
Python对PostgreSQL数据库进行操作,经常会用到第三方工具psycopg2,其中插入或更新数据表的几种方法速度差别比较大,本文对几种常用的方法做了比较,内容从程序化股票交易系统中提取而来。在程序化股票交易系统中,除了开盘前读入必要的历史数据之外,还需要在开盘期间保存全部股票的实时行情,以便在系统出现故障或断电的情况下,快速恢复系统运行。
A股全市场共有5000多只股票,程序化交易系统使用的数据有日线数据、30分钟线数据、5分钟线数据和1分钟线数据,这些数据每分钟都要更新一次,那么每分钟更新的数据大约要保存或更新20000多条数据,这需要在10秒钟内完成,因为整个系统每分钟运行一次,除了处理行情数据之外,还要有足够的时间进行策略计算和生成交易信号,另外还要个系统运行留出大约10秒中的余量。因此,以最快的速度处理并保存全部股票的实时行情数据尤为重要。


本文定义了以下六种方法,把psycopg2提供的插入数据到数据库的方法封装起来,比较这些方法的执行速度,选出其中最快的方法在系统中使用。六种方法分别介绍如下:
- 导入必要的工具包:
import numpy as np
import pandas as pd
import psycopg2
import psycopg2.extras as extras
import sys
import os
from io import StringIO,BytesIO
import time
from sqlalchemy import create_engine- 在PostgreSQL数据库中创建数据表stockmd_mine, 代码如下:
CREATE TABLE IF NOT EXISTS public.stockmd_min1 (
id integer,
symbol TEXT,
dt_occured TIMESTAMP,
open_p NUMERIC,
high_p NUMERIC,
low_p NUMERIC,
close_p NUMERIC,
volume_p NUMERIC,
amnt_p NUMERIC
);- 定义PostgreSQL数据库连接
param_dic = {
"host" : "localhost",
"database" : "tutorial",
"user" : "postgres",
"password" : "caspar"
}
def connect(params_dic):
conn = None
try:
print(' 连接到 PostgreSQL 数据库...')
conn = psycopg2.connect(**params_dic)
except(Exception, psycopg2.DatabaseError) as error:
print(error)
sys.exit(1)
print(" 连接成功!")
return conn- 准备测试数据:把股票的1分钟行情数据从对应的文本文件中读取1分钟行情数据
def HistoryMD_mins(finalmd_filelist,file_path):
# 基于finalmd_list读入1分钟历史数据
print('\n 正在读取 1 分钟历史数据...')
dfmin1_list_tmp = []
for filename_min1 in finalmd_filelist:
try:
headers = ['symbol', 'dt_occured', 'open_p', 'high_p','low_p','close_p','volume_p','amnt_p']
dtypes = {'symbol':'str', 'dt_occured':'str', 'open_p':'float', 'high_p':'float','low_p':'float','close_p':'float','volume_p':'int','amnt_p':'float'}
parse_dates = ['dt_occured'] # 字符型解析为日期型
df = pd.read_csv(file_path+filename_min1, sep=',', header=None, names=headers, dtype=dtypes, parse_dates=parse_dates)
df['dt_occured']= pd.to_datetime(df['dt_occured'],format='%Y-%m-%d %H:%M')
if (len(df) > 0):
# df_cut = df[(len(df)-10800):]
# df_cut.set_index('dt_occured',inplace= True)
# dfmin1_list_tmp.append(df_cut)
# else:
# #print(f'{filename_min1} 的长度:{len(df)}')
# df.set_index('dt_occured',inplace= True)
dfmin1_list_tmp.append(df)
else:
pass
except:
print(' 报错 - min1:',filename_min1)
return dfmin1_list_tmp
## 读取列表中文本文件中的1分钟行情数据,后面运行时有53只股票的数据
finalmd_filelist = ['SZ#002142.csv','SH#600111.csv','SZ#000831.csv','SZ#300748.csv',
'SZ#000629.csv','SH#600259.csv','SH#600507.csv','SZ#000630.csv']
tmpdf_list= HistoryMD_mins(finalmd_filelist,"D:\\SecurityData\\MD_1min\\")
df = pd.concat(tmpdf_list)方法1:封装execute_values()函数,用来保存行情数据到数据库
根据dataframe创建元组列表,然后把每行数据按照列顺序连接起来,再执行SQL出入语句
def execute_values(conn, df, table):
print(' 正在调用函数 execute_values() 写数据到数据库,请稍等...')
