
最近,有读者和本狐讨论股票价格筹码策略。于是,开了此篇文章分享下价格筹码分析的干货。本文将深入分析价格筹码策略,并提供核心python代码和通达信选股公司代码,供有经验的量化开发者和新手上手演练,定制和完善自己的基于价格筹码的量化选股交易策略。
时间复利,期待高收益
价格筹码
股票价格筹码是指投资者在某个特定价格区间内持有的股票数量。它通常用于反映市场的供需关系和投资者的情绪。具体而言,股票每一股在成交后都会有一个最近的成交价格,比如某只股票在13元成交1000股,14元成交500股,15元成交2000股。分布就是指将筹码按照其最近成交价格进行分类,统计每个成交价格上筹码的数量。我们把一只股票所有的筹码都按照最近一次成交价进行分类排列,就能得到筹码分布图。
价格筹码对预测股票的未来涨跌有一定的帮助。当投资者大量买入某只股票时,价格筹码会增加,这通常意味着市场对该股票的看好程度提高,未来股价可能会上涨。相反,如果投资者大量卖出某只股票,价格筹码会减少,这可能意味着市场对该股票的看跌程度增加,未来股价可能会下跌。然而,价格筹码并不是唯一的因素,也不是100%准确的预测工具。其他因素如公司基本面、宏观经济环境、政策变化等也会影响股票的价格走势。因此,投资者应该综合考虑多种因素来做出投资决策。
在股票行情软件中,可以很方便地查看股票价格筹码。进入股票的k线图,按快捷键“ctrl+U”,即可查看股票的价格筹码分布图。
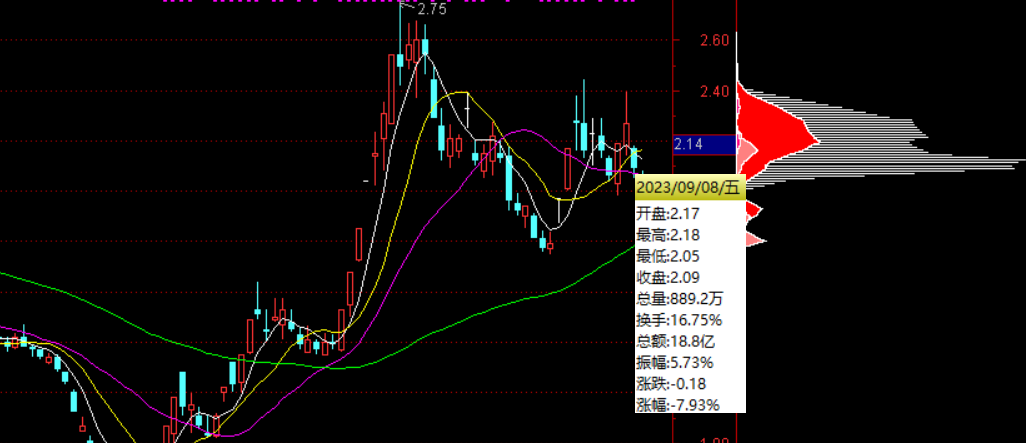

股票价格筹码示意图
Python计算价格筹码
现阶段,我们没有数据能够详细地将买入卖出明细对应到每个交易账号。日内的逐笔数据,由于数据量较大,在进行长期计算时,我们通常可以进行简化,以日线成交数据代替。这样的计算虽然由于粒度较大,有一定程度的失真,但是对于走势的预测还是有指导意义。
现在,网上能够找到一些公开的计算股票筹码的代码。以下展示了代码的核心部分:
def cal_situation(data):
"""
计算筹码分布的概况
:param data: 每日筹码明细
:return: 每日筹码概况
data:
交易日期 当日价格 筹码价格 筹码占比
0 2023-06-08 10.085761 10.085761 0.009457
1 2023-06-08 10.085761 10.099691 0.017482
……………… ……………… ……………… ……………………
6 2023-06-08 10.085761 11.337197 0.193751
7 2023-06-08 10.085761 12.300000 0.626573
res:
交易日期 后复权价格 历史最低价 历史最高价 5分位成本 10分位成本…………90分位成本 95分位成本 加权平均成本 胜率
0 2023-06-08 10.085761 10.085761 12.3 10.245294 10.262309 12.3 12.3 11.747138 0.0
"""
# ===初始化需要返回的每日分布概况
res = pd.DataFrame()
res.loc[0, '交易日期'] = data['交易日期'].iloc[0]
res.loc[0, '后复权价格'] = data['当日价格'].iloc[0]
res.loc[0, '历史最低价'] = data['筹码价格'].min()
res.loc[0, '历史最高价'] = data['筹码价格'].max()
# ===计算个各个价格档位的筹码概况
data['累计占比'] = data['筹码占比'].cumsum()
# 每隔5%计算分位数占比
for pct in list(range(5, 100, 5)):
pct_float = pct / 100 # 计算百分位
# 找到首次大于这个分位的成本
res.loc[0, f'{pct}分位成本'] = data[data['累计占比'] > pct_float]['筹码价格'].iloc[0]
# 计算加权平均成本
res.loc[0, '加权平均成本'] = (data['筹码价格'] * data['筹码占比']).sum()
