
一 本文摘要
时间序列预测在许多领域中都非常有用,比如经济学和气象学。这些领域的数据通常都有时间上的模式。然而,以往的研究往往忽视了动态模式的多样性,也就是不同粒度的变化,导致信息利用不充分。因此,在时间序列预测中,多粒度学习的方法还没有得到充分的探索。本文中,我们提出了一种名为”多粒度残差学习框架(MRLF)”的方法,用于更有效地进行时间序列预测。对于给定的时间序列,不同粒度的表示之间往往存在一些重叠和差异。由于存在信息冗余,简单地将不同粒度的数据进行拼接或组合可能会导致模型过于依赖冗余的粗粒度趋势信息。因此,我们设计了一种新颖的残差学习网络,通过粗粒度数据来建模细粒度数据的分布。通过计算多粒度数据之间的残差,我们可以去除冗余的信息。此外为了解决有效性差异的问题,我们引入了一种自监督目标来估计置信度,这样可以更有效地进行优化,而无需额外的注释工作。
本文实验使用了两个真实世界的数据集:从量化投资平台Qlib收集的股票数据集和UCI电力数据集,实验结果证明多粒度信息科研显著提高了时间序列预测的性能。
二 背景知识
2.1 时间序列预测任务
时间序列预测是指根据过去的数据来预测未来的数据。这在很多领域都非常重要,比如金融市场、气候预测、电力需求等。过去的研究主要关注单一粒度的数据,也就是在同一级别的时间上进行预测,比如用每日用电量数据预测每日用电量,用每日的股票数据预测每日股票趋势。然而,多粒度数据通常包含了更详细的信息,这对于准确预测非常重要。
我们想研究如何利用多粒度数据来提高时间序列预测的准确性。但是,多粒度数据之间存在信息冗余,即粗粒度数据包含了细粒度数据的信息。如果简单地将多粒度数据拼接在一起,模型很容易受到冗余的粗粒度趋势信息的影响。然而,由于多粒度数据的异质性,去除冗余信息并不容易。另外,不同粒度数据的有效性和效果通常随着时间的变化而变化。因此,我们需要判断特定粒度数据在特定时间的预测是否可信。