# 根据dataframe创建元组列表
tuples = [tuple(x) for x in df.to_numpy()]
# dataframe的列
cols = ','.join(list(df.columns))
# execute方法
cursor = conn.cursor()
query = "INSERT INTO %s(%s) VALUES %%s" % (table, cols)
try:
extras.execute_values(cursor, query, tuples)
conn.commit()
except (Exception, psycopg2.DatabaseError) as error:
print(" 报错: %s" % error)
conn.rollback()
cursor.close()
return 1
print(" 执行 execute_values() 完毕!")
cursor.close()方法2:封装copy_from()函数,用以保存行情数据到数据库
先把dataframe数据保存为一个临时文件,放在硬盘,然后再打开并读取数据,最后使用copy_from()函数把内容写入数据库中,
def copy_from_file(conn, df, table):
print(' 正在调用自定义函数 copy_from_file() 写数据到数据库,请稍等...')
# 把dataframe数据保存为一个临时文件,放在硬盘
tmp_df = "tmp_dataframe.csv"
df.to_csv(tmp_df, index_label='id', header=False)
f = open(tmp_df, 'r')
cursor = conn.cursor()
try:
cursor.copy_from(f, table, sep=",",null ='\\N',size = 32768,columns = None )
conn.commit()
except (Exception, psycopg2.DatabaseError) as error:
# os.remove(tmp_df)
print(" 报错: %s" % error)
conn.rollback()
cursor.close()
return 1
print(" 执行 copy_from_file() 完毕!")
cursor.close()
# os.remove(tmp_df) 方法3:封装copy_from()函数,使用StringIO方法读取数据
先把dataframe数据保存到内存中,然后从内存读取数据,最后使用copy_from()函数把内容复制数据库的表中,
def copy_from_stringio(conn, df, table):
print(' 正在调用自定义函数 copy_from_stringio() 写数据到数据库,请稍等...')
# 把dataframe保存到内存中
buffer = StringIO()
df.to_csv(buffer, index_label='id', header=False)
buffer.seek(0)
cursor = conn.cursor()
try:
cursor.copy_from(buffer, table, sep=",",null ='\\N',size = 32768,columns = None )
conn.commit()
except (Exception, psycopg2.DatabaseError) as error:
print(" 报错: %s" % error)
conn.rollback()
cursor.close()
return 1
print(" 执行 copy_from_stringio() 完毕!")
cursor.close()方法4:封装execute_mogrify()函数,
使用cursor.mogrify()函数编写大批量插入数据的语句,然后由cursor.execute()执行。
print(' 正在调用自定义函数 execute_mogrify() 写数据到数据库,请稍等...')
df.reset_index(level=0, inplace=False) #是否把索引列转换为普通列
# 根据dataframe的值创建元组列表
tuples = [tuple(x) for x in df.to_numpy()]
# print(len(tuples))
# print(tuples[-1])
# dataframe的列
cols = ','.join(list(df.columns))
# print(type(cols))
# print(df.columns)
# SQL quert to execute
cursor = conn.cursor()
# values = [cursor.mogrify("(%s,%s,%s)", tup).decode('utf8') for tup in tuples]
# query = "INSERT INTO %s(%s) VALUES " % (table, cols) + ",".join(values)
values = [cursor.mogrify("(%s,%s,%s,%s,%s,%s,%s,%s)", tup).decode('utf8') for tup in tuples]
query = "INSERT INTO %s(%s) VALUES " % (table, cols) + ",".join(values)
try:
cursor.execute(query, tuples)
conn.commit()
except (Exception, psycopg2.DatabaseError) as error:
print(" 报错: %s" % error)
conn.rollback()
cursor.close()
return 1
print(" 执行 execute_mogrify() 完毕!")
