
“每个人都有两次生命,第一次是活给别人看的,第二次是活给自己的,第二次生命常常从四十岁开始。真正的人生从四十岁才刚刚开始,在那之前,你只是在做调研而已。”
为自己而活,其实蛮难的。
除了少数含着金钥匙出生在罗马的人,多数普通人,一生大半时间,要为“温饱”而奋斗。
出售自己的时间,换取几天年假,一些假期,在人最多的时间,到不同的地方去打卡拍照。
如何跳出“老鼠赛跑”的困境?
特斯拉也曾一度生活困顿,理想主义者更需要金钱作为支撑。
二级市场门槛不高,但进阶极难,如果要以投资为生,非常建议以量化投资为生。
几个投资纪律:
闲钱投资,闲到什么程度,如有必要,这个投资的钱可以永远不动用。——确保长期主义,坚守投资纪律。
不上杠杆,坚决,坚定,不受诱惑。——杠杆首先放大的是风险,其次才是收益。
保持源源不断现金流。可以少,不能没有。——有长期投资组合与系统,有持续现金流管道,这样的自由人生可期!
继续咱们的全球大类资产配置的研报复现:【研报复现】年化27.1%,人工智能多因子大类资产配置策略之benchmark
如下是趋势动量,当取动量Top 2时候的表现:
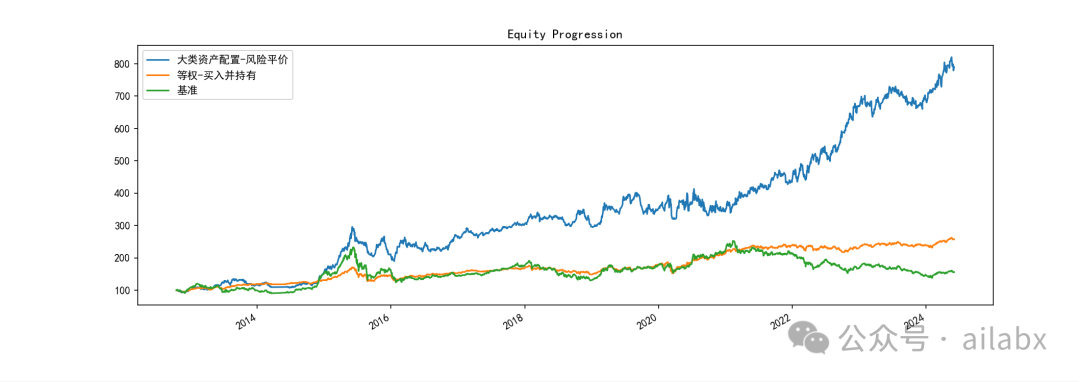

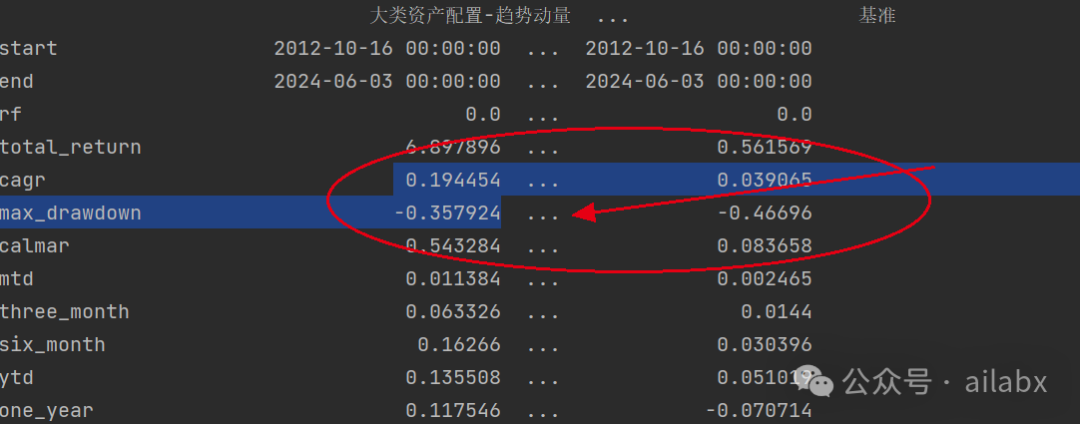
从某种意义上来讲,除了回撤相对大一些,35%之外,这个长期收益率是符合预期的。
——有几个人的收益能做到长期年化20%左右?