# 计算筹码胜率
if data[data['筹码价格'] < data['当日价格']].empty:
res.loc[0, '胜率'] = 0
else:
res.loc[0, '胜率'] = data[data['筹码价格'] < data['当日价格']]['累计占比'].iloc[-1]
return res
def cal_price_distribution(stock):
"""
计算筹码分布数据
:param stock: 股票代码
:return:
"""
# stock = 'sh600000.csv'
print(stock)
# ===读取数据
df = pd.read_csv(stock_path + stock, encoding='gbk', skiprows=1, parse_dates=['交易日期'])
# 只保留需要的列,避免数据太大
use_cols = ['股票代码', '股票名称', '交易日期', '开盘价', '最高价', '最低价', '收盘价', '前收盘价', '成交量', '成交额', '流通市值', '总市值']
df = df[use_cols]
# ===做一些计算筹码分布之前必要的准备
# 计算每日的均价
df['均价'] = df['成交额'] / df['成交量']
# 计算换手率
df['换手率'] = df['成交额'] / df['流通市值']
# 在首行插入发行价的信息
ipo = df.head(1).copy() # 复制一下第一行数据
ipo.loc[0, '交易日期'] -= pd.to_timedelta('1D') # 交易日期减1天,避免与原数据重复
# 发行价的开高低收都是同一个价格。
for col in ['开盘价', '最高价', '最低价', '收盘价', '均价']:
ipo.loc[0, col] = ipo.loc[0, '前收盘价']
ipo.loc[0, '换手率'] = 0 # 首日的换手率先给成0
df = pd.concat([ipo, df], ignore_index=True)
# 计算每日保留率 = 1-换手率
df['保留率'] = 1 - df['换手率']
# 特殊处理,第一天的换手率是1(所以第一天的换手率和保留率都是0)
df.loc[0, '换手率'] = 1
# ===计算涨跌幅 & 后复权价格
df['涨跌幅'] = df['收盘价'] / df['前收盘价'] - 1
df['涨跌幅'].fillna(value=0, inplace=True)
# 计算复权因子
df['复权因子'] = (df['涨跌幅'] + 1).cumprod()
df['收盘价_复权'] = df['复权因子'] * (df.iloc[0]['收盘价'] / df.iloc[0]['复权因子'])
df['均价_复权'] = df['均价'] / df['收盘价'] * df['收盘价_复权']
# 删除不必要的列
df.drop(columns=['开盘价', '最高价', '最低价', '收盘价', '前收盘价', '成交量', '成交额', '流通市值', '总市值', '均价', '涨跌幅', '复权因子', '收盘价_复权'],
inplace=True)
# ===根据历史数据,推出哪些交易日需要计算筹码分布
# 最终生成的数据的导出路径
situation_file = root_path + '/data/筹码分布概况/' + stock
# 如果已经有已经生成好的历史数据,就读入历史数据,在历史数据的基础上加上最新的筹码分布(加快计算量)
if os.path.exists(situation_file):
# 读取历史数据
his_df = pd.read_csv(situation_file, encoding='gbk', parse_dates=['交易日期'])
his_date = sorted(his_df['交易日期'].to_list()) # 在历史数据中,找出已经算过筹码分布的数据
now_date = sorted(df['交易日期'].to_list()) # 在最新的K线数据中,列出所有的交易日
