
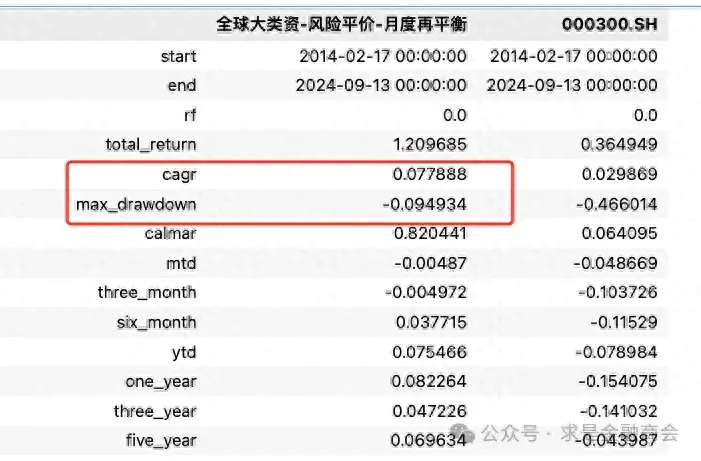
一.效果

二.实现过程
1.现在回测需要的数据
1.1etf和lof数据
import akshare as ak
import time
from config import DATA_DIR, DATA_DIR_QUOTES
import pandas as pd
def download_data(symbol, start_date="20000101"):
print(symbol)
# 全部转换成大写
symbol = symbol.upper()
code = symbol[:6]
# 回测最好用后复权数据,前复权会有负数的问题
try:
# lof基金
if "16" == code[:2]:
df = ak.fund_lof_hist_em(
symbol=code, period="daily", start_date=start_date, adjust="hfq"
)
else:
df = ak.fund_etf_hist_em(
symbol=code, period="daily", start_date=start_date, adjust="hfq"
)
except Exception as e:
print(f"Error fetching data for code {code}: {e}")
return pd.DataFrame()
df.rename(
columns={
"日期": "date",
"开盘": "open",
"收盘": "close",
"最高": "high",
"最低": "low",
"成交量": "volume",
"换手率": "turn_over",
"成交额": "amount",
},
inplace=True,
)
# 只取cols这几列数据
df = df[["date", "open", "high", "low", "close", "volume"]]
df["symbol"] = symbol
print(df)
csv_path = DATA_DIR.joinpath(DATA_DIR_QUOTES, f"{symbol}.csv")
with open(csv_path, "w") as f:
df.to_csv(f, index=False)
print(df)
if __name__ == "__main__":
# symbols = [
# '511220.SH', # 城投债
# '512010.SH', # 医药
# '518880.SH', # 黄金
# '163415.SZ', # 兴全商业
# '159928.SZ', # 消费
# '161903.SZ', # 万家行业优选
# '513100.SH' # 纳指
# ] # 证券池列表
symbols = [
"511220.SH", # 城投债
"512010.SH", # 医药
"518880.SH", # 黄金ETF
"163415.SZ", # 兴全商业
"159928.SZ", # 消费
"161903.SZ", # 万家行业优选
"513100.SH", # 纳指
"159929.SZ", # 消费
"511010.SH", # 国债
"510300.SH", # 沪深300ETF
] # 证券池列表
symbols += ["513100.SH", "159934.SZ", "510880.SH", "159915.SZ"]
symbols += [
"513100.SH", # 纳指ETF
"515300.SH", # 红利地波
"511880.SH", # 银河利华
"159949.SZ", # 创业板50
"159985.SZ", # 豆粕ETF
"512100.SH", # 中证1000
]
# 下载标的数据
symbols = [
"511880.SH", # 银河利华
"511990.SH", # 华宝添益
]
symbols = [
"000300.SH", # 沪深300
"159915.SZ", # 创业板
"000012.SH", # 国债指数
"518880.SH", # 黄金ETF
"162411.SZ", # 华宝油气
]
symbols = list(set(symbols))
for symbol in symbols:
download_data(symbol)2.香港和纳值指数数据
import akshare as ak
import time
import pandas as pd
from config import DATA_DIR, DATA_DIR_QUOTES
def download_data(symbol):
print(symbol)
# 全部转换成大写
symbol = symbol.upper()
code = symbol
# 回测最好用后复权数据,前复权会有负数的问题
try:
if "HSI" == code:
# 香港恒生
df = ak.stock_hk_index_daily_sina(symbol=code)
elif "NDX" in code:
# 美国 纳值
df = ak.index_us_stock_sina(symbol=".NDX")
else:
df = pd.DataFrame()
except Exception as e:
print(f"Error fetching data for code {code}: {e}")
return pd.DataFrame()
df.rename(
columns={
"日期": "date",
"开盘": "open",
"收盘": "close",
"最高": "high",
"最低": "low",
"成交量": "volume",
"换手率": "turn_over",
"成交额": "amount",
},
inplace=True,
)
# 只取cols这几列数据
df = df[["date", "open", "high", "low", "close", "volume"]]
df["symbol"] = symbol
print(df)
csv_path = DATA_DIR.joinpath(DATA_DIR_QUOTES, f"{symbol}.csv")
with open(csv_path, "w") as f:
df.to_csv(f, index=False)
print(df)
if __name__ == "__main__":
symbols = []
# 香港
# 恒生指数
symbols = [
"HSI", # 香港恒生
]
# 美国
# {".IXIC", ".DJI", ".INX", ".NDX"}
symbols += [
".NDX", # 纳指
]
symbols = list(set(symbols))
for symbol in symbols:
download_data(symbol)二.运行策即可
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/268140
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!