2.2 现有方法
在时间序列预测领域,有两种主要的方法:传统方法和基于深度学习的方法:
-
传统方法是利用参数模型,例如自回归模型(AR)、自回归移动平均模型(ARIMA)、指数平滑模型或结构时间序列模型,来预测时间序列数据。这些方法只能捕捉线性关系,对于复杂的非线性关系表现不佳。 -
基于深度学习的方法则使用深度神经网络来学习时间序列数据中的非线性模式。常用的深度学习模型包括循环神经网络(RNN)和其变体(如长短期记忆网络(LSTM)和门控循环单元(GRU)),卷积神经网络(CNN)以及基于自注意力的Transformer模型。这些模型可以更好地捕捉时间序列数据中的复杂关系,提高预测准确性。
三 本文贡献
现有的方法大多只关注单一粒度的数据,即使用相同粒度的历史特征来预测未来趋势。我们提出了多粒度学习的方法,利用不同粒度的历史数据进行预测。这意味着我们可以使用更细粒度的数据来丰富模型的信息。通过多粒度学习,我们可以将不同粒度的数据映射到未来的趋势空间中,从而提高预测的准确性。具体而言,我们的模型学习函数表示不同粒度的历史数据。每个粒度的数据包含过去T个时间步的特征,而每个时间步又由K个时间段的特征组成。通过使用多粒度特征,我们可以更全面地捕捉时间序列数据中的模式和趋势。
本文的主要贡献包括以下几点:
-
我们研究了时间序列预测中多粒度数据的重要性。在我们所了解的研究中,很少有人专注于如何动态地融合多粒度数据来进行时间序列预测,而我们的研究填补了这一空白。 -
我们提出了一种创新的跨粒度残差学习网络,旨在消除多粒度数据中的语义重叠问题,从而更好地利用信息。此外,我们还设计了一个自监督的置信度估计器,用于判断每个粒度数据的有效性。 -
我们对真实世界的数据集进行了广泛的实验,明确地证明了我们的框架在预测准确性方面相对于现有技术的优势。我们的实验结果表明,通过使用多粒度数据和我们的跨粒度残差学习网络,我们能够更准确地预测时间序列数据的趋势和模式。