但是回撤对于持有体验,以及未来能否坚持下去,是一个巨大的考验与挑战。
from task import run_task, Task task = Task() task.name = '大类资产配置-趋势动量' task.desc = '' task.symbols = [ 'CL', # 原油 '^TNX', # 美十年期国债 'GOLD', # 黄金 '^NDX', # 纳指100 '000300.SH', # 沪深300 '000905.SH', # 中证500 '399006.SZ', # 创业板指数 '000012.SH', # 国债指数 '000832.SH', # 中证转债指数 'HSI', # 香港恒生 'N225', # 日经225 'GDAXI' # 德国DAX指数 ] task.algo_period = 'RunDaily' task.algo_weight = 'WeighEqually' task.benchmark = '000300.SH' task.topK = 2 res = run_task(task) print(res.stats) import matplotlib.pyplot as plt plt.rcParams['font.family'] = 'SimHei' res.plot() df = res.prices plt.show()
策略代码在如下位置:
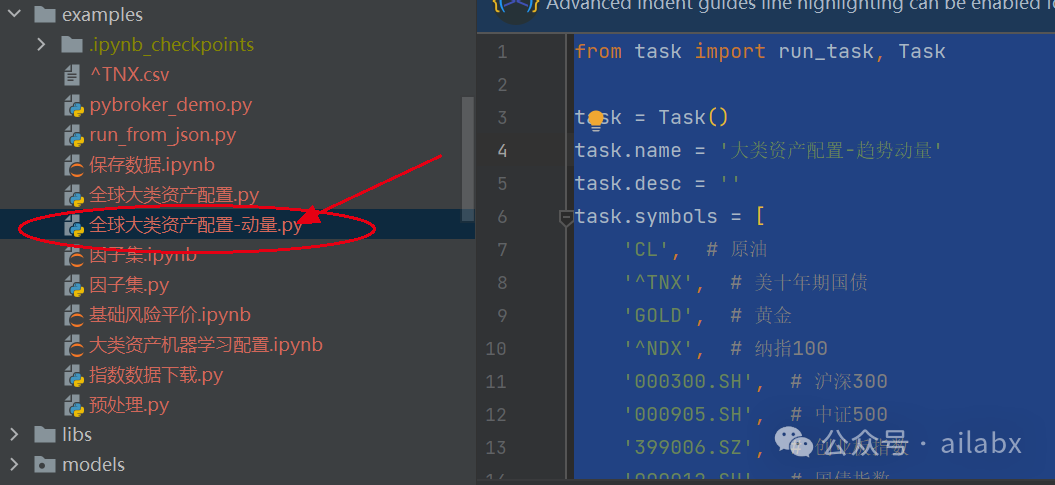
这时候,大家可能会想到择时,这是主动投资里大家很难抑制的冲动,比如加入动量择时,或者RSRS趋势择时,量化证明——结果并不好,反而更差了。
大家拿到代码可以自己试试。
吾日三省吾身
按法定退休年龄来看,男性是60岁,不扫除未来所谓——延迟退休。
之前还有几个同事聊起说退休是啥意思?退休就是拿自己的养老金——其实就是养老保险。
现在国人平均寿命是80岁。前20岁学习,成长;后20岁养老,中间工作40年。
但现在普遍遇到一个大的难题,40+,甚至35岁+就面临就业困难。
身边有几个case,有创业的兄弟,有金融圈的高管,也有互联网的老司机。
创业有时候,还不如失业,因为失业大概率还不会负债,如果没有家庭,那一人吃饭,全家不饿,也花不了多少钱。
但创业有时候是“鸡肋”状态,止损吧,这么多年的努力,好像曙光就在前方,再努力一下,没准春天就来了呢?继续吧,每个月实打实是要花出银子的。——这是当下很多小创业团队的现状。
再者,关掉了公司,做什么呢?
超级个体和一人企业,当下比较流行。
职场是越来越难了——你不知道什么时候会失业,这时候如果上杠杆(主要是买房,要慎重),创业又九死一生,也不想承受如此大的风险和压力,那怎么办呢?
