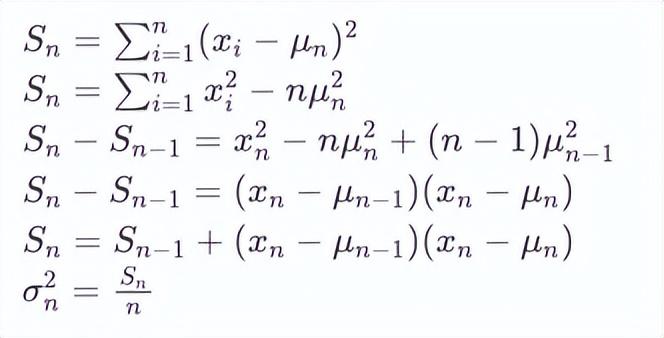
由上面两个公式可见,这个过程允许我们在接收到每个新数据点 xn 时,只保留上一个数据的平均值和方差,就可以更新出新的平均值和方差,无需保存历史数据,并且计算更加快捷。但问题是这样计算出来是整个样本的均值和方差,而我们在实际策略中,需要考虑的是一定的固定周期。观察上面的均值更新可以看到,新的均值更新量是新的数据与过去均值的偏差乘以一个比例,如果固定这个比例,就将得到接下来要谈的指数加权平均。
指数加权平均数(Exponentially-weighted mean)
指数加权平均数可以通过以下递归关系来定义:
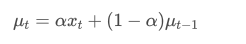
其中,μt 是在时间点 t 的指数加权平均数,xt 是在时间点 t 的观测值,α 是权重因子,μt−1 是上一时间点的指数加权平均数。
指数加权方差(Exponentially-weighted variance)
对于方差,我们需要计算每个时间点的平方偏差的指数加权平均。这可以通过以下递归关系来实现:
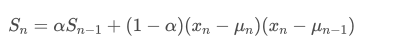
其中,σt2 是在时间点 t 的指数加权方差,σt−12 是上一时间点的指数加权方差。
观察指数加权平均数和方差,它们的增量更新的形式符合直觉,均保留一部分过去的值,再加上新的变化,具体的推导过程可以参考这篇论文:stats.pdf
简单移动平均(SMA)与指数移动平均(EMA)
简单平均数(又称算术平均数)和指数加权平均数是两种常见的统计度量,它们各自有不同的特点和用途。简单平均数对每个观测值赋予相同的权重,它反映了数据集的中心位置。指数加权平均数是一种递归计算方式,它给予最近的观测值更高的权重。权重随着观测值距离当前时间的增加而指数级减少。
- 权重分配:简单平均数给予每个数据点相同的权重,而指数加权平均数给予最近的数据点更高的权重。
- 对新信息的敏感度:简单平均数对新加入的数据不够敏感,因为它涉及到所有数据点的重新计算。指数加权平均数则能够更快地反映最新数据的变化。
- 计算复杂性:简单平均数的计算相对简单,但随着数据点的增加,计算成本也会增加。指数加权平均数的计算更为复杂,但由于其递归性质,它可以更高效地处理连续数据流。
EMA和SMA近似换算方式
虽然简单平均数和指数加权平均数在概念上是不同的,但我们可以通过选择合适的 α 值来使指数加权平均数近似于一个包含特定数量观测值的简单平均数。这个近似的关系可以通过等效样本大小(effective sample size)来描述,它是指数加权平均数中权重因子 α 的函数。
简单移动平均(SMA)是在给定时间窗口内所有价格的算术平均值。对于一个时间窗口 N,SMA 的质心(即平均数所在的位置)可以认为是:
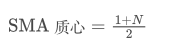
指数移动平均(EMA)则是一种加权平均数,其中最近的数据点有更大的权重。EMA 的权重随时间指数级减少。EMA 的质心可以通过以下级数求和得到:
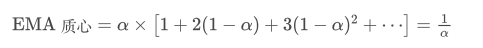
当我们假设 SMA 和 EMA 有相同的质心时,可以得到:
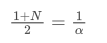
解这个方程,我们可以得到 α 和 N 之间的关系:
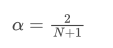
这意味着,对于一个给定的 N 天的 SMA,相应的 α 值可以用来计算一个“等效”的 EMA,使得两者有相同的质心,结果也非常相近。
EMA不同更新频率的换算
假设我们有一个每秒钟更新一次的EMA,其权重因子为 α1。这意味着每秒钟,新数据点会以 α1 的权重加入到EMA中,而旧数据点的影响则会乘以 1−α1。
如果我们改变更新频率,比如每 f 秒更新一次,我们想要找到一个新的权重因子 α2,使得 f 秒内数据点的总体影响与每秒更新时相同。
在 f 秒的时间内,如果不进行更新,旧数据点的影响会连续衰减 f 次,每次乘以 1−α1。因此,f 秒后的总衰减因子是 (1−α1)f。
为了使 f 秒更新一次的EMA在一个更新周期内与每秒更新一次的EMA有相同的衰减效果,我们设置 f 秒后的总衰减因子等于一次更新周期内的衰减因子:
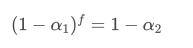
解这个方程,我们得到新的权重因子 α2:
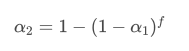
这个公式给出了在更新频率变化时保持EMA平滑效果不变的新权重因子 α2 的近似值。举个例子:我们在计算价格均值 α1 为0.001, 每10s更新一次最新价,如果改为1s更新一次,等效的α2约为0.01
Python代码实现
class ExponentialWeightedStats:
def __init__(self, alpha):
self.alpha = alpha
self.mu = 0
self.S = 0
self.initialized = False
def update(self, x):
if not self.initialized:
self.mu = x
self.S = 0
self.initialized = True
else:
temp = x - self.mu
new_mu = self.mu + self.alpha * temp
self.S = self.alpha * self.S + (1 - self.alpha) * temp * (x - self.mu)
self.mu = new_mu
@property
def mean(self):
return self.mu
@property
def variance(self):
return self.S
# 使用示例
alpha = 0.05 # 权重因子
stats = ExponentialWeightedStats(alpha)
data_stream = [] # 数据流
for data_point in data_stream:
stats.update(data_point)
总结
在高频程序化交易中,实时数据的快速处理至关重要。为了提高计算效率并降低资源消耗,本文介绍了一种在线更新算法,用于连续计算数据流的加权平均数和方差。实时上增量更新的计算还可用于各种统计数据和指标的计算,如两种资产价格相关性、线性拟合等等,潜力很大。增量更新把数据当作信号系统来看待,相对与固定周期的计算,是一种思路的进化。如果你的策略中还有保存历史数据计算的部分,不妨按照这种思路改造下,只记录对系统状态的估计,当有新的数据到来时,再更新系统状态,如此循环下去。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/77131
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!