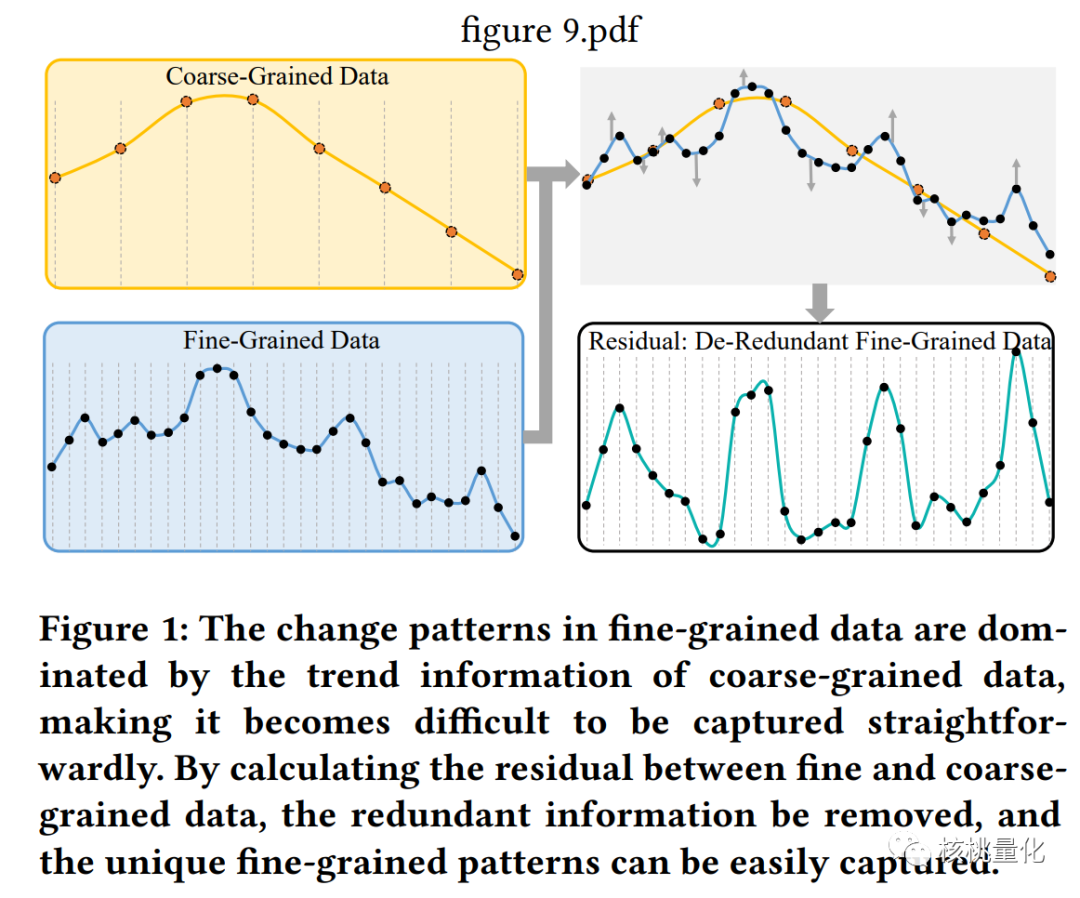

四 本文工作
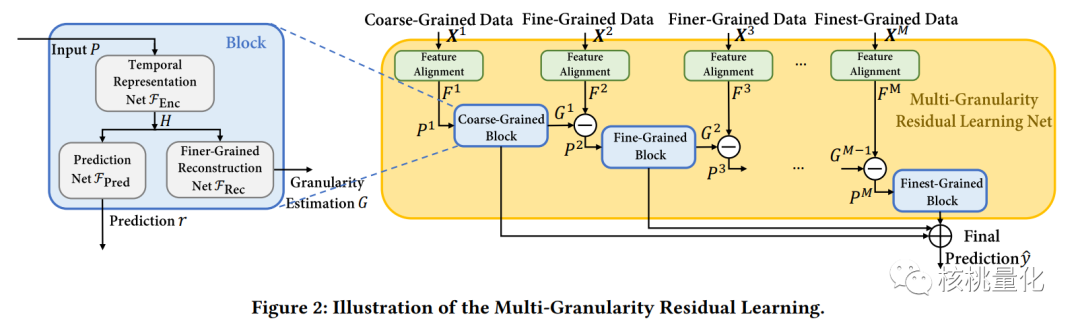
上图多粒度残差学习框架(MRLF)的整体架构,下面我们详细分析每个组件的设计:
-
多粒度残差学习:给定多粒度数据{X1,…,XM},其中X1到XM表示粗到细特征,多粒度残差学习过程探索不同粒度特征中隐藏的时间序列未来趋势的信息。如上图所示,为了充分利用每个粒度的信息,该过程包含多个具有相似结构的块(蓝色矩形),每个块负责学习特定粒度的信息。由于不同粒度数据之间存在严重冗余,可能导致模型受到冗余的粗粒度趋势信息的主导,我们提出了一种级联方式从粗到细堆叠块,并设计了一种新颖的跨粒度残差学习方法,确保每个块的输入只包含特定粒度的唯一信息。 -
特征对齐:由于不同粒度数据的维度不一致,我们将它们对齐到相同的空间,以便后续的残差学习操作。如上图中的绿色部分所示,具体而言,我们对输入Xm ∈ RD×Km×T(表示粒度m的原始数据,T个时间步长)进行简单的线性变换Fm Linear,得到对齐后的特征表示Fm ∈ RD×K×T。特征对齐过程的公式如下所示: -
基本块:基本块的功能是学习特定粒度的知识。它的架构如上图的左侧所示。第m个块接受其相应的输入Pm,并输出rm和Gm两个结果。输入Pm表示粒度m的去冗余特征嵌入。输出rm旨在根据当前粒度m进行预测。输出Gm近似表示块对下一级粗粒度特征Fm+1的最佳估计,它指示模型已经学到的信息,并旨在通过删除对预测没有帮助的输入的冗余部分,帮助下游块学习更细粒度的特定知识。基本块内部由多个组件组成。第一部分是时间表示网络FEnc,它将顺序特征Pm进一步编码为特征嵌入Hm。FEnc的网络结构可以是灵活的,根据具体情况选择适当的模型。为了捕捉时间序列数据的时间特征,我们采用了一个包含两个GRU层的结构。