
一 本文概要
在机器人领域,课程学习和模仿学习已经被广泛应用,但在处理高度随机的时间序列数据的控制任务方面的研究还相对有限。金融控制领域面临着一个独特的问题,即无法通过采样来增加数据量,因为数据生成过程的访问是固定的。这与机器人领域不同,因为在物理系统中可以通过模拟和并行运行来增加数据量。因此,金融领域需要改进信号学习和优化方法,以应对有限而嘈杂的数据。
本文将机器人领域中课程学习和模仿学习的思想引入到金融控制领域,并使用无模型的强化学习方法。通过这种方法,研究人员发现在金融控制任务中取得了显著的性能改进。研究人员还在两个代表性的数据集上进行了实证研究,通过理论和实证研究证明了这些方法的有效性。这对于优化投资决策具有重要意义,并有望在金融领域的实际应用中取得进展。
二 背景知识
课程学习(Curriculum Learning,CL)是一种训练深度学习和强化学习系统的强大工具,它受到教授人类学生的启发。这种方法通过逐渐引入越来越困难的数据,来帮助网络从简单到复杂地学习。在机器人和计算机视觉领域,CL已经被广泛应用。最近,有人利用CL来预测金融收入,但在金融市场中使用CL的研究还很有限。
模仿学习(Imitation Learning,IL)是一种在机器人控制学习领域中非常重要的方法。它通过模仿专家的行为来训练学生(也就是我们要训练的代理)。IL在自主物理控制方面的应用非常广泛,尤其在没有准确标签生成器的情况下非常有用。在金融控制方面,一些研究也利用了IL,但对于IL在金融控制中的潜力还没有深入的探索。
强化学习(Reinforcement Learning,RL)是一种在金融控制方面取得显著进展的方法。它利用大量数据集和神经网络来提高金融决策的准确性,而不依赖于模型假设。RL与深度学习的结合在金融市场的复杂性中发挥着越来越重要的作用。已有一些关于RL在经济学和金融学中的应用的研究,展示了它如何解决这些领域中的复杂问题。
三 本文工作
3.1 信号和噪音
金融市场充满了不确定性和噪音,这使得在与市场互动的控制任务中变得困难。这种噪音和不确定性来自于多个因素,包括系统本身的随机性、市场信息的不完全可观测性以及建模的不完善。为了应对这些挑战,我们需要建立一个世界模型来精确地描述金融市场中的数据生成过程。然而,由于金融市场的复杂性和特征数量的庞大,我们无法将所有金融变量都纳入模型中。因此,我们需要寻找一种方法来提取出对我们感兴趣的变量集合,并且这些变量的变动能够可靠地预测未来的市场走势。