cursor.close()方法5:使用sqlalchemy工具包
使用sqlalchemy工具包时,要用create_engine另外建立连接数据库的方法。连接字符串示例如:’postgresql+psycopg2://postgres:123@localhost:5432/postgres’,其中的参数如:用户名:密码@localhost:端口/数据库
def using_sqlalchemy(df,md_min1):
print(' 正在调用自定义函数 using_sqlalchemy() 写数据到数据库,请稍等...')
connect4sqlalchemy = "postgresql+psycopg2://postgres:caspar@localhost:5432/tutorial"
engine = create_engine(connect4sqlalchemy)
df.to_sql(
md_min1,
con=engine,
index=True,
if_exists='replace'
)
print(" 执行 using_sqlalchemy() 完毕!")方法6:构建超长字符串,使用execute()执行相应的插入语句
def building_string(conn, df, given_table):
print(' 正在调用在自定义函数 building_string() 写数据到数据库,请稍等...')
df.reset_index(level=0, inplace=True) #是否把索引列转换为普通列
# 根据dataframe的值创建元组列表
tuples = [tuple(x) for x in df.to_numpy()]
# print(len(tuples))
# dataframe的所有列
cols = ','.join(list(df.columns))
# print(type(cols))
# print(df.columns)
cursor = conn.cursor()
argument_string = ",".join("('%s','%s', '%s','%s', '%s','%s', '%s','%s','%s')" % (x, y,z,o,p,q,r,s,t) for (x, y,z,o,p,q,r,s,t) in tuples)
cursor.execute("INSERT INTO {table} VALUES".format(table=given_table) + argument_string)
conn.commit()
conn.close()
print('执行 building_string() 完毕!')6 种方法的运行时间比较
为了更好地看出各种方法运行速度的差别,执行各方法时都读取了53只股票的 1分钟线数据,共1017600条记录,个股的数据格式如下:
