
最近几年人工智能(AI)技术得到飞速发展,其在各个领域的运用也不断取得重大成果。机器学习是实现人工智能的一种方式,被评为人工智能领域中最能够体现智能的一个分支,今天就来研究一下基于StockRanker算法的机器学习量化策略。


机器学习可以这样简单理解:借助于计算机,对数据(训练集)进行学习后,形成模式识别(模型),进而实现对未来数据(测试集)的预测。
假设我们要去预测某个连续变量 Y 未来的取值,并找到了影响变量 Y 取值的 K 个变量,这些变量也称为特征变量(Feature Variable)。机器学习 即是要找到一个拟合函数f(X1,X2,…,XK|Θ)去描述 Y 和特征变量之间的关系, Θ 为这个函数的参数。

要找到这样的函数,必须要足够量的观测数据,假设有 N 个样本数据y1,y2,…,yn和 x1i,x2i,…,xKi(其中i=1,2,…,n)。然后定义一个函数 L 来衡量真实观测数据和模型估计数据偏差,函数 L 也称作损失函数(Loss Function)。基于历史观测数据,我们可以求解下列的最化问题来得到参数 Θ 的估计值:
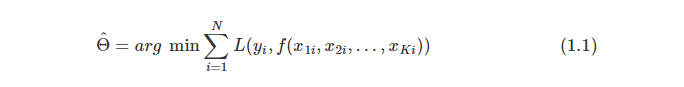
相对于传统策略开发的复杂流程和调参等大量重复工作,AI策略开发更简单,将我们的脑力从重复工作上解放出来,专注在更有创造性的地方。
机器学习算法太多,本文讨论只针对适用于金融数据预测的常用有监督型机器学习(Supervised Machine Learning)算法:StockRanker。
StockRanker算法是专为选股量化而设计,核心算法主要是排序学习和梯度提升树:

我们对AI策略开发做了抽象,设计了如下开发流程 (以 StockRanker 算法为例,也可以使用其他算法):
目标:首先定义机器学习目标并标注数据。很多机器学习场景,需要人来做数据标注,例如标注图片里的是猫或者狗。对于股票,我们关注的风险和收益是可以明确定义并自动计算出来的。所以,我们一般使用未来N天的收益或者收益风险比作为标注分数。本文使用未来给定天数的收益作为标注
数据:我们需要训练数据集来训练模型,已经评估数据集来评估效果。在模型参数研究中,我们一般还需要一个测试集用来观察调参效果
特征(因子):特征是量化研究的核心之一,在AI策略上,特征直接影响了模型的学习效果。这也是本文的目的之一,通过AI找出在A股有效的因子,并最大化的挖掘出他们的效果
算法模型:本文使用StockRanker算法,使用 M.stock_ranker_train 来训练模型,使用 M.stock_ranker_predict 来做出预测
回测:使用回测引擎来根据预测做股票交易,并得到策略收益报告和风险分析,并以此来评估策略的最终效果
StockRanker 算法可能遇到的一些问题:
- 过拟合
- 数据集重叠
- 数据集划分不当
- 训练集数据太少
- 数据预处理不够
- 标注和特征逻辑不一致
- 因子并非越多越好
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/75134
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!