
今天的代码在如下位置:

代码与数据,请前往星球下载:
从finRL里的环境里借一个env出来看看,代码比我们实现的投资组合管理的要复杂,其实它这个env是带了回测功能的,不妨我们解读一下:
import numpy as np import pandas as pd from gym.utils import seeding import gym from gym import spaces import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as plt from stable_baselines3.common.vec_env import DummyVecEnv class StockPortfolioEnv(gym.Env): metadata = {'render.modes': ['human']} def __init__(self, df, stock_dim, hmax, initial_amount, transaction_cost_pct, reward_scaling, state_space, action_space, tech_indicator_list, turbulence_threshold=None, lookback=252, day=0): # super(StockEnv, self).__init__() # money = 10 , scope = 1 self.day = day self.lookback = lookback self.df = df self.stock_dim = stock_dim self.hmax = hmax self.initial_amount = initial_amount self.transaction_cost_pct = transaction_cost_pct self.reward_scaling = reward_scaling self.state_space = state_space self.action_space = action_space self.tech_indicator_list = tech_indicator_list # action_space normalization and shape is self.stock_dim self.action_space = spaces.Box(low=0, high=1, shape=(self.action_space,)) # Shape = (34, 30) # covariance matrix + technical indicators self.observation_space = spaces.Box(low=-np.inf, high=np.inf, shape=(self.state_space + len(self.tech_indicator_list), self.state_space)) # load data from a pandas dataframe self.data = self.df.loc[self.day, :] self.covs = self.data['cov_list'].values[0] self.state = np.append(np.array(self.covs), [self.data[tech].values.tolist() for tech in self.tech_indicator_list], axis=0) self.terminal = False self.turbulence_threshold = turbulence_threshold # initalize state: inital portfolio return + individual stock return + individual weights self.portfolio_value = self.initial_amount # memorize portfolio value each step self.asset_memory = [self.initial_amount] # memorize portfolio return each step self.portfolio_return_memory = [0] self.actions_memory = [[1 / self.stock_dim] * self.stock_dim] self.date_memory = [self.data.date.unique()[0]] def step(self, actions): # print(self.day) self.terminal = self.day >= len(self.df.index.unique()) - 1 # print(actions) if self.terminal: df = pd.DataFrame(self.portfolio_return_memory) df.columns = ['daily_return'] plt.plot(df.daily_return.cumsum(), 'r') plt.savefig('results/cumulative_reward.png') plt.close() plt.plot(self.portfolio_return_memory, 'r') plt.savefig('results/rewards.png') plt.close() print("=================================") print("begin_total_asset:{}".format(self.asset_memory[0])) print("end_total_asset:{}".format(self.portfolio_value)) df_daily_return = pd.DataFrame(self.portfolio_return_memory) df_daily_return.columns = ['daily_return'] if df_daily_return['daily_return'].std() != 0: sharpe = (252 ** 0.5) * df_daily_return['daily_return'].mean() / \ df_daily_return['daily_return'].std() print("Sharpe: ", sharpe) print("=================================") return self.state, self.reward, self.terminal, {} else: # print("Model actions: ",actions) # actions are the portfolio weight # normalize to sum of 1 # if (np.array(actions) - np.array(actions).min()).sum() != 0: # norm_actions = (np.array(actions) - np.array(actions).min()) / (np.array(actions) - np.array(actions).min()).sum() # else: # norm_actions = actions weights = self.softmax_normalization(actions) # print("Normalized actions: ", weights) self.actions_memory.append(weights) last_day_memory = self.data # load next state self.day += 1 self.data = self.df.loc[self.day, :] self.covs = self.data['cov_list'].values[0] self.state = np.append(np.array(self.covs), [self.data[tech].values.tolist() for tech in self.tech_indicator_list], axis=0) # print(self.state) # calcualte portfolio return # individual stocks' return * weight portfolio_return = sum(((self.data.close.values / last_day_memory.close.values) - 1) * weights) # update portfolio value new_portfolio_value = self.portfolio_value * (1 + portfolio_return) self.portfolio_value = new_portfolio_value # save into memory