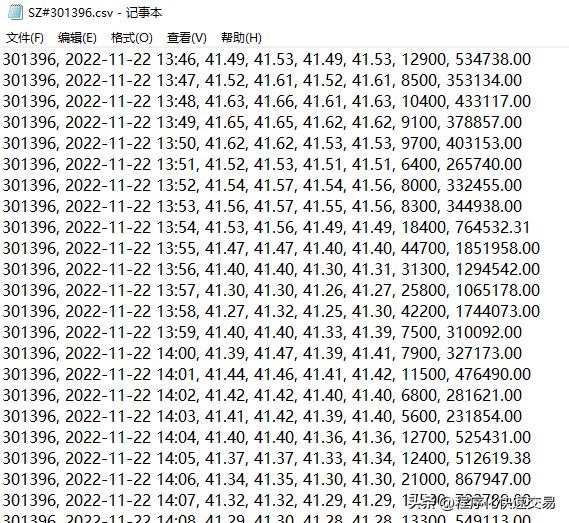
执行结果如下:
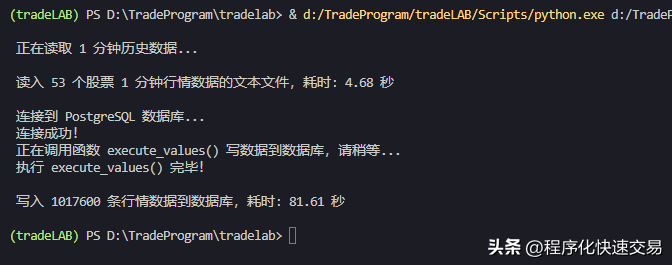
- 执行方法1:execute_values(conn, df, ‘stockmd_min1’),结果如下图:
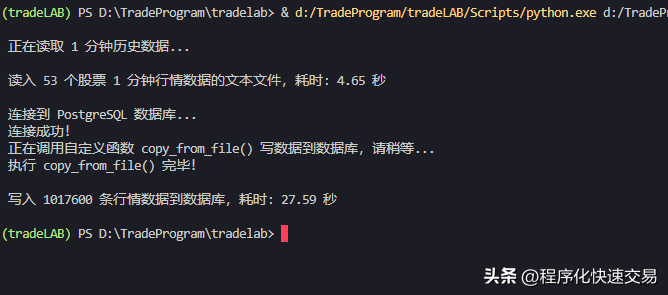
- 执行方法2:copy_from_file(conn, df, ‘stockmd_min1’),结果如下图:
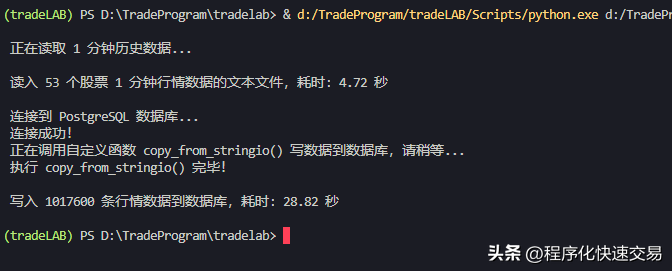
- 执行方法3:copy_from_stringio(conn, df, ‘stockmd_min1’),结果如下图:
- 执行方法4:execute_mogrify(conn, df, ‘stockmd_min1’),结果如下图:
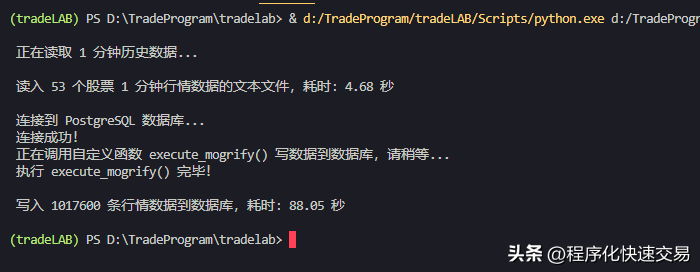
- 执行方法5:using_sqlalchemy(df,’stockmd_min1′),结果如下图:

- 执行方法6:building_string(conn, df, ‘stockmd_min1’),结果如下图:
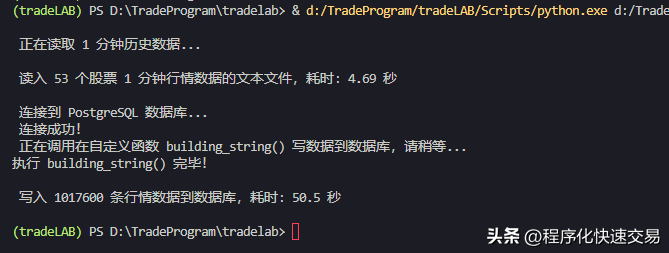
执行第1—6方法实际耗时约为82、28、29、88、102、50秒,处理的数据都为1017600条,而笔者开发的程序化交易系统,每分钟要更新的行情数据记录大约20000条,只需要五十分之一的时间,因此第2、第3、第6种方法耗时都不超过1秒,都能满足需要。
附:完整代码如下
import numpy as np
import pandas as pd
import psycopg2
import psycopg2.extras as extras
import sys
import os
from io import StringIO,BytesIO
import time
from sqlalchemy import create_engine
# 数据库连接参数
param_dic = {
"host" : "localhost",
"database" : "tutorial",
"user" : "postgres",
"password" : "caspar"
}
def connect(params_dic):
conn = None
try:
print(' 连接到 PostgreSQL 数据库...')
conn = psycopg2.connect(**params_dic)
except(Exception, psycopg2.DatabaseError) as error:
print(error)
sys.exit(1)
print(" 连接成功!")
