
之于AI量化,我的目标是“做出系列可以实战的策略”。
关键词:实战。市场可以是ETF,转债,股票,期货还是加密货币。
而且要主动甚至进攻性的在二级市场赚到钱的逻辑。
在ETF、转债和股票领域,目前看,可以统一为“多因子轮动模型”。就是通过多因子选标的,选综合排序得分高的持有,外加择时模型控回撤。当然如果是ETF,还可以引入战略大类资产配置的逻辑——构建一个绝对收益型投资组合。
先考虑ETF候选标的,行业轮动是比较合适的。按市值粒度粗了一点。行业的粒度刚好,而且市场风险变幻的时候,行业确实在分化。
我使用华泰研报里的行业分类:


选择出的ETF候选列表:
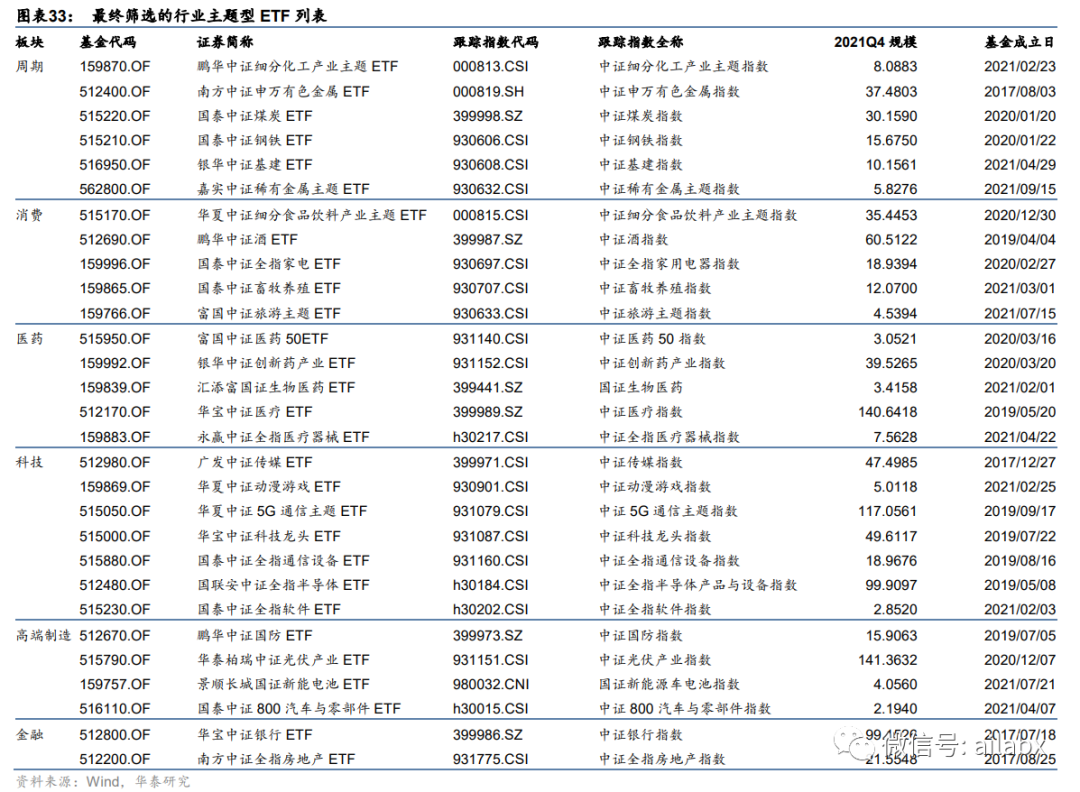
一共29支行业ETF。
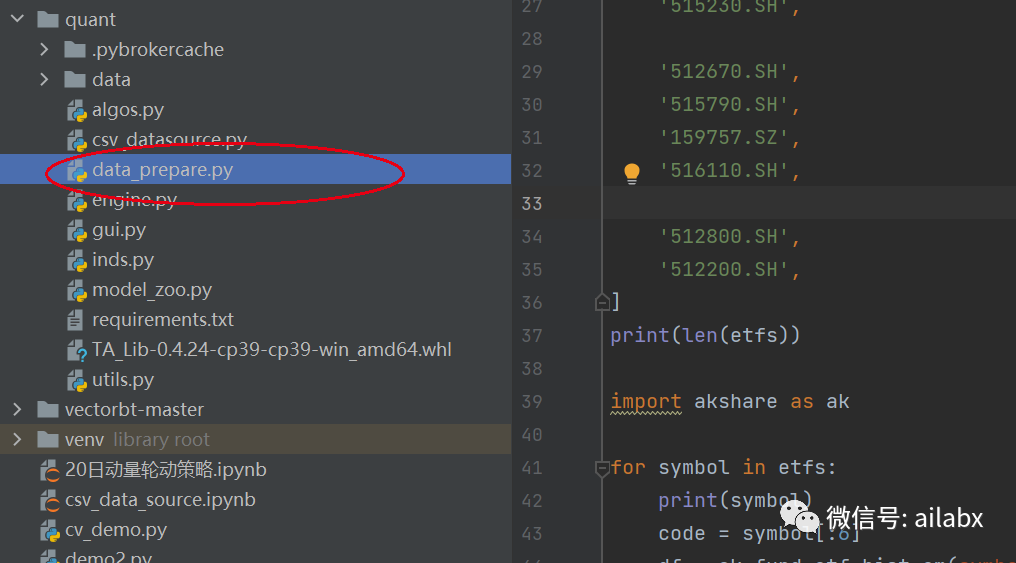
我们使用akshare获取它们的后复权数据,保存在csv里备用。
29支,使用akshare直接获得数据。
etfs = [
'159870.SZ',
'512400.SH',
'515220.SH',
'515210.SH',
'516950.SH',
'562800.SH',
'515170.SH',
'512690.SH',
'159996.SZ',
'159865.SZ',
'159766.SZ',
'515950.SH',
'159992.SZ',
'159839.SZ',
'512170.SH',
'159883.SZ',
'512980.SH',
'159869.SZ',
'515050.SH',
'515000.SH',
'515880.SH',
'512480.SH',
'515230.SH',
'512670.SH',
'515790.SH',
'159757.SZ',
'516110.SH',
'512800.SH',
'512200.SH',
]
print(len(etfs))
import akshare as ak
for symbol in etfs:
print(symbol)
code = symbol[:6]
df = ak.fund_etf_hist_em(symbol=code, period="daily", adjust="hfq") \
.rename(columns={"日期": "date", "收盘": "close", '开盘': 'open', '最高': 'high', '最低': 'low', '成交量': 'volume'})
df = df[['open', 'high', 'close', 'low', 'volume', 'date']]
df['symbol'] = symbol
df.to_csv('data/{}.csv'.format(symbol), index=False)
代码打包在工程里,请前往星球下载:(我这里下载的是“后复权”的数据,一般量化回测里使用后复权)
learn to rank (LTR) 排序学习
除了强化学习之外,我想,适合量化投资的模式应当是排序学习。这是分类、回归之外的第三类。但qlib框架似乎一直在做回归分析,而非排序学习。
为什么排序在金融量化的场景里更加重要?
