
最近开始一个系列,关于“因子挖掘”。
前面的文章里继续调优强化学习的环境,我们简单总结了一下这段时间的一些进展:
到目前,我们的框架已经实现了几个小目标:
1、支持csv/hdf5本地数据存储;
2、支持“因子”表达式,可以快速计算几百个特征,包含所有的ta-lib指标, numpy, pandas里的函数。
3、一个简洁的回测系统,支持“积木式策略”开发,一个策略我把它们拆成不同的部分,尽量让这里子部分通用化,像搭积木一样开始。
4、兼容传统规则型量化,机器学习——集成学习(lightGBM, xgboost等),深度强化学习(stable-baseline3),其实我已经把keras(tensorflow)安装好,写了DNN,LSTM几个模型。(代码统一在星球里下载和更新)
后来发现,模型只是因子的统计工具,以现在模型的统计能力而言,从集成学习(lightmGBM)到深度学习,它们的统计能力是完全足够的,唯独,你的数据够不够独特,你的特征工程好与不好罢了。
所以,发力的重点应该是因子的特征工程。
AI量化现阶段还无法做到像图像识别里,CNN直接抽取特征,因为图像里几乎包含了全量的信息,自然语言通过大模型整合世界知识,金融的世界比这个复杂,有经济运行之规律,有人性博弈之复杂。——一个超级复杂的系统。
这其实也有个好处,若是金融如同宏观物理世界那般精准,那么它的定律早就被挖掘殆尽,根本没有普通人的机会,这样的机会属于牛顿,爱因斯坦和霍金。
因为金融市场的极其不确定性,根本没有圣杯,普通人经常可以对着明星基金经理叫嚣,指手画脚。也不乏时代的弄潮儿,在某个特定的阶段盆满钵满,实现了自己的财务目标。
AI量化不是为了打败市场,而是跑过市场里的其他人,提供决策正确的概率。
今天继续gplearn。
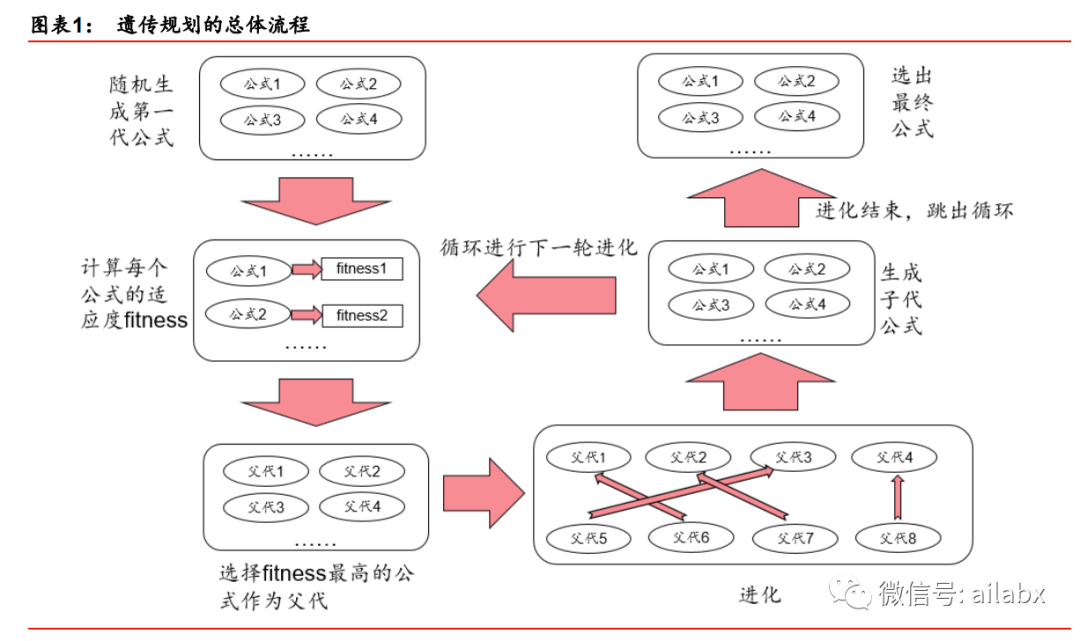
遗传算法,仿生自“天演论”——物竞天择,适者生存。
人类如何一步步走到今天,基因传承与变异,自然选择,优胜劣汰。
将遗传规划运用于选股因子挖掘时,可以充分利用计算机的强大算力,同时突破人类
的思维局限,挖掘出某些隐藏的、难以通过人脑构建的因子。作为一种“先有公式、后有逻辑”
的因子研究方法(就是数据挖掘),遗传规划或许能为选股因子研究提供更多的可能性。
传统的监督学习算法主要应用于特征与标签之间关系的拟合,而遗传规划则更多运用于特征挖掘(特征工程)。

对于使用遗传规划生成的选股因子来说,可以使用因子在回测区间内的平均 RankIC
或因子收益率来作为适应度。

要使用gplearn进行因子挖掘,需要对gplearn框架进行扩展改造,自定义函数集:

因子在每个截面上与 20 个交易日后收益率的 RankIC,
取 RankIC 均值为公式 F 的适应度。对遗传规划挖掘出的因子,进行更详细的单因子测试,包含 IC 测试、回归测试和分层
测试。尝试对因子含义进行解释。因子进行 IC 值衰减分析,相关性分析。————这里做的事情类似alphalens。
还是直接上代码:
from gplearn.genetic import SymbolicTransformer import gplearn as gp import time def gp_fit(df_train, label): init_function = ['add', 'sub', 'mul', 'div', 'sqrt', 'abs', 'sin', 'cos', 'tan'] trans = SymbolicTransformer( generations=5, # 整数,可选(默认值=20)要进化的代数 population_size=1000, # 整数,可选(默认值=1000),每一代群体中的公式数量 hall_of_fame=100, n_components=100, # 最终生成的因子数量 function_set=init_function, parsimony_coefficient=0.0005, max_samples=0.9, verbose=1, const_range=(10.0, 20.0), feature_names=list('$ ' + n for n in df_train.columns), random_state=int(time.time()), # 随机数种子 