但是呢,超级个体现在多数都是自媒体号主,有些是起号早,或者特别有特点,内容能力特别强等。
一个10万+的自媒体号,可能相当于一家小公司的赚钱能力。
另外就是有自己的互联网产品,这个适合有研发背景的个人,产品思维,商业化能力都需要具备。
构建自己的互联网产品+自媒体矩阵,恐怕是比较适合“一人企业”的模式。
自媒体矩阵是需要某于内容,而且是需要源源不断,持续更新的内容——当前是一个快速内容消费的年代。
很多自媒体运营好了,都是工作室模式。
日更要做到言之有干货是非常不容易的。
如果你本身提供产品或服务,围绕产品或服务做内容矩阵则相对容易,且商业化路径也会更加清晰。
如何提供互联网产品或服务呢?主要看世界需要什么,你想为世界做点什么——需求、痛点。
研报复现继续:【研报复现】年化27.1%,人工智能多因子大类资产配置策略之benchmark
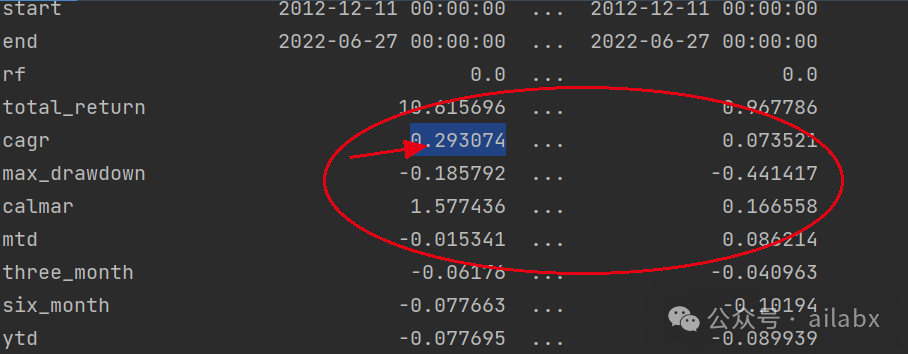
昨天调了一版参数,主要是lambda_l1, lambda_l2,防止过拟合的,有明显的效果:年化29.3%,最大回撤18.5%,还有继续优化的空间。

def train(df_train, df_val, feature_cols, label_col='label'): model = LGBMRegressor(boosting='gbdt', # gbdt \ dart n_estimators=600, # 迭代次数 learning_rate=0.1, # 步长 max_depth=10, # 树的最大深度 seed=42, # 指定随机种子,为了复现结果 num_leaves=250, # min_split_gain=0.01, lambda_l1=2, lambda_l2=2000 )
目前使用的是GridCV网格参数搜索:
ef adj_params(X_train, y_train): """模型调参""" params = { # 'n_estimators': [100, 200, 300, 400,500,600,700,800], # 'learning_rate': [0.01, 0.03, 0.05, 0.1], 'max_depth': range(10, 64, 2), # 'lambda_l1': range(0,3), # 'lambda_l2':[200,400,800,1000,1200,1400,1600,2000] } other_params = {'learning_rate': 0.1, 'seed': 42, 'lambda_l1': 2, 'lambda_l2': 2000} model_adj = LGBMRegressor(**other_params) # sklearn提供的调参工具,训练集k折交叉验证(消除数据切分产生数据分布不均匀的影响) optimized_param = GridSearchCV(estimator=model_adj, param_grid=params, scoring='r2', cv=5, verbose=1) # 模型训练 optimized_param.fit(X_train, y_train) # 对应参数的k折交叉验证平均得分 means = optimized_param.cv_results_['mean_test_score'] params = optimized_param.cv_results_['params'] for mean, param in zip(means, params): print("mean_score: %f, params: %r" % (mean, param)) # 最佳模型参数 print('参数的最佳取值:{0}'.format(optimized_param.best_params_)) # 最佳参数模型得分 print('最佳模型得分:{0}'.format(optimized_param.best_score_))
后续考虑使用hyperopt以及gluon来调参:
ModelTrainer:基于AutoGluon的多因子合成AI量化通用流程
代码与数据均在星球更新:
吾日三省吾身
昨天有同学留言说,现在这后半段有点鸡汤了。
我向来反感和警惕鸡汤,因此,我仔细反思了一下。
当下的大环境,大家越发渴望确定性,希望快速成功,赚钱,获得安全感。
但如果想听真话的话——这个世界没有“速成”之说。
成功也没有秘籍——没有武侠小说里,那种猴子肚子里掏出一本书,然后几天内达到别人30年的功力,然后年纪轻轻就独步天下——没有。
所谓心得,其实都是显学。
理财——多多储蓄,坚持长期投资,保持耐心。——没有了。
无论你想不想慢慢变富,你都会慢慢变老。区别在于,你是又老且富,还是又老且穷。
你说有没有财富自由快车道,——有,也是按3-7年往前看的。
有谁见过,花1000块钱不到,买一个策略或系统,然后赚1000万的?——谁这么跟你说,一定对你别有所图。
美好的东西都是需要时间这个变量来孵化。
它可能很慢,尤其在前期,慢到很多人没有耐心等到它发生。量化过程很慢,但越到后期才指数级复利加速。
如何度过这个孵化期——信念、系统。
种一棵树,最好的时间是十年前,其次是现在。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103235
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!