return conn
def read_dataframe(csv_file):
df = pd.read_csv(csv_file,index_col=0)
df = df.rename(columns={
"Source": "source",
"Date": "datetime",
"Mean": "mean_temp"
})
return df
def HistoryMD_mins(finalmd_filelist,file_path):
print('\n 正在读取 1 分钟历史数据...')
dfmin1_list_tmp = []
for filename_min1 in finalmd_filelist:
try:
headers = ['symbol', 'dt_occured', 'open_p', 'high_p','low_p','close_p','volume_p','amnt_p']
dtypes = {'symbol':'str', 'dt_occured':'str', 'open_p':'float', 'high_p':'float','low_p':'float','close_p':'float','volume_p':'int','amnt_p':'float'}
parse_dates = ['dt_occured'] # 字符型解析为日期型
df = pd.read_csv(file_path+filename_min1, sep=',', header=None, names=headers, dtype=dtypes, parse_dates=parse_dates)
df['dt_occured']= pd.to_datetime(df['dt_occured'],format='%Y-%m-%d %H:%M')
if (len(df) > 0):
# df_cut = df[(len(df)-10800):]
# df_cut.set_index('dt_occured',inplace= True)
# dfmin1_list_tmp.append(df_cut)
# else:
# #print(f'{filename_min1} 的长度:{len(df)}')
# df.set_index('dt_occured',inplace= True)
dfmin1_list_tmp.append(df)
else:
pass
except:
print(' 报错 - min1:',filename_min1)
return dfmin1_list_tmp
def execute_values(conn, df, table):
print(' 正在调用函数 execute_values() 写数据到数据库,请稍等...')
tuples = [tuple(x) for x in df.to_numpy()]
cols = ','.join(list(df.columns))
cursor = conn.cursor()
cursor.execute("Truncate {} Cascade;".format(table))
query = "INSERT INTO %s(%s) VALUES %%s" % (table, cols)
try:
extras.execute_values(cursor, query, tuples)
conn.commit()
except (Exception, psycopg2.DatabaseError) as error:
print(" 报错: %s" % error)
conn.rollback()
cursor.close()
return 1
print(" 执行 execute_values() 完毕!")
cursor.close()
def copy_from_file(conn, df, table):
print(' 正在调用自定义函数 copy_from_file() 写数据到数据库,请稍等...')
tmp_df = "tmp_dataframe.csv"
df.to_csv(tmp_df, index_label='id', header=False)
f = open(tmp_df, 'r')
cursor = conn.cursor()
cursor.execute("Truncate {} Cascade;".format(table))
try:
cursor.copy_from(f, table, sep=",",null ='\\N',size = 32768,columns = None )
conn.commit()
except (Exception, psycopg2.DatabaseError) as error:
# os.remove(tmp_df)
print(" 报错: %s" % error)
conn.rollback()
cursor.close()
return 1
print(" 执行 copy_from_file() 完毕!")
cursor.close()
# os.remove(tmp_df) # 本行不注释会报错
def copy_from_stringio(conn, df, table):
print(' 正在调用自定义函数 copy_from_stringio() 写数据到数据库,请稍等...')
buffer = StringIO()
df.to_csv(buffer, index_label='id', header=False)
buffer.seek(0)
cursor = conn.cursor()
try:
cursor.copy_from(buffer, table, sep=",",null ='\\N',size = 32768,columns = None )
conn.commit()
except (Exception, psycopg2.DatabaseError) as error:
print(" 报错: %s" % error)
conn.rollback()
cursor.close()
return 1
print(" 执行 copy_from_stringio() 完毕!")
cursor.close()
def execute_mogrify(conn, df, table):
print(' 正在调用自定义函数 execute_mogrify() 写数据到数据库,请稍等...')
df.reset_index(level=0, inplace=False) #是否把索引列转换为普通列
tuples = [tuple(x) for x in df.to_numpy()]
cols = ','.join(list(df.columns))
cursor = conn.cursor()
values = [cursor.mogrify("(%s,%s,%s,%s,%s,%s,%s,%s)", tup).decode('utf8') for tup in tuples]
query = "INSERT INTO %s(%s) VALUES " % (table, cols) + ",".join(values)
try:
cursor.execute(query, tuples)
conn.commit()
except (Exception, psycopg2.DatabaseError) as error:
print(" 报错: %s" % error)
conn.rollback()
cursor.close()
return 1
print(" 执行 execute_mogrify() 完毕!")