我们将可交易证券的变动分解为信号和噪音两部分。信号是可以通过观察到的特征空间中的信号映射来近似预测的证券变动,而噪音则是不可预测的随机性。通过合理的映射函数,我们可以将市场的变动分解为受到先前时间步影响的变动、影响未来时间步的变动以及剩余的噪音变动。然而,当噪音与信号的比例增加时,训练基于梯度的学习模型变得更加困难。这会导致样本效率和准确性下降,同时方差增加。建模随机时间序列数据的挑战在于输入和标签空间中存在噪音。消除噪音是困难的,因为我们只能事后近似地进行信号和噪音的分解。也就是说,在我们获得未来数据之前,准确地分解当前数据的信号和噪音是不可能的。
因此,我们的方法旨在降低训练控制模型中的噪音,同时最小程度地影响信号。这样可以提高模型的准确性和效率。
3.2 马尔可夫决策过程

本文方法将投资组合控制视为一个马尔可夫决策过程,其中我们通过买入、卖出或持有一组证券与市场进行交互。我们使用离散的动作集合来决定我们对证券的操作,同时也考虑了离散的数量集合来表示我们买入或卖出的数量。每个证券都有一个对应的价格,我们根据市场反馈将当前状态转移到下一个状态。在投资组合优化中,我们假设投资组合规模和交易量相对较大,可以使用连续的动作空间来简化问题。我们使用权重集合来表示交易决策,这些权重决定了我们在不同证券之间分配资金的比例。
理想情况下,我们希望将所有相关变量纳入状态空间,以便为最佳策略提供有用的信息。然而,考虑到变量组合的无限可能性,我们往往会根据领域知识自主选择一些相关变量作为状态的一部分。在这种方法中,状态通常包括与证券相关的历史数据以及其他重要的宏观经济金融变量。我们将马尔可夫决策过程的细节以表格的形式表示,其中包括了滞后的证券数据和主要的宏观经济金融变量。通过这种方法,我们可以更好地理解和控制投资组合,以实现更好的投资回报。
3.3 金融决策中的模仿学习

在金融控制的模仿学习中,我们将学习过程分为两个阶段。第一个阶段是从未来数据中学习因果信号,第二个阶段是在给定约束条件下优化输出向量。为了更有效地学习,我们将这两个阶段分配给不同的学习者。