date_list = sorted(list(set(now_date) - set(his_date))) # 两个合集求差集,找出还没计算筹码分布的日期,进行增量计算
else:
# 如果没有历史数据,先定义个一个空的历史数据,再求出全量的筹码分布
his_df = pd.DataFrame() # 空的历史数据
date_list = sorted(df['交易日期'].to_list()) # 所有的交易日都需要计算筹码分布
# === 循环计算筹码分布
distribution_list = [] # 储存每日分布数据的的list
for date in date_list:
# 获取截止到当前日期的数据
temp = df[df['交易日期'] <= date].copy()
# 将数据逆序
temp = temp[::-1]
# 根据推倒出的公式计算出每筹码占比
temp['筹码占比'] = temp['换手率'] * temp['保留率'].cumprod() / temp['保留率']
'''
价格相同的地方,将筹码相加汇总,得到每日筹码
dis_res:
均价_复权 筹码占比
0 10.085761 0.009457
1 10.099691 0.017482
……………… ………………
6 11.337197 0.193751
7 12.300000 0.626573
'''
dis_res = pd.DataFrame(temp.groupby('均价_复权')['筹码占比'].sum()).reset_index()
# 在数据中写入交易日期数据
dis_res['交易日期'] = date
# 将 均价_复权 重命名为 筹码价格
dis_res.rename(columns={'均价_复权': '筹码价格'}, inplace=True)
# 每天最新的价格等于temp的第一个价格
dis_res['当日价格'] = temp['均价_复权'].iloc[0]
'''
将每日筹码数据转为筹码概况数据
dis_res:
交易日期 当日价格 筹码价格 筹码占比
0 2023-06-08 10.085761 10.085761 0.009457
1 2023-06-08 10.085761 10.099691 0.017482
……………… ……………… ……………… ……………………
6 2023-06-08 10.085761 11.337197 0.193751
7 2023-06-08 10.085761 12.300000 0.626573
dis_sit_res:
交易日期 后复权价格 历史最低价 历史最高价 5分位成本 10分位成本…………90分位成本 95分位成本 加权平均成本 胜率
0 2023-06-08 10.085761 10.085761 12.3 10.245294 10.262309 12.3 12.3 11.747138 0.0
'''
dis_sit_res = cal_situation(dis_res)
# 将今日的分布概况添加到临时文件中
distribution_list.append(dis_sit_res)
# 如果没有筹码分布数据更新,直接return
if len(distribution_list) < 1:
return
# 将每日的筹码分布数据合并
dis_df = pd.concat(distribution_list, ignore_index=True)
dis_df = pd.concat([his_df, dis_df], ignore_index=True)
dis_df = dis_df.sort_values(by=['交易日期']).reset_index(drop=True)
dis_df.to_csv(situation_file, encoding='gbk', index=False)
return
以上代码调用入口是函数cal_price_distribution(code),读入股票代码的日线数据,自动计算出股票在所有交易日期的筹码分布。