cursor.close()
def using_sqlalchemy(df,md_min1):
print(' 正在调用自定义函数 using_sqlalchemy() 写数据到数据库,请稍等...')
connect4sqlalchemy = "postgresql+psycopg2://postgres:caspar@localhost:5432/tutorial"
engine = create_engine(connect4sqlalchemy)
df.to_sql(
md_min1,
con=engine,
index=True,
if_exists='replace'
)
print(" 执行 using_sqlalchemy() 完毕!")
def building_string(conn, df, given_table):
print(' 正在调用在自定义函数 building_string() 写数据到数据库,请稍等...')
df.reset_index(level=0, inplace=True) #是否把索引列转换为普通列
tuples = [tuple(x) for x in df.to_numpy()]
cols = ','.join(list(df.columns))
cursor = conn.cursor()
argument_string = ",".join("('%s','%s', '%s','%s', '%s','%s', '%s','%s','%s')" % (x, y,z,o,p,q,r,s,t) for (x, y,z,o,p,q,r,s,t) in tuples)
cursor.execute("INSERT INTO {table} VALUES".format(table=given_table) + argument_string)
conn.commit()
conn.close()
print('执行 building_string() 完毕!')
if __name__ == "__main__":
T0_start = time.perf_counter()
## df2: 读取1分钟行情数据
finalmd_filelist = ['SZ#002142.csv','SH#600036.csv','SH#601318.csv','SH#601166.csv','SH#600919.csv','SH#601128.csv',
'SH#601838.csv','SZ#000001.csv','SH#601658.csv','SH#601788.csv','SH#600999.csv','SZ#300059.csv',
'SH#600030.csv','SH#601688.csv','SH#600837.csv','SH#601211.csv','SH#601377.csv','SZ#000776.csv',
'SZ#300003.csv','SH#601016.csv','SH#603658.csv','SH#600570.csv','SZ#000983.csv','SZ#002128.csv',
'SZ#000791.csv','SZ#000155.csv','SH#600900.csv','SZ#002039.csv','SH#601899.csv','SH#600452.csv',
'SH#600021.csv','SH#600116.csv','SZ#000993.csv','SZ#000591.csv','SZ#000875.csv','SH#600011.csv',
'SH#600821.csv','SH#600163.csv','SH#601985.csv','SH#601778.csv','SZ#000966.csv','SZ#002608.csv',
'SH#600025.csv','SH#600236.csv','SZ#000060.csv','SH#600111.csv','SZ#000831.csv','SZ#300748.csv',
'SZ#000629.csv','SH#600259.csv','SH#600507.csv','SZ#000878.csv','SZ#000630.csv']
tmpdf_list= HistoryMD_mins(finalmd_filelist,"D:\\SecurityData\\MD_1min\\")
df = pd.concat(tmpdf_list)
T0_end = time.perf_counter()
print(f'\n 读入 {len(finalmd_filelist)} 个股票 1 分钟行情数据的文本文件,耗时: {round(T0_end-T0_start,2)} 秒\n')
conn = connect(param_dic)
## 分别运行6种方法
# execute_values(conn, df, 'stockmd_min1')
# copy_from_file(conn, df, 'stockmd_min1')
# copy_from_stringio(conn, df, 'stockmd_min1')
execute_mogrify(conn, df, 'stockmd_min1')
# using_sqlalchemy(df,'stockmd_min1')
# building_string(conn, df, 'stockmd_min1')
conn.close()
T1_end = time.perf_counter()
print(f'\n 写入 {len(df)} 条行情数据到数据库,耗时: {round(T1_end-T0_end,2)} 秒\n')
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/76187
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!