首先,有一个称为”oracle”的学习者。这个学习者可以访问未来数据,并确定最优的策略。它通过优化来满足约束条件的最优策略π*。然后,有一个称为”student”的学习者。它的任务是学习第一个阶段的因果信号。它通过最小化与oracle的不相似性来优化策略π。
我们使用基于学习的方法来优化控制任务的映射。其中一种方法是演员-评论家强化学习算法,它同时优化策略和值函数网络。这些方法非常适合金融控制的问题,因为它们提供了一个通用的框架。在训练过程中,我们使用了一个名为Oracle Policy Distillation(OPD)的算法。它通过最小化与oracle的不相似性来训练学生学习者的策略。这样可以减少训练中的噪声。
3.4 课程学习
我们在金融控制中采用了一种叫做”课程学习”的方法,来处理数据中的噪声。在传统的方法中,给学习者的标签是没有噪声的,但是这也导致了一些有用的信息被剔除了。我们尝试通过平滑训练数据来降低噪声的影响,同时保留有用的信号,以提高模型在未知数据上的表现。
我们尝试了两种数据平滑的方法:指数移动平均(EMA)和四舍五入。四舍五入是将数据取整,而指数移动平均是对数据进行平滑处理。我们更倾向于使用指数移动平均,因为它有更好的理论依据。在实现指数移动平均时,我们使用了一个递归的公式来计算平滑后的数据。我们还尝试了另一种叫做”反向平滑”的方法,它是受课程学习思想的启发。我们根据一个参数S来确定平滑的程度,然后在训练过程中逐渐减小平滑的程度。最后一个阶段不进行平滑处理。这样做的目的是让模型在不同平滑程度下进行学习,以适应不同噪声水平的数据。
四 实验分析
4.1 数据
我们选择了两个代表性的金融时间序列数据集来测试我们的想法。选择这些数据集时,我们考虑了交易量的大小,即这些金融变量在市场中的交易活跃程度。这是判断它们在金融市场中的重要性的一个可靠指标。第一个数据集包含不同投资类别和金融变量的组合,而第二个数据集则包含同一投资类别中的证券。我们将这两个数据集称为宏观ETF和商品期货环境。
4.2 约束
为了增加我们研究的可靠性,我们对每个数据集应用了两个硬性约束条件,以模拟现实世界中的投资组合优化问题。在数据集1中,我们设置了约束条件1:投资组合的总体最大杠杆倍数为1,也就是净敞口在-1到1之间。在数据集2中,我们设置了约束条件2:投资组合的总体最大杠杆倍数为2,也就是净敞口在-2到2之间。为了满足这些严格的约束条件,我们采用了简单的线性归一化方法。当然,也可以使用softmax方法来实现。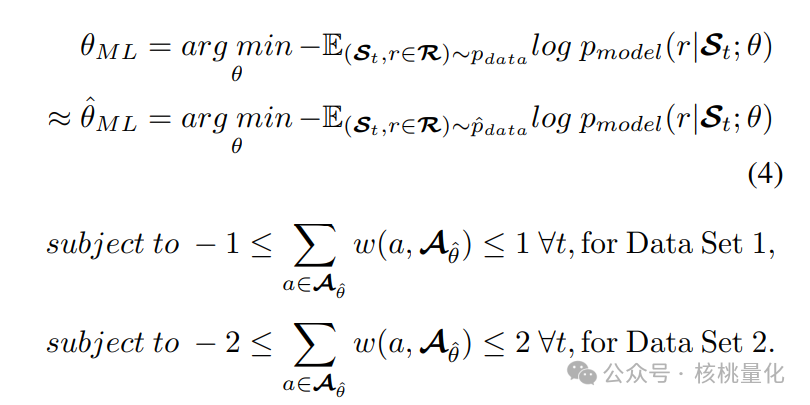