self.portfolio_return_memory.append(portfolio_return) self.date_memory.append(self.data.date.unique()[0]) self.asset_memory.append(new_portfolio_value) # the reward is the new portfolio value or end portfolo value self.reward = new_portfolio_value # print("Step reward: ", self.reward) # self.reward = self.reward*self.reward_scaling return self.state, self.reward, self.terminal, {} def reset(self): self.asset_memory = [self.initial_amount] self.day = 0 self.data = self.df.loc[self.day, :] # load states self.covs = self.data['cov_list'].values[0] self.state = np.append(np.array(self.covs), [self.data[tech].values.tolist() for tech in self.tech_indicator_list], axis=0) self.portfolio_value = self.initial_amount # self.cost = 0 # self.trades = 0 self.terminal = False self.portfolio_return_memory = [0] self.actions_memory = [[1 / self.stock_dim] * self.stock_dim] self.date_memory = [self.data.date.unique()[0]] return self.state def render(self, mode='human'): return self.state def softmax_normalization(self, actions): numerator = np.exp(actions) denominator = np.sum(np.exp(actions)) softmax_output = numerator / denominator return softmax_output def save_asset_memory(self): date_list = self.date_memory portfolio_return = self.portfolio_return_memory # print(len(date_list)) # print(len(asset_list)) df_account_value = pd.DataFrame({'date': date_list, 'daily_return': portfolio_return}) return df_account_value def save_action_memory(self): # date and close price length must match actions length date_list = self.date_memory df_date = pd.DataFrame(date_list) df_date.columns = ['date'] action_list = self.actions_memory df_actions = pd.DataFrame(action_list) df_actions.columns = self.data.tic.values df_actions.index = df_date.date # df_actions = pd.DataFrame({'date':date_list,'actions':action_list}) return df_actions def _seed(self, seed=None): self.np_random, seed = seeding.np_random(seed) return [seed] def get_sb_env(self): e = DummyVecEnv([lambda: self]) obs = e.reset() return e, obs
看强化学习环境,看action_space和observation_space:
action_space的形态=stock_dim,就是有多少支股票,有多少个动作,这个好理解。
# action_space normalization and shape is self.stock_dim self.action_space = spaces.Box(low=0, high=1, shape=(self.action_space,)) # Shape = (34, 30) # covariance matrix + technical indicators self.observation_space = spaces.Box(low=-np.inf, high=np.inf, shape=(self.state_space + len(self.tech_indicator_list), self.state_space))
调用ppo和DDPG两种算法。
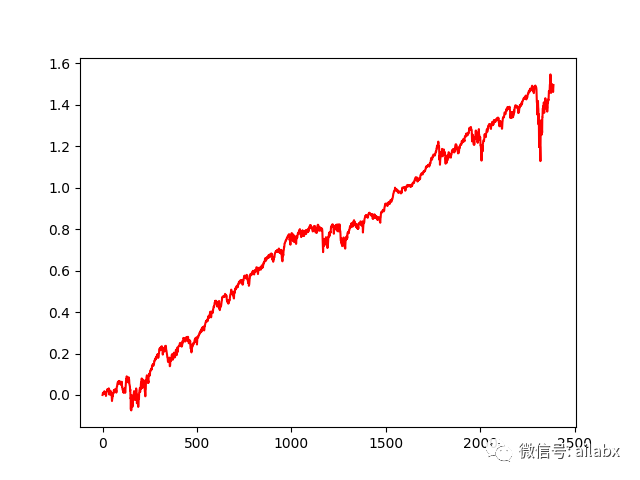
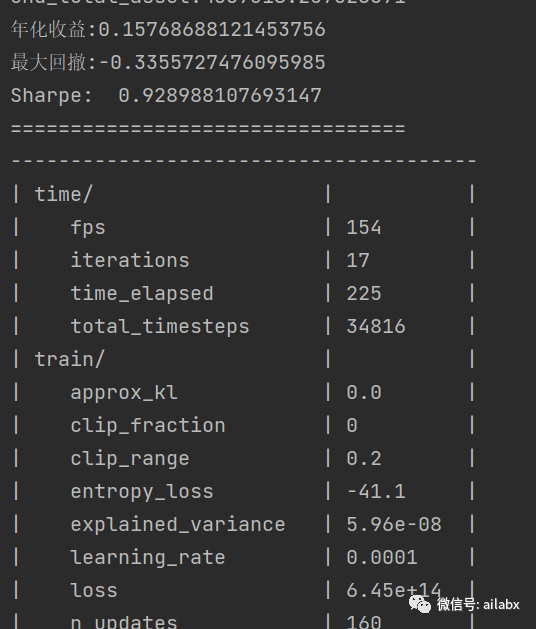
import pandas as pd # train = pd.read_csv('train.csv', index_col=0) with pd.HDFStore('train.h5') as s: train = s['train'] print(train) stock_dimension = len(train.tic.unique()) state_space = stock_dimension print(f"Stock Dimension: {stock_dimension}, State Space: {state_space}") INDICATORS = [ "macd", "boll_ub", "boll_lb", "rsi_30", "cci_30", "dx_30", "close_30_sma", "close_60_sma", ] env_kwargs = { "hmax": 100, "initial_amount": 1000000, "transaction_cost_pct": 0.001, "state_space": state_space, "stock_dim": stock_dimension, "tech_indicator_list": INDICATORS, "action_space": stock_dimension, "reward_scaling": 1e-4 } from engine.rl.stock_portfolio_env import StockPortfolioEnv e_train_gym = StockPortfolioEnv(df=train, **env_kwargs) env_train, _ = e_train_gym.get_sb_env() print(type(env_train)) from engine.rl.models import DRLAgent agent = DRLAgent(env=env_train) agent = DRLAgent(env = env_train) PPO_PARAMS = { "n_steps": 2048, "ent_coef": 0.005, "learning_rate": 0.0001, "batch_size": 128, } model_ppo = agent.get_model("ppo",model_kwargs = PPO_PARAMS) trained_ppo = agent.train_model(model=model_ppo, tb_log_name='ppo', total_timesteps=80000) trained_ppo.save('trained_ppo.zip') DDPG_PARAMS = {"batch_size": 128, "buffer_size": 50000, "learning_rate": 0.001} model_ddpg = agent.get_model("ddpg", model_kwargs=DDPG_PARAMS) trained_ddpg = agent.train_model(model=model_ddpg, tb_log_name='ddpg', total_timesteps=50000) trained_ddpg.save('trained_ddpg.zip')
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104105
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!