第二部分是预测网络FPred,它以特征嵌入Hm作为输入,并输出特定粒度的预测结果rm,即rm = FPred(Hm)。预测网络负责根据当前粒度m的特征嵌入进行预测任务,例如时间序列的未来趋势或其他相关的预测任务。另一部分是更细粒度重构网络FRec,它以特征嵌入Hm作为输入,并输出下一级粗粒度特征Fm+1的更细粒度估计Gm,表示为Gm = FRec(Hm)。更细粒度重构网络旨在通过对当前粒度的特征进行重构,近似表示对下一级粗粒度特征的最佳估计。通过这种方式,模型可以通过删除对预测没有帮助的冗余部分,帮助下游块学习更细粒度的特定知识。在具体实现中,我们使用两个全连接层来建模预测网络FPred和更细粒度重构网络FRec。 -
跨粒度残差堆叠:在本文中,我们引入了一种新颖的残差学习方法来解决信息冗余的问题。在以往的残差学习方法中,层与层之间的堆叠是为了适应底层映射H(x),而我们的方法则是让堆叠的层适应残差映射F(x) := H(x) – x。我们提出了多粒度块的残差学习方式,以消除冗余。在我们的方法中,多粒度块是由多个堆叠的层组成的。在特殊情况下的第一个块中,输入是最粗粒度的特征嵌入,即P1 := F1。我们假设粗粒度数据本身就包含了关于细粒度数据分布的一些先验信息。因此,我们使用由粗粒度数据重构出的细粒度数据来模拟冗余信息。具体来说,我们让粒度估计Gm重新构建粒度为m+1的特征。然后,下一级的块(m+1)可以很好地去除之前块中近似表示先验信号的部分,从而使得下游块能够专注于学习更细粒度的特定知识。通过这种方式,我们能够消除冗余信息,并使模型能够更好地学习到细粒度的特征。图中的黄色矩形表示这个过程。 -
基本模型优化:通过将预测任务的均方误差(MSE)损失、跨粒度残差学习过程中的重构损失以及正则化项相结合,我们得到以下损失函数:
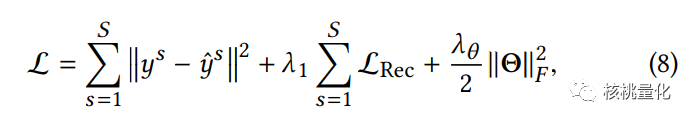
