
一 本文摘要
本文介绍了一个新的任务——政策检索,并引入了中国股市政策检索数据集(CSPRD)。这个数据集包含了经验丰富的专家对700多个招股说明书段落和超过1万份中国政策语料库中的相关文章进行了标注。我们通过实验使用了词汇、嵌入和微调的双编码模型,证明了CSPRD的有效性,并揭示了其改进的潜力。我们的最佳基准模型在开发集上取得了令人瞩目的成绩,MRR@10达到了56.1%,NDCG@10达到了28.5%,Recall@10达到了37.5%,Precision@10达到了80.6%。
这项研究揭示了CSPRD在股市政策检索中的重要作用。通过使用这个数据集,我们可以更准确地分析和理解政策对股票市场的影响,为投资者、金融机构和研究人员提供有力的决策支持。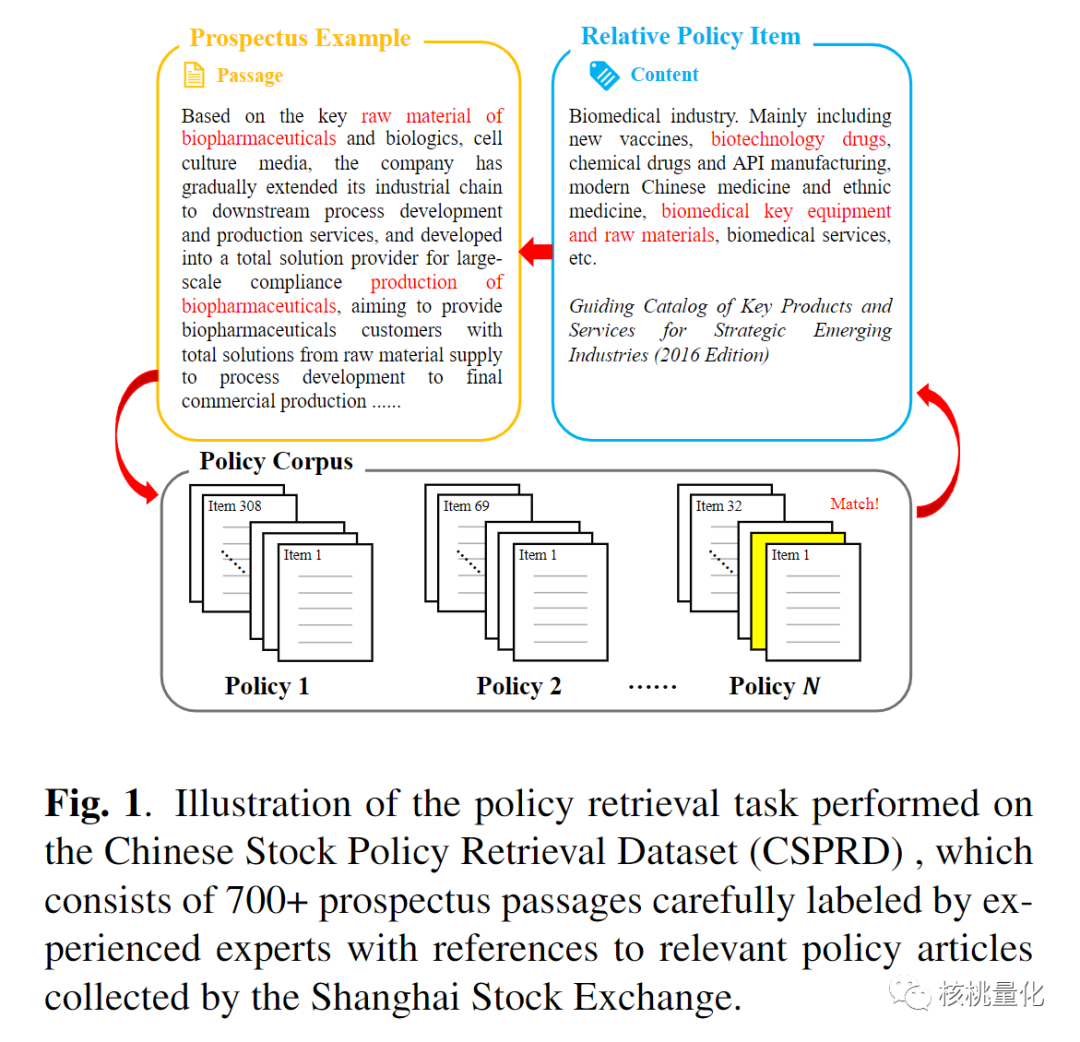
二 背景信息
近年来,预训练语言模型(PLMs)在稠密段落检索方法方面取得了重要进展。然而,目前的数据集主要用于测试通用常识的事实查询,而金融和经济等专业领域缺乏大规模高质量的数据集和专家注释,因此尚未被深入研究。我们的研究填补了金融和股市领域政策检索数据集的空白,引入了中国股市政策检索数据集(CSPRD)。
以往的检索数据集主要集中在通用常识检索上,对于金融和经济等专业领域的政策检索缺乏研究。此外,现有的文本检索方法主要采用词汇方法,而在开放领域问答中,稠密检索方法已被证明是有效的。
本文的研究动机是填补金融和股市领域政策检索数据集的空白,并探索预训练语言模型在该领域的应用。通过引入CSPRD数据集,我们可以研究检索模型与专业分析师在监管机构中的智慧和决策能力的配合程度。然而,政府政策和上市公司的招股说明书虽然是公开可访问的,但监管机构的审查过程往往是一个黑盒子,上市公司的匹配政策文章也不是公开可用的,这给收集这样的数据集设置了高门槛。
三 本文方法
CSPRD数据集包含了来自中国STAR市场上545家上市公司的709个招股说明书示例,以及10002篇中国政策文章。这个数据集为研究人员提供了一个基准,用于研究金融和股市领域的政策检索,并为改进模型提供了机会。通过这项研究,我们可以更好地理解在金融和经济领域中如何利用预训练语言模型,并为相关决策和研究提供有力支持。