4.3 实验分析
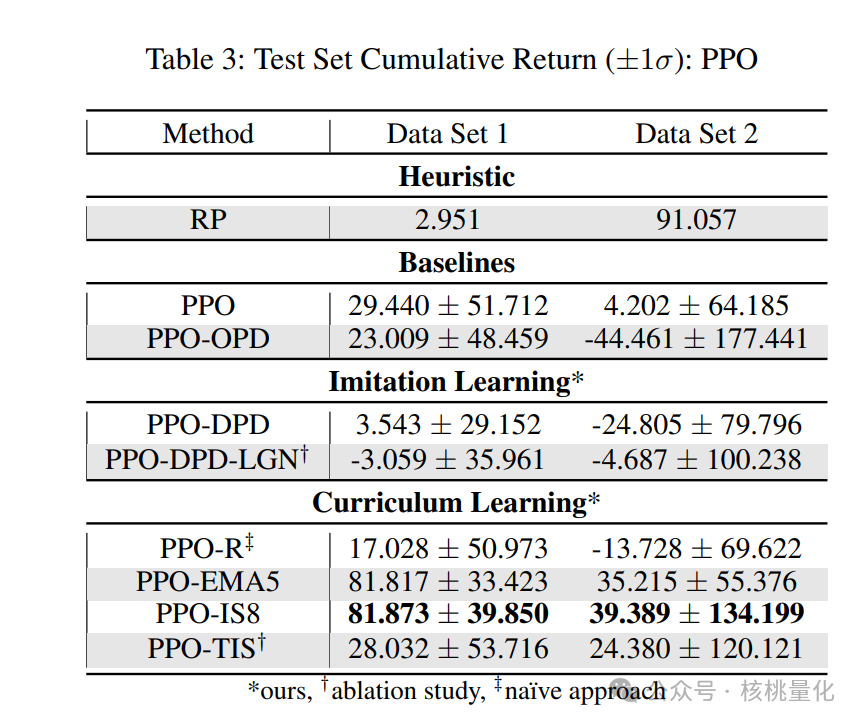
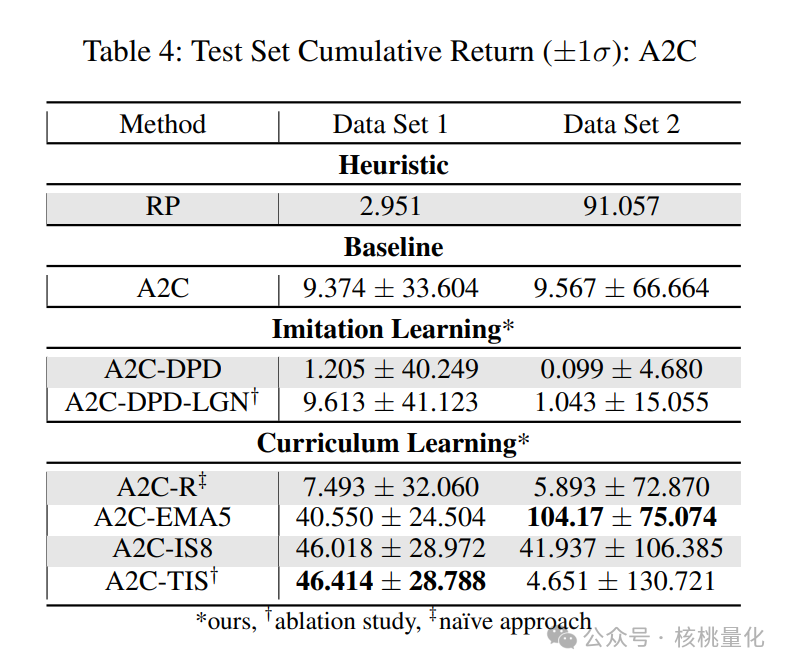
根据马尔可夫属性,我们可以将非顺序神经网络应用于代理程序。为了测试时间编码解码神经网络在MDP环境中的有效性,我们进行了一些初步实验,采用了LSTM架构。但是,我们发现LSTM并没有提高性能,反而导致训练和推理时间变慢。因此,我们选择了基于多层感知机(MLP)的方法。首先,我们将我们提出的方法与启发式方法和强化学习基准进行了比较。启发式方法是重新平衡投资组合(RP),而强化学习基准分别是没有模仿学习(IL)和课程学习(CL)。重新平衡投资组合是金融控制中常用的方法,已被证明可以击败大多数专业投资经理。模仿学习中的最新基准是OPD,而课程学习中的基准有TRPO-R、TRPO-EMA5、TRPO-IS8和TRPO-TIS。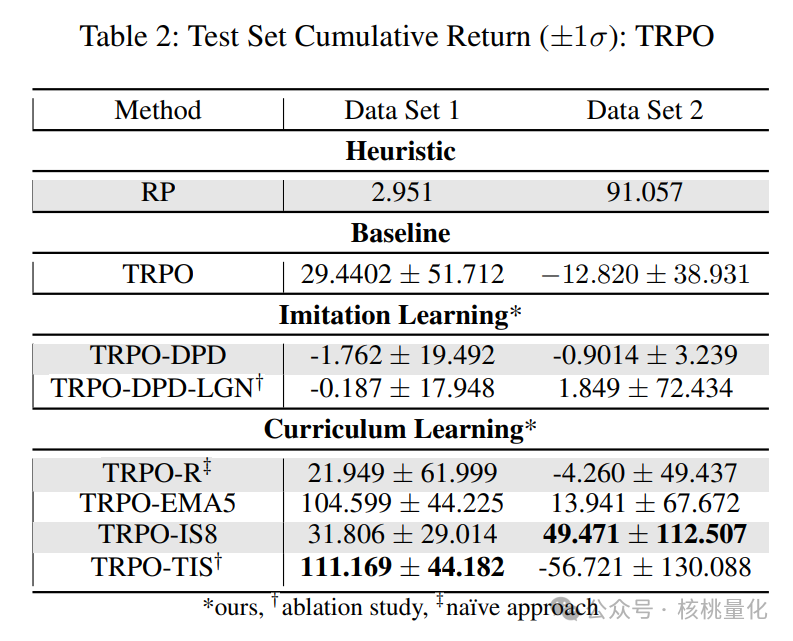
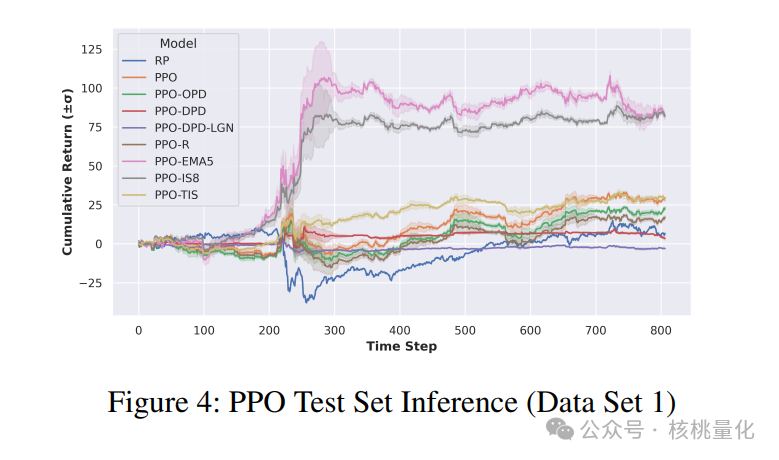
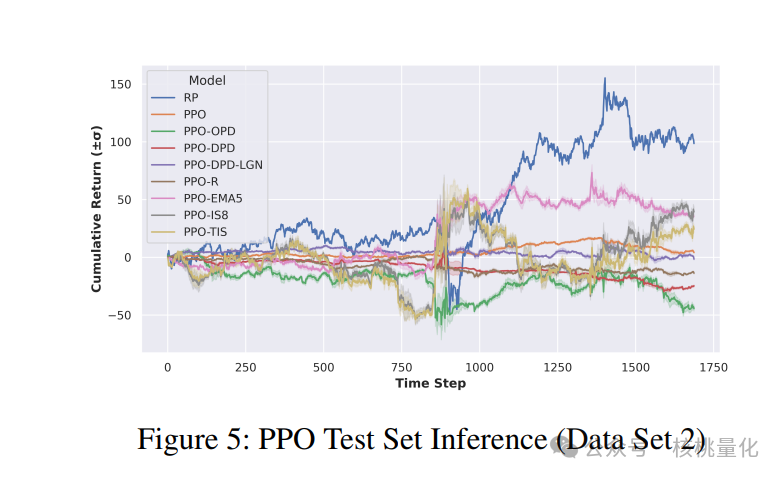
五 总结展望
目前的结果展示可能存在非平稳的分解情况,这意味着鲁棒的课程学习方法将从动态地调整平滑程度在时间上获益。此外,目前只有少数平滑方法在实证测试中被探究。因此,我们鼓励未来的研究尝试其他平滑方法,并分析这些平滑技术背后的理论原理。
未来的研究可以探索更多关于信号和噪声分解的非平稳性质,尝试其他平滑方法并解析其理论原理,以及将所提出的方法推广到其他学习任务和领域。这些研究将进一步拓展我们对这个领域的理解和应用,为我们提供更多解决问题的方法和工具。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111049
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!





