
解读股票价格的复权:为什么复权数据至关重要(附程序代码)
在量化投资中,一个经常被忽视却至关重要的概念是股票价格的复权。然而,很多投资者,尤其是新手投资者,可能对复权所涉及的各种问题并不熟悉,也可能不清楚该使用哪种复权数据。在这篇文章中,我们将深入探讨股票价格的复权,解释它为什么重要,以及如何在实际投资决策中应用复权数据。
01
为什么要复权
当公司进行分红、配股、拆股、回购等操作时,公司的股本结构会发生变化,这将直接影响其股票的交易价格。股票的复权是指对股票的历史交易数据进行调整,以反映公司的所有股本变动(如股息派发、配股、拆股和回购等)对股价的影响。
例如对比下面这只股票不复权的K线和前复权的K线:
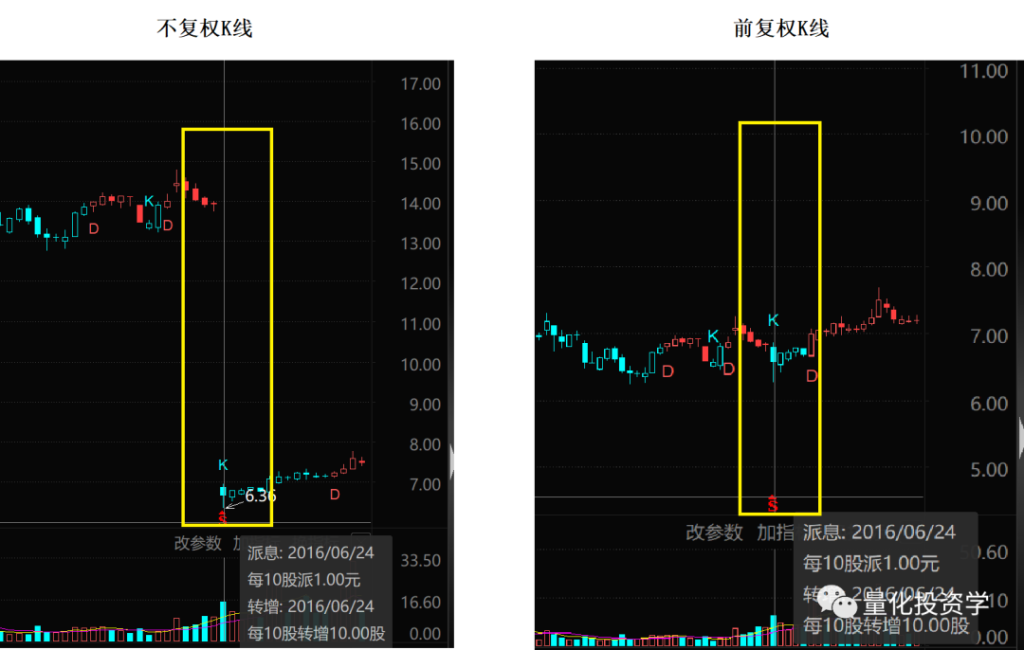

在不复权的K线图中,2016年6月24日这天出现了一个巨大的跳空,股价从13快多一下跌倒6块多;但在前复权的K线图中,股价变动是连续的比较平稳的。发生了什么事呢?原来这只股票做了年度权益分派:向全体股东每10股派1元现金股息,同时,以资本公积金向全体股东每10股转增10股,除权除息日为2016年6月24日。
假设某个股东持有该公司股票100股,在每10股转增10股后,原来的100股就会变成200股,但以公积金转增实际并不增加公司的总市值,因此假如原来每股价值13元,100股总价值1300元,在除权后每股价值会变为6.5元,200股价值1300元,转增后持有的股票数量增加1倍,但单张股票的价值变为原来的1/2,持有的股票总价值不变。
分红也会造成股票价格下降,因为分红后公司的总资产减少,市值也应当相应减少。
从上面这个例子可以看到,由于股票存在分红、配股、拆股、回购等事件,会导致股价出现较大的缺口,如果不进行复权处理,直接使用这些历史价格进行分析,可能会得到错误的结论。为了保证数据连贯性,需要使用复权的方法对价格序列进行调整。
02
复权的方法及各自的优缺点
- 前复权
前复权是以最新的价格变动为基准,将所有历史数据按照这个基准进行调整。
前复权的优点是最新复权价格与实际价格一致,因此很直观,也是各种行情软件默认的复权方式。
但前复权也有缺点:
一是由于前复权的方式在每次除权除息后,都需要根据最新的价格重新计算所有的历史数据,这会导致每次发生除权除息事件后,历史数值都会发生变化。由于需要反复调整历史数据,数据更新和维护的成本较高。
二是对于有持续分红的公司来说,前复权价可能出现负值。
三是前复权价格如果处理不当有使用未来数据的风险,这个在《前视偏差:使用未来数据》一节中已有详细的讲述。 - 后复权
后复权是以某一固定日期(通常为股票上市日期)的价格为基准,将此后的所有数据进行调整。
后复权的优点是计算简单,一旦计算完成,后续的数据更新也方便,以前的后复权价格不会因为后面的除权除息事件而发生变动。
但后复权价格和真实股票价格可能差别较大,尤其不适用于实盘。 - 需要注意的是,复权的算法有很多种,包括:经典算法、递归后复权法、递归前复权法、涨跌幅复权法等等,不同平台、不同数据源由于复权算法不同,导致复权数据存在差异,而且除权次数越多,差异越明显。
03
如何计算复权
数据源通常都会提供复权因子,根据复权因子可以快速计算出复权后的数据,下面介绍如何用 TuShare 数据源的复权因子计算复权。以下代码需要预先安装TuShare数据源,参见《本地Python环境部署》。
复权价格的计算公式为:
后复权价格 = 当日不复权价格 × 当日复权因子
前复权价格 = 当日不复权价格 × 当日复权因子 / 最新复权因子
计算复权价格的代码示例如下:
#导入需要的库
import pandas as pd
import tushare as ts
