
继续强化学习应用于股票投资,昨天的文章我们已经把数据,特征工程都准备好了。
开始准备交易环境,我们的候选集是上证50成份股,投资基准是上证50指数。
from typing import Any
import numpy as np
import pandas as pd
from stable_baselines3 import DDPG
from stable_baselines3 import A2C
from stable_baselines3 import PPO
from stable_baselines3 import TD3
from stable_baselines3 import SAC
from stable_baselines3.common.noise import NormalActionNoise, OrnsteinUhlenbeckActionNoise
# 强化学习模型列表
MODEL_LIST = ["a2c", "ddpg", "ppo", "sac", "td3"]
# tensorboard_log 路径
TENSORBOARD_LOG_DIR = f"tensorboard_log"
# 模型的超参数
A2C_PARAMS = {
"n_steps": 5,
"ent_coef": 0.01,
"learning_rate": 0.0007
}
PPO_PARAMS = {
"n_steps": 256,
"ent_coef": 0.01,
"learning_rate": 0.00005,
"batch_size": 256
}
DDPG_PARAMS = { "batch_size": 128, "buffer_size": 50000, "learning_rate": 0.001 } TD3_PARAMS = { "batch_size": 100, "buffer_size": 1000000, "learning_rate": 0.001 } SAC_PARAMS = { "batch_size": 64, "buffer_size": 100000, "learning_rate": 0.0001, "learning_starts": 2000, "ent_coef": "auto_0.1" } print(locals()['A2C_PARAMS']) MODELS = {"a2c": A2C, "ddpg": DDPG, "td3": TD3, "sac": SAC, "ppo": PPO} MODEL_KWARGS = {} for x in MODELS.keys(): MODEL_KWARGS[x] = locals()["{}_PARAMS".format(x.upper())] NOISE = { "normal": NormalActionNoise, "ornstein_uhlenbeck": OrnsteinUhlenbeckActionNoise } def get_model( env, model_name: str, policy: str = "MlpPolicy", policy_kwargs: dict = None, model_kwargs: dict = None, verbose: int = 1 ) -> Any: """根据超参数生成模型""" if model_name not in MODELS: raise NotImplementedError("NotImplementedError") if model_kwargs is None: model_kwargs = MODEL_KWARGS[model_name] if "action_noise" in model_kwargs: n_actions = env.action_space.shape[-1] model_kwargs["action_noise"] = NOISE[model_kwargs["action_noise"]]( mean=np.zeros(n_actions), sigma=0.1 * np.ones(n_actions) ) print(model_kwargs) model = MODELS[model_name]( policy=policy, env=env, tensorboard_log="{}/{}".format(TENSORBOARD_LOG_DIR, model_name), verbose=verbose, policy_kwargs=policy_kwargs, **model_kwargs ) return model def train_model( model: Any, tb_log_name: str, total_timesteps: int = 5000 ) -> Any: """训练模型""" model = model.learn(total_timesteps=total_timesteps, tb_log_name=tb_log_name) return model if __name__ == '__main__': model = get_model('sac')
stable-baseline3框架里常用的模型,以及参数列表。
做一个基础性的封装。
训练过程中,参数的意义:
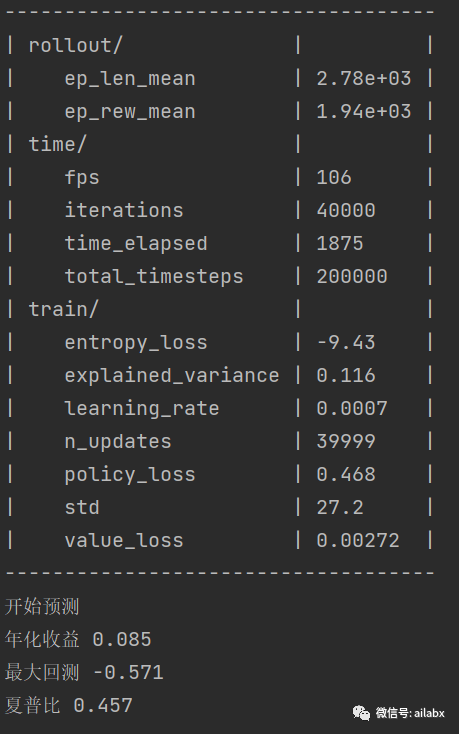

强化学习需要observation的space严格一致,不确定是stable-baseline3的约束,还是所有强化学习框架均如此:

要用好深度强化,有开箱即用的算法框架固然好,但如果不了解其间的细节,使用上会带来困扰,不知如何去优化,如何提升模型效果等。因此,可以打开框架的代码来看一看,甚至,不排除可以自己实现一个对应的算法。
很神奇的事情是elegantRL一点也不elegant,根本就不是开箱可用。引用来引用去,一堆代码。还不如自己从头实现没这么多约束。没有一个tutorial可以用。
从成熟度而言,stable-baseline3是最好的,没有之一。
这个也欢迎大家讨论。我对于框架选型的标准,要么使用容易,就是封装得好,要么代码写得简洁,模块化好。我们可以拆出来直接用,比如pybroker,qlib等。
stable_baseline3玩倒立摆(离散的动作空间)。
import gym from stable_baselines3 import DQN env = gym.make("CartPole-v0") model = DQN("MlpPolicy", env, verbose=1) model.learn(total_timesteps=10000, log_interval=4) model.save("dqn_cartpole") del model # remove to demonstrate saving and loading model = DQN.load("dqn_cartpole") obs = env.reset() while True: action, _states = model.predict(obs, deterministic=True) obs, reward, done, info = env.step(action) env.render() if done: obs = env.reset()
td3应用于pendulum的环境(连续环境的action)
import gym import numpy as np from stable_baselines3 import TD3 from stable_baselines3.common.noise import NormalActionNoise, OrnsteinUhlenbeckActionNoise env = gym.make("Pendulum-v1") # The noise objects for TD3 n_actions = env.action_space.shape[-1] action_noise = NormalActionNoise(mean=np.zeros(n_actions), sigma=0.1 * np.ones(n_actions)) model = TD3("MlpPolicy", env, action_noise=action_noise, verbose=1) model.learn(total_timesteps=10000, log_interval=10) model.save("td3_pendulum") env = model.get_env() del model # remove to demonstrate saving and loading model = TD3.load("td3_pendulum") obs = env.reset() while True: action, _states = model.predict(obs) obs, rewards, dones, info = env.step(action) env.render()
由于stable-baseline3要求observation空间需要shape一致,我们还需要对dataloader做一个改进,也就是calendar里丢失的数据,需要使用前一天的数据来填充。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104107
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!