n_jobs=-1 ) trans.fit(df_train, label) print(trans) if __name__ == '__main__': from engine.config import etfs from engine.datafeed.dataloader import CSVDataloader symbols = etfs loader = CSVDataloader(symbols, start_date="20100101") df = loader.load(fields=['shift(close,-20)/close-1'], names=['label']) df.dropna(inplace=True) cols = ['open', 'high', 'low', 'close', 'volume'] gp_fit(df[cols], df['label'])
代码在工程的这个位置:
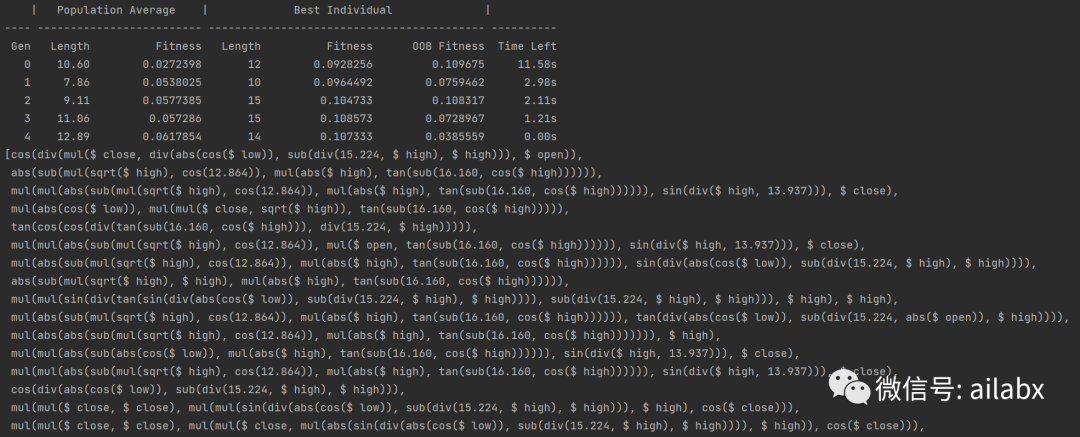
直接挖出一堆“因子”:
当然这里我们只用了gplearn内置的函数,加减乘除,绝对值,开方,正余弦等等。
扩展自定义函数集——如下只是示例,可以把我们expr里的函数都添加进来:
import numpy as np import pandas as pd from gplearn.functions import make_function def _andpn(x1, x2): return np.where((x1 > 0) & (x2 > 0), 1, -1) def _orpn(x1, x2): return np.where((x1 > 0) | (x2 > 0), 1, -1) def _ltpn(x1, x2): return np.where(x1 < x2, 1, -1) def _gtpn(x1, x2): return np.where(x1 > x2, 1, -1) def _andp(x1, x2): return np.where((x1 > 0) & (x2 > 0), 1, 0) def _orp(x1, x2): return np.where((x1 > 0) | (x2 > 0), 1, 0) def _ltp(x1, x2): return np.where(x1 < x2, 1, 0) def _gtp(x1, x2): return np.where(x1 > x2, 1, 0) def _andn(x1, x2): return np.where((x1 > 0) & (x2 > 0), -1, 0) def _orn(x1, x2): return np.where((x1 > 0) | (x2 > 0), -1, 0) def _ltn(x1, x2): return np.where(x1 < x2, -1, 0) def _gtn(x1, x2): return np.where(x1 > x2, -1, 0) def _if(x1, x2, x3): return np.where(x1 > 0, x2, x3) def _delayy(x1): return np.nan_to_num(np.concatenate([[np.nan], x1[:-1]]), nan=0) def _delta(x1): _ = np.nan_to_num(x1, nan=0) return _ - np.nan_to_num(_delayy(_), nan=0) def _signedpower(x1): _ = np.nan_to_num(x1, nan=0) return np.sign(_) * (abs(_) ** 2) def _decay_linear(x1): _ = pd.DataFrame({'x1': x1}).fillna(0) __ = _.fillna(method='ffill').rolling(10).mean() - _ return np.array(__['x1'].fillna(0)) gp_if = make_function(function=_if, name='if', arity=3) gp_gtpn = make_function(function=_gtpn, name='gt', arity=2) gp_andpn = make_function(function=_andpn, name='and', arity=2) gp_orpn = make_function(function=_orpn, name='or', arity=2) gp_ltpn = make_function(function=_ltpn, name='lt', arity=2) gp_gtp = make_function(function=_gtp, name='gt', arity=2) gp_andp = make_function(function=_andp, name='and', arity=2) gp_orp = make_function(function=_orp, name='or', arity=2) gp_ltp = make_function(function=_ltp, name='lt', arity=2) gp_gtn = make_function(function=_gtn, name='gt', arity=2) gp_andn = make_function(function=_andn, name='and', arity=2) gp_orn = make_function(function=_orn, name='or', arity=2) gp_ltn = make_function(function=_ltn, name='lt', arity=2) gp_delayy = make_function(function=_delayy, name='delayy', arity=1) gp_delta = make_function(function=_delta, name='_delta', arity=1) gp_signedpower = make_function(function=_signedpower, name='_signedpower', arity=1) gp_decayl = make_function(function=_decay_linear, name='_decayl', arity=1) funcs_set =(gp_delta, gp_signedpower, gp_decayl, gp_delayy, # gp_stdd, gp_rankk, # gp_corrr, gp_covv, 'add', 'sub', 'mul', 'div', 'sqrt', 'log', 'abs', 'neg', 'inv', 'sin', 'cos', 'tan', # gp_asin, gp_acos, gp_power, # gp_andpn, gp_orpn, gp_ltpn, gp_gtpn, # gp_andn, gp_orn, gp_ltn, gp_gtn, gp_andp, gp_orp, gp_ltp, gp_gtp, gp_if, 'max', 'min', ) # 用于构建和进化公式使用的函数集
添加之后的“挖掘”结果:
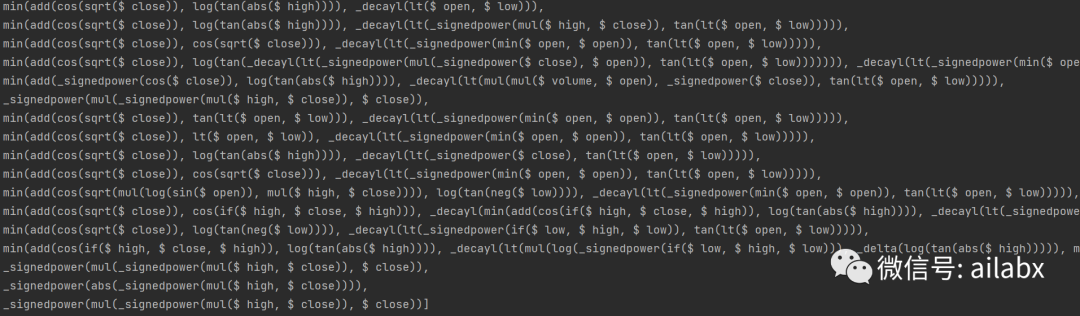
明天继续对这些因子进行单因子的ic分析,选出真实可用的因子,与我们的数据集贯穿起来。
关于人生的一些思考
人生棋局如投资,短期看跌宕起伏,云里雾里。拉长周期,回看三年、五年、十年,周期,规律,长期主义,一目了然。
“人无远虑,必有近忧”。
一个值得做的事情,坚持做1000天以上。
一件心烦的事情,过1000天你再看看。
时光不语,却带来或带走很多东西。
确实家家有本难念的经,都不容易。
条条大路通罗马,但有些人就出生在罗马。你所追求的可能只是有些人与生俱来的,但可惜的是,他可能又失去了追求生活的意义;你所拥有的习以为常的,却也可能是很多人梦寐以求的。
人生之舞台,怎么选都会有遗憾,我们要做的是:允许一切发生,顺其自然。
感恩,知足,专注于当下,专注于热情,专注于成长。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104102
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!