为了对CSPRD数据集进行标注,研究人员采用了一种名为混合专家(MoE)选择系统的无监督模型。这个系统被用来为每个招股说明书段落选择排名前20的政策文章。他们还使用了一些数据处理技术来提取招股说明书和政策文件中相关的文本信息。无监督的MoE选择方法被用来评估招股说明书段落和政策内容之间的文本相似性。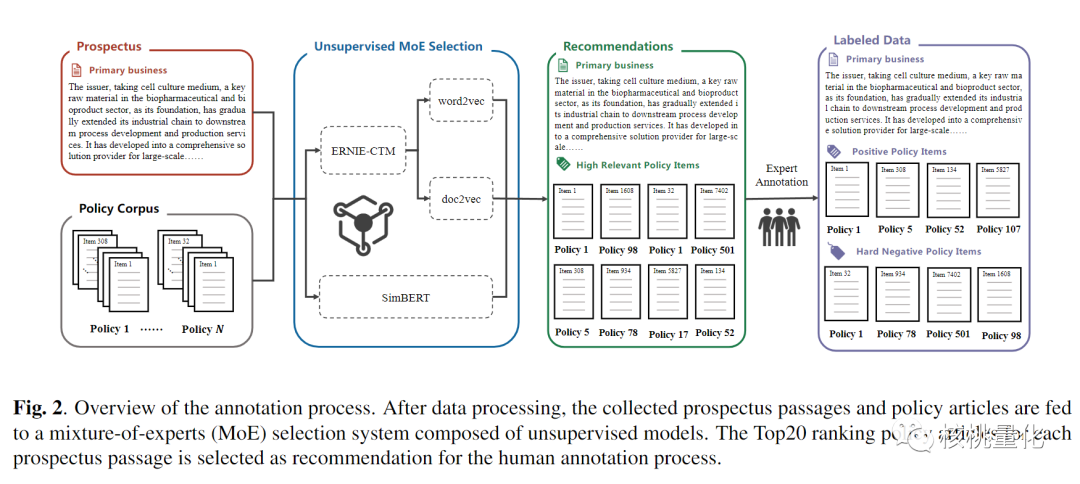
四 实验结果
在CSPRD数据集上,几种方法的检索基准显示,使用不同的预训练语言模型(PLMs)进行微调的模型取得了最佳性能。在CSPRD数据集上进行微调的RetroMAE模型在平均倒数排名(MRR@10)、归一化折损累积增益(NDCG@10)、召回率(R@10)和精确率(P@10)方面取得了最高分。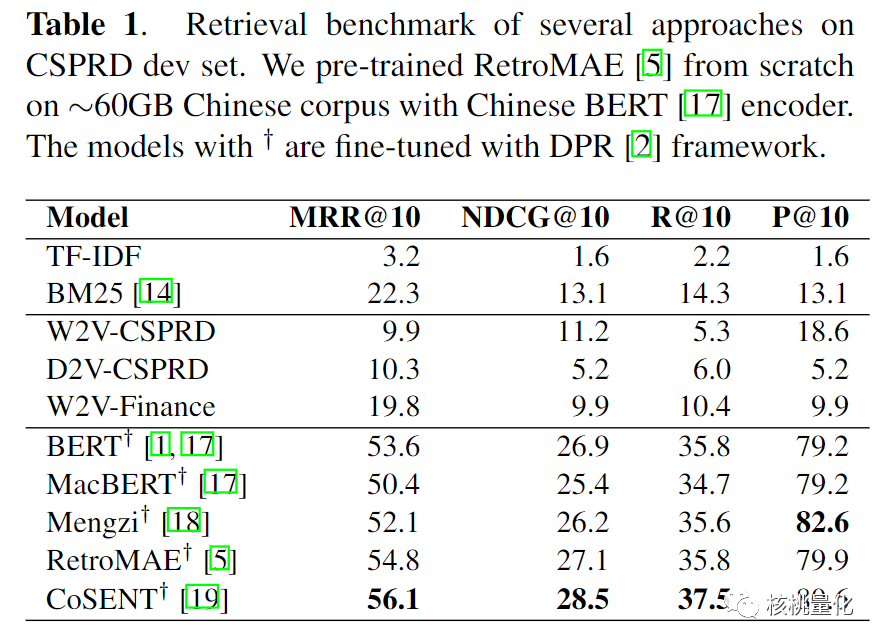
五 总结展望
本文介绍了中国股票政策检索数据集(CSPRD),该数据集由700多个招股说明书段落和相关政策文章组成,并由上海证券交易所的专家进行了仔细注释。研究人员评估了多种信息检索基准模型,并展示了CSPRD数据集的实用性和潜力。这项研究填补了金融领域自然语言处理数据集的一个重要空白,并为未来的政策检索任务的研究提供了奠定基础的工作。
通过CSPRD数据集,我们可以更好地理解在金融领域中如何利用预训练语言模型进行政策检索。这将为金融机构、投资者和研究人员提供有力的工具,帮助他们更准确地理解政策对股票市场的影响,以及相关公司在招股说明书中披露的信息与政策之间的联系。
未来,我们可以期待在政策检索任务领域的进一步研究。通过不断改进模型和算法,我们可以提高政策检索的准确性和效率,使其成为金融决策和研究的重要工具。此外,随着数据集的不断扩大和更新,我们将能够更全面地探索金融和经济领域的政策效应,为决策者提供更准确和可靠的信息。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111014
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