我们把一堆因子,“预测”未来N期的收益率。回归就是预测N期收益率,而分类则是把未来收益率划分成group。——你可以近似认为这些group本身也是有排序的。
bigquant平台里的模块也叫StockRanker。
1、分类模型回答的是股票适不适合当前市场环境,而排序模型回答的哪支股票更适合;
2、在对事件发生的假设上,分类模型认为个股票之间相互独立且服从相同的分布,排序模型认为同组内部的股票是有关联关系和可以相互比较的;
3、从 Bayesian 的观点来看,分类模型刻画的是<市场,股票>的联合分布 P(市场,股票),而排序模型刻画的是条件分布 P(股票|市场);
4、从参数更新上来看,分类模型的参数更新由特征的绝对值确定,而排序模型由不同样本之间的特征的相对值确定。
我选择的框架是lightGBM,这个集成学习里最快的,最省内存的。catboost与xgboost的技术相对旧一些。而且lightGBM效果并不输前两者。
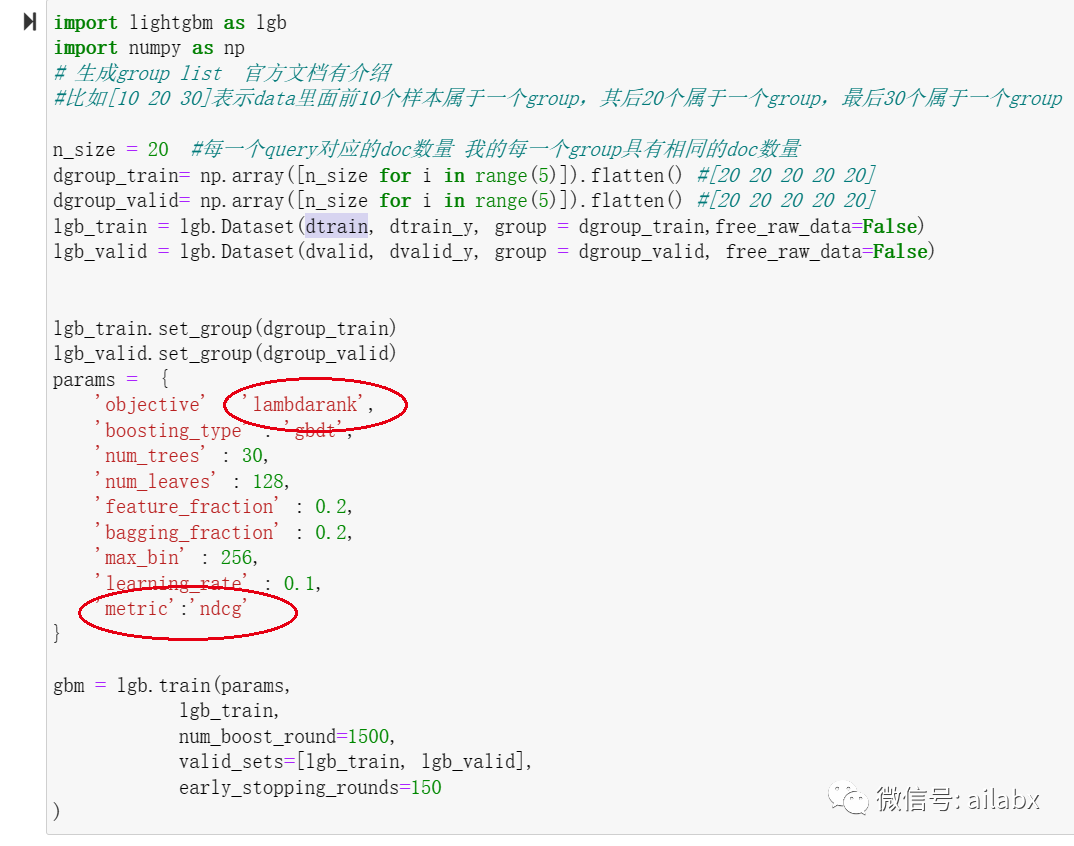
近期目标,基于lightGBM开发了L2R排序模块,后续再考虑因子的补充。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104122
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!