#初始化数据接口并设置token,token在个人主页获取
#注意:下面语句中的token要更换为你个人的token字符串
pro = ts.pro_api(token)
#获取平安银行(000001)不复权的行情数据,数据的时间范围从2023年6月12日至2023年6月20日
price_df = pro.daily(ts_code=’000001.SZ’, start_date=’20230612′, end_date=’20230620′).set_index(‘trade_date’)
#获取平安银行(000001)的复权因子
adj_factor_df = pro.adj_factor(ts_code=’000001.SZ’, trade_date=”).set_index(‘trade_date’)
#将不复权的收盘价和复权因子放在一个DataFrame数据表中
df = pd.DataFrame()
df[‘收盘价_不复权’] = price_df[‘close’]
df[‘复权因子’] = adj_factor_df[‘adj_factor’]
#计算复权后的收盘价
df[‘收盘价后复权’] = df[‘收盘价不复权’] * df[‘复权因子’]
df[‘收盘价前复权’] = df[‘收盘价不复权’] * df[‘复权因子’] / df[‘复权因子’].iloc[-1]
最后用 print(df) 输出数据查看:
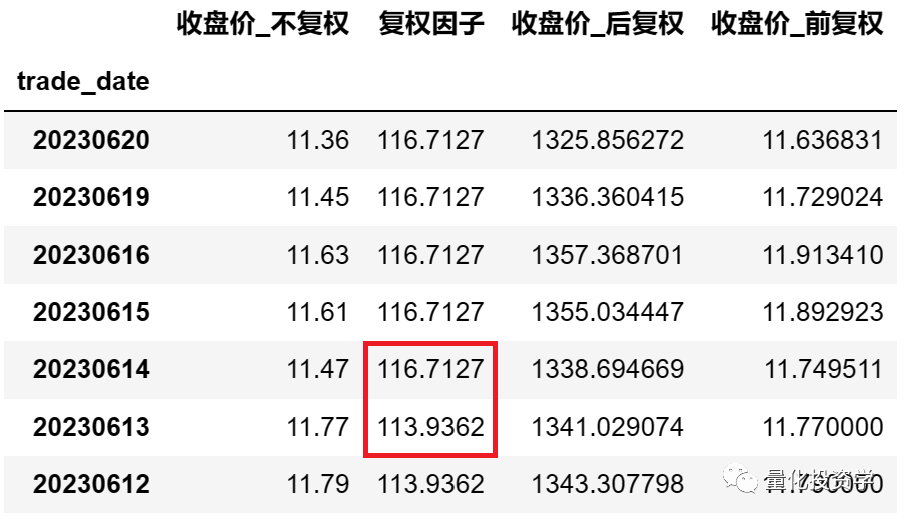
从上图可以看到:
- 最新的前复权价格跟最新的实际价格(即不复权的价格)是一致的。
- 前复权价格和后复权价格相差巨大。
- 在2023年6月14日这天复权因子发生了变动,经过查看平安银行的公告,平安银行2022年度的权益分配方案为每10股派2.85元现金,除权除息日为2023年6月14日。
04
在量化投资中使用哪种复权数据
在量化投资中应根据具体情况来选择复权数据:
- 进行数据存储和更新时
当需要采集和存储行情数据时,应该用前复权价格、后复权价格还是不复权价格?
从前文可知用前复权价格并不是一个好的方案,因为每次发生除权除息事件后否需要重新计算历史的前复权价格,数据更新和维护很麻烦。
用后复权价格虽然没有重新计算历史数据的问题,但后复权价格跟实际价格往往相差巨大,也不是一个好选择。
比较好的方案是存储不复权的价格,并同时存储复权因子,这样数据更新时不用修改历史数据,而且通过复权因子可以很方便的计算出前复权价格和后复权价格。 - 进行数据分析和策略回测时
在进行数据分析和策略回测时,通常使用后复权价格,这是因为:
(1)当回溯的时间很长时,前复权价格可能会出现负值的情况。
(2)如果需要对结果数据进行存储和定期更新,比如有一个需要定期更新的因子库,那么采用后复权价格更易于维护,因为前复权价格在发生除权除息时要重新计算所有历史数据,相应的因子值也要重新计算,更新和维护因子库的成本高。
(3)前复权价格处理不当有使用未来数据的风险。 - 在实盘时
实盘中进行数据运算时应该使用前复权价格,因为后复权价格可能跟实际价格相差巨大,不适合实盘操作。
在本文中,我们深入探讨了股票价格复权的概念和重要性,研究了如何计算和使用复权数据。投资不仅仅是买低卖高的游戏,而是一个需要深入理解和精细操作的过程,复权数据就是其中的一个方面。要有效地使用复权数据,我们需要对其有深入的理解,并掌握处理和使用复权
发布者:爱吃肉的小猫,转载请注明出处:https://www.95sca.cn/archives/45865
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!