代码存在两个小问题,一是计算速度,二是价格长尾。对于10多年日线数据的单只股票的计算,使用普通8核16g的计算机,计算需要40+秒。计算中会从当前交易日期追溯到上市的首日,且仅对浮点价格完全相同的数据进行合并,会形成一个很长的价格长尾list,不少占比已经非常低的价格仍然存在list中,影响了计算的速度和效率。
我们可以考虑对以上代码进行优化:对应交易日的价格,仅仅追溯距离当前n个时间窗口的价格进行计算筹码分布。这样可以大大优化计算速度,并且保留较好的计算精度。当n趋向无穷大时,与追溯到上市首日一致。通过优化,我们可以将10多年日线数据的计算时间,从40多秒优化到10秒。以下是优化后的核心代码:
def cal_pct_chip(row, df, num_step):
if row.name < len(df) - num_step:
d = df.iloc[row.name:row.name + num_step]
row['mean_price'] = d['amount'].sum() / d['volume'].sum()
if row.name >= 1:
prev_row = df.iloc[row.name - 1]
d['chip_ratio'] = d['all_chip_ratio'] * prev_row['turn'] / (prev_row['all_chip_ratio'] * prev_row['reserved_rate'] * 100)
else:
d['chip_ratio'] = d['all_chip_ratio']
# 插入首行
last_row = d.iloc[-1]
result = last_row['chip_ratio'] / last_row['turn'] * last_row['reserved_rate'] * 100
first_day = {'turn':1, 'reserved_rate':1, 'chip_ratio': result, 'day_mean_price': last_row['close']}
d = pd.concat([d, pd.DataFrame([first_day])], ignore_index=True)
#
dis_res = pd.DataFrame(d.groupby('day_mean_price')['chip_ratio'].sum()).reset_index()
# ===计算个各个价格档位的筹码概况
dis_res['acu_ratio'] = dis_res['chip_ratio'].cumsum()
# 计算分位数占比
for pct in [50, 90]:
pct_float = pct / 100 # 计算百分位
# 找到首次大于这个分位的成本
row[f'price_{pct}']= dis_res[dis_res['acu_ratio'] > pct_float]['day_mean_price'].iloc[0]
row['delta_price'] = row['price_90'] - row['price_50']
else:
row['mean_price'] = 0
row['price_50'] = 0
row['price_90'] = 0
row['delta_price'] = 0
return row
def add_chip_col(df, num_steps):
df['day_mean_price'] = df['amount'] / df['volume']
# 计算每日保留率 = 1-换手率
df['reserved_rate'] = 1 - df['turn'] / 100
# 特殊处理,第一天的换手率是1(所以第一天的换手率和保留率都是0)
df.loc[0, 'turn'] = 100
# 将数据逆序
temp = df[::-1].copy()
temp.reset_index(drop=True, inplace=True)
# 根据推倒出的公式计算出每筹码占比
temp.loc[:, 'all_chip_ratio'] = temp['turn'] / 100 * temp['reserved_rate'].cumprod() / temp['reserved_rate']
