
今天,我们学习参数index_col。index_col参数:把数据表其中一列或多列数据当作索引,默认为None,即不把数据表中的任何一列当作索引,而是在最左侧加入一列从0开始的整数编号作为行索引。如果不使用默认的话,那就用数字指定第几列或直接使用列名作为行索引,行索引可以大于1个。
下面我们用默认index_col的方式来读取数据:
import pandas as pd
df=pd.read_csv("stock.csv",index_col=None)#这里的index_col=None可以省略
df返回:
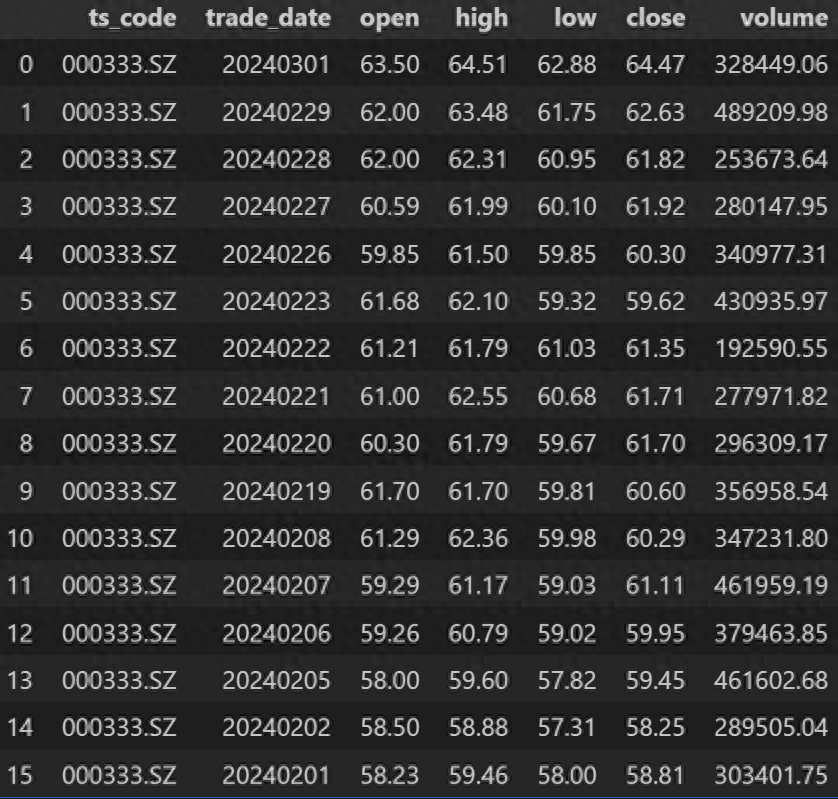

然后我们导入时将“trade_date”一列作为索引:
import pandas as pd
df=pd.read_csv("stock.csv",index_col='trade_date')#这里也可以用index_col=1
df返回:
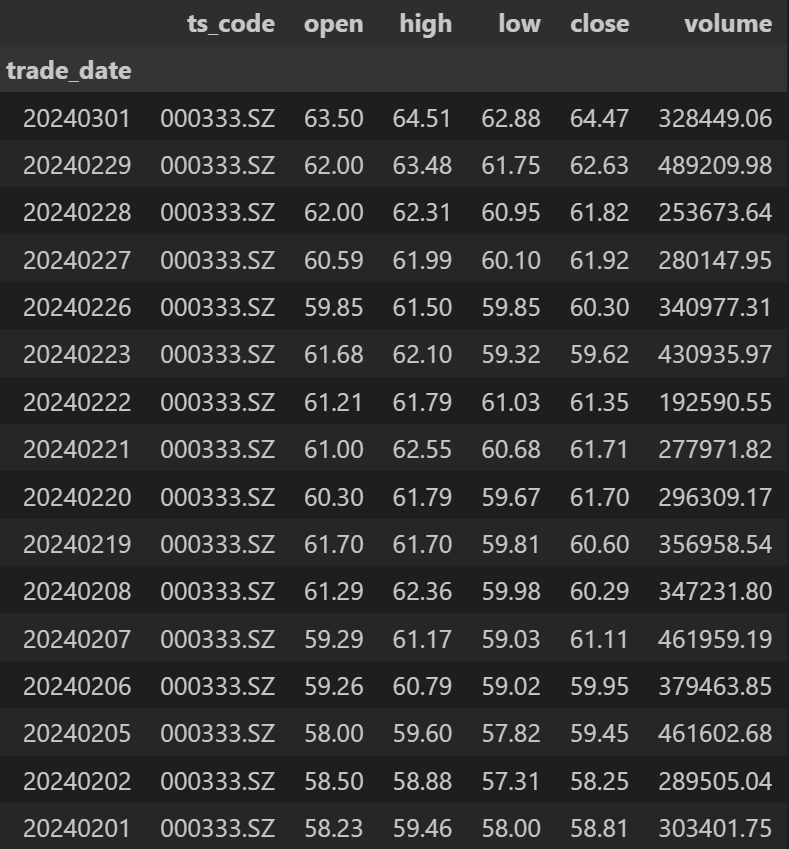
现在我们尝试导入时指定两个列作为索引:
import pandas as pd
df=pd.read_csv("stock.csv",index_col=['trade_date','ts_code'])#这里也可以用index_col=[1,0]
df返回:
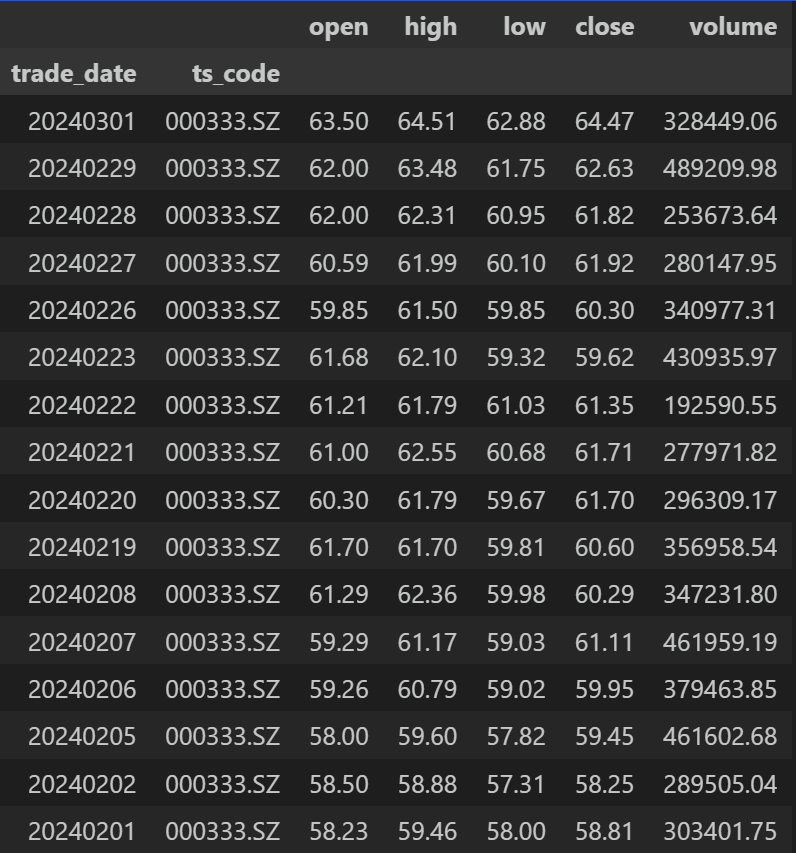
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/74904
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!