总的来说,多粒度残差学习框架(MRLF)是一种用于解决信息冗余问题的创新方法。它通过探索不同粒度特征中的未来趋势信息来学习隐藏的时间序列模式。该框架包括多个块,每个块负责学习特定粒度的信息,并采用级联方式从粗到细堆叠块,以避免冗余信息的干扰。特征对齐步骤用于将不同粒度的数据对齐到相同的维度空间。基本块包括时间表示网络、预测网络和更细粒度重构网络,以学习特定粒度的知识。跨粒度残差堆叠是该方法的核心创新,通过重新构建下一级粗粒度特征来消除冗余信息,使下游块能够专注于学习更细粒度的特定知识。最后,基本模型优化使用多个损失函数来优化整个模型的性能。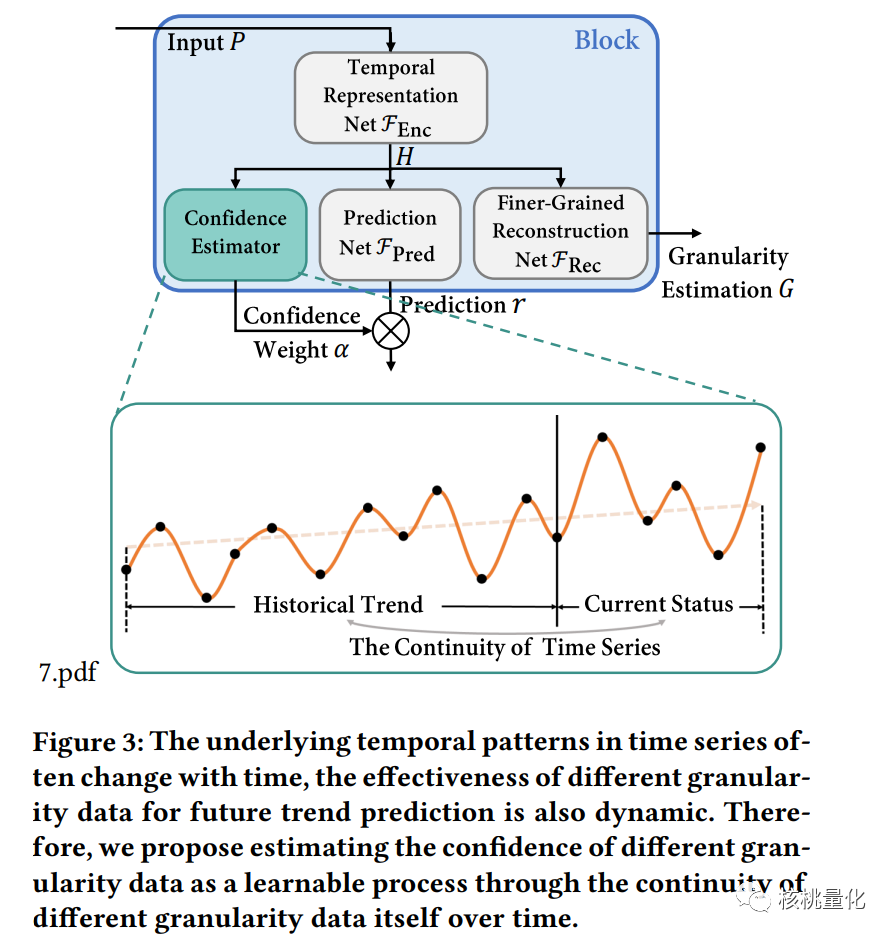
当我们进行时间序列预测时,不同粒度的数据对预测的准确性有不同的影响。为了更好地估计不同粒度数据的置信度,我们引入了一个称为置信度估计器的模块。该模块的作用是评估特定粒度预测的置信度分数。我们使用互信息来衡量每个粒度数据的一致性。互信息是一种衡量随机变量之间关系的指标,它可以捕捉到变量之间的非线性统计依赖关系。在每个时间步,我们将某个粒度数据的历史趋势表示为一个向量,并应用一个自回归模型来总结历史信息。通过最大化互信息的下界,我们可以估计出该粒度数据的置信度。具体的计算过程使用了神经网络估计器。我们定义了一个判别器,它通过神经网络来判断历史趋势和当前状态之间的关系。利用对比损失函数,我们最大化判别器的正确分类交叉熵,从而优化互信息的下界。
五 实验分析
实验设置
本文在两个真实世界数据集上进行了实验:UCI电力数据集和从量化投资平台Qlib收集的股票数据集。电力数据集包括321个客户在2年内的用电量数据,旨在预测每日用电量。股票数据集包括13年内749只股票的高频统计数据,旨在预测每日收益率。对于两个数据集,使用了不同粒度的输入特征。
实验结果
