
replace()是pandas中的一个用于替换数据元素的函数,功能比较丰富,今天我们先学习它的的基本用法。
基本用法:dataframe.replace(被替换的值,新的值) 前面是需替换的值,后面是替换后的值。需要注意的是,替换后,原dataframe并没有改变,发生改变的是它的复制品。
下面演示一下,首先,读取数据:
import pandas as pd
df = pd.read_csv('stock.csv')
df返回:
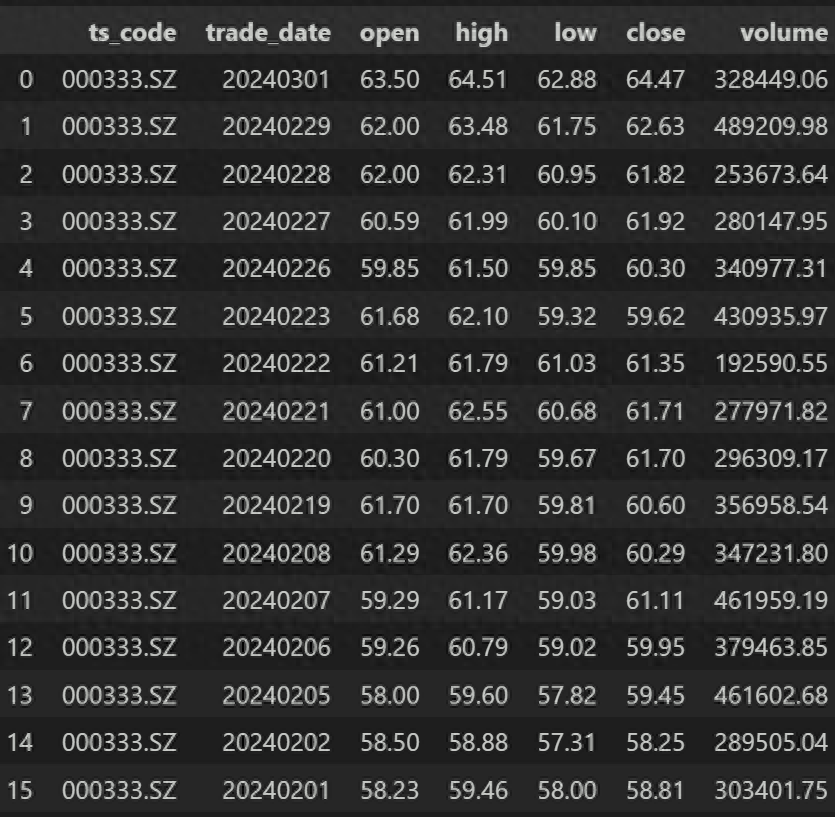

下面,我们就尝试着替换一下股票代码,将000333.SZ替换为600600.SH:
df.replace('000333.SZ','600600.SH')返回:
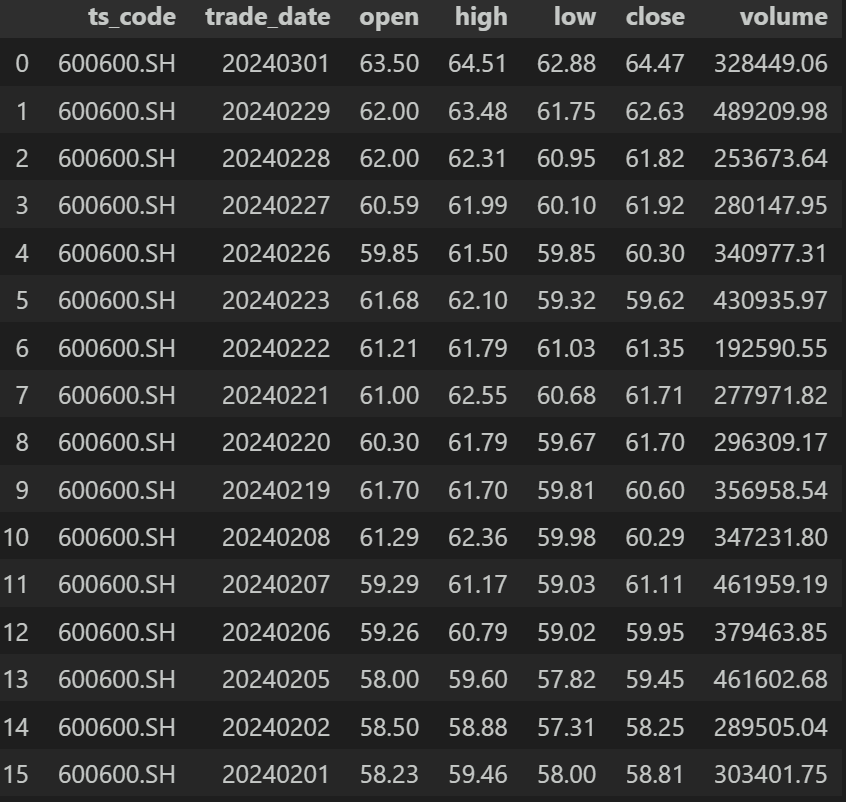
替换成功!
以上是全局替换,此外,我们还可以指定范围替换,如指定某一列中进行替换,其它列不受影响,如:
df['open'].replace(58,68)#将open这一列的数据58全部替换成68返回:
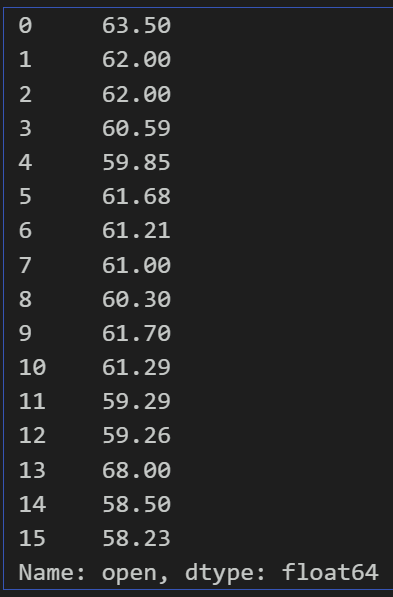
返回了新的open这一列,与原数据不同的是,将第13行的58替换成了68。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/74919
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!