df = temp.apply(cal_pct_chip, axis=1, args=(temp, num_steps))
df = df[::-1]
df = df.drop(['reserved_rate', 'all_chip_ratio', 'day_mean_price'], axis=1)
df.reset_index(drop=True, inplace=True)
return df以上代码调用入口是函数add_chip_col,其中参数num_steps指定了使用距离当前交易日多久的最近的时间窗口进行筹码计算。
价格筹码交易策略
有了价格筹码的计算,我们可以使用价格筹码尝试进行交易策略的定制。传统的思想认为主力资金对股票的操作有吸筹-拉升-派发三个阶段。这个思想其实已经有点过时,但是其中对于筹码的看法还是可以借鉴的。对于股票的买入点,我们倾向选择筹码集中度高,长期横盘的股票。于是,我们定制了以下策略进行选股:
筹码10分位相对收盘价涨幅> -10%
筹码90分位相对收盘价涨幅 < 10%
收盘价格>平均筹码价格
选出来股票后,我们人工观察下股票的走势和筹码分布:

价格筹码选股
看起起来还不错,符合我们的选股条件。进一步地,由于我们的资金有限,当有多只股票符合条件时,我们需要有一个排序策略,优先选择其中的股票进行交易。这里,我们简单地按股票市值进行排序,选择股票市值小的股票进行交易。对于卖出条件,我们先简单地按照持股3天后自动卖出。
有了交易条件,我们可以对策略进行测试了。我们选择所有A股的股票进行测试,测试时间范围从2019.1-2023.8。以下是我们的测试结果:
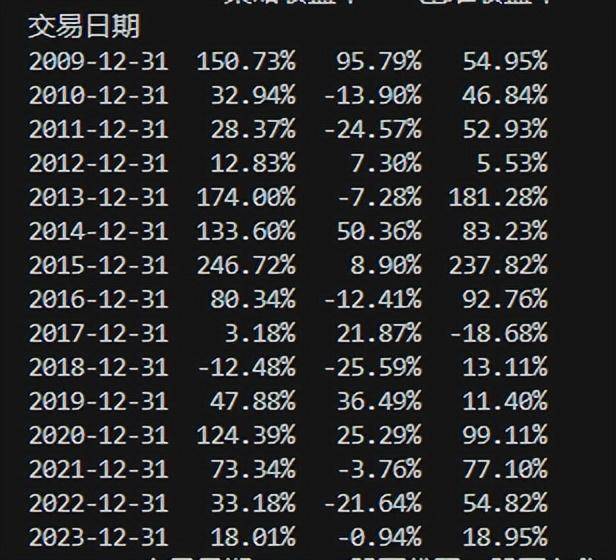
价格筹码策略测试结果
数据看起来很不错。简单的策略,但是每年的收益等领先于大盘,创下了10年百倍的收益!当然,策略还有很多不完善的地方,需要大家进一步优化:
- 只使用了筹码单个特征进行策略定制。引入更多有效的特征,将对策略有明显提升。
- 策略的参数有待优化调整。策略使用的10,90分位和10%等参数,是直接拍脑袋定的,可以依据历史数据进一步优化调整。
- 卖出点的选择粗暴简单。为了展现策略,简单使用了持股3天卖出。查看交易记录发现,卖出点并发最优,有卖出后又买入,卖出后价格继续上涨的。
- 买入先选择可以进一步优化。查看交易记录发现,许多交易的买入点也不是很好。策略选择的是长期横盘且价格筹码集中的股票。买入后,股票可能继续趴着,并没有开始上涨。可以考虑加入一个近期的涨幅条件。
通达信公式选股
鉴于以上的Python代码有一定的门槛,有些读者并没有编程基础。本狐再提供一个通达信的选股公式,供大家参考使用。公式可以很方便地引入到各个股票行情软件中。
CONDA:=COST(90) < CLOSE*1.1 AND COST(10) > CLOSE*0.9 AND CLOSE > COST(50) AND (COST(90)-COST(10))/COST(50)<0.3;
CONDB:=FINANCE(40)<100000000000000;
CONDC:=(C-REF(C,3))/REF(C,3)*100 < 3;
CONDA AND CONDB AND CONDC;代码中第一行选择了价格筹码集中度高的股票;第二行选择市值小于10亿的股票,用于缩小范围;第三行增加了最近有一个3%的涨幅,表示股票开始有向上启动的迹象。以上参数,大家可以自行调整,公式也可以很方便地进行数据测试和验证。
值得注意的是,这只是一个demo公式,仅供参考。以此进行操作,很可能不能保证盈利。
在本篇文章中,我们展示了通过股票价格筹码计算定制量化交易策略,并提供了核心的python计算代码和通达信的选股公式。通过13年的历史数据测试,我们验证了策略的有效性,在13年中,大幅跑赢大盘,取得了1年百倍的收益!展示的策略大家可以在此基础上,进一步优化和完善。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/289028
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!