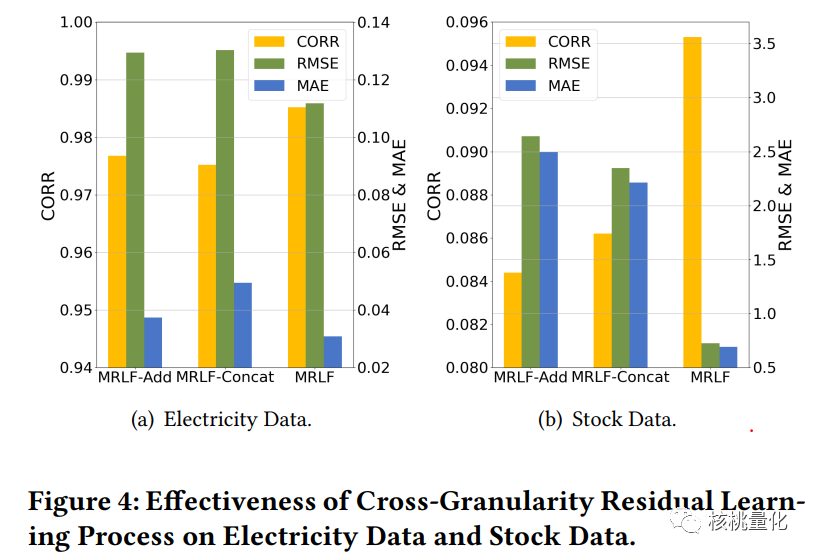
在该论文中,使用电力数据和股票数据进行了实验,比较了MRLF方法与其他方法的性能。评估指标包括相关性(CORR)、均方根误差(RMSE)和平均绝对误差(MAE)。实验结果表明,MRLF方法在性能上表现出竞争性,并且多粒度RNN和MRLF模型优于MRLF-Add和MRLF-Concat这两个变体。引入多粒度信息显著提高了时间序列预测模型的性能,但随着粒度数量的增加,增加粒度对性能的改进逐渐减弱。为了进一步提高模型的有效性,引入了置信度估计模块,它能够捕捉不同粒度数据的动态有效性。置信度估计模块能够评估不同粒度数据的置信度,并在预测时调整粒度数据的权重,从而提高预测的准确性。案例研究证明了置信度估计机制在捕捉特殊事件或时期中不同粒度的置信度权重变化方面的有效性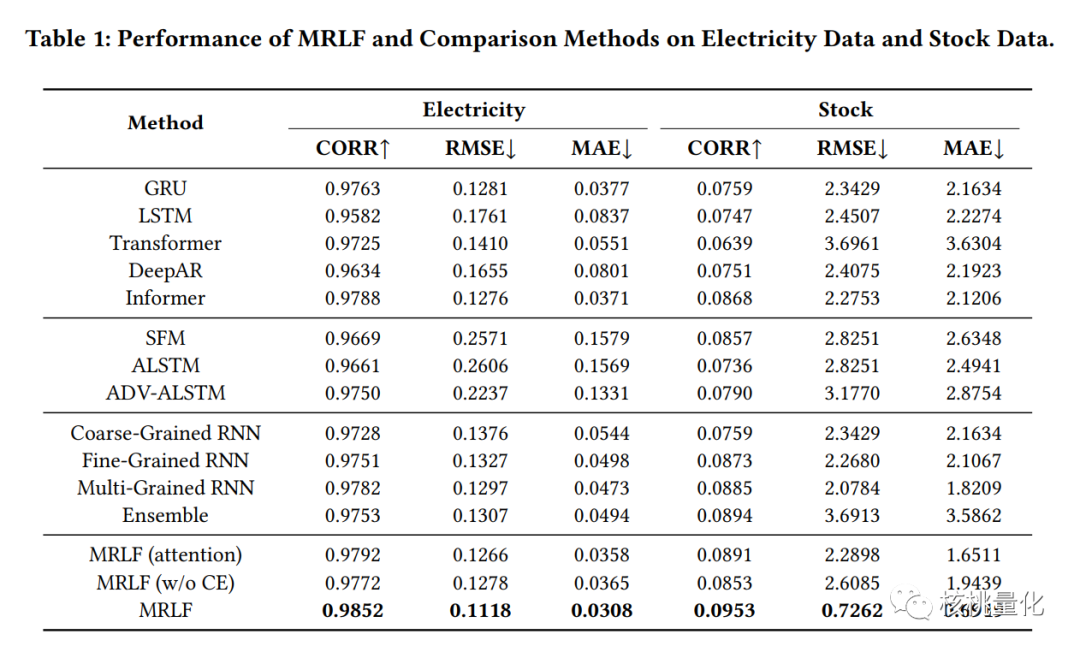
六 总结展望
本文展示了在时间序列预测中探索多粒度模式的重要性,并提出了一种多粒度学习框架。通过设计跨粒度残差学习方法,解决了多粒度数据之间的语义重叠问题,并引入置信度估计模块进一步增强了模型的有效性。实验证明,该方法在提升时间序列预测能力方面取得了良好的效果。
未来的研究方向包括将多粒度数据的生成过程变得可学习化,而不是手动指定。可以考虑将强化学习、元学习、信息论等方法融入建模过程,以利用多粒度输入数据提供更多信息,从而进一步改善预测效果。此外,还可以进一步探索多粒度模式对其他领域的应用,如金融、医疗等。通过将多粒度数据的特点应用于不同领域的时间序列预测问题,可以提高模型的泛化能力和适应性。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111005
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!