
一 本文概要
金融市场数据具有复杂性和随机性,传统的资产建模方法通常依赖于手工特征或统计度量,但这些方法在捕捉市场数据中的复杂依赖关系和动态变化时往往力不从心。随着高频交易数据的增加和金融工具的复杂性日益提升,亟需更为先进的数据驱动方法来学习资产的表示。本文提出了一种基于对比学习的新框架,通过从金融时间序列数据中生成资产嵌入。该方法利用资产收益在多个子窗口上的相似性,生成有信息量的正负样本,并基于假设检验的统计采样策略来应对金融数据的噪声特性。实验结果显示,本文方法显著优于现有基线方法,突显了对比学习在捕捉金融数据中有意义且可操作的关系方面的潜力。
二 背景知识
表示学习(Representation Learning)
表示学习是一种机器学习方法,旨在自动发现和学习数据的有效特征表示。传统的机器学习方法通常依赖于手工设计的特征,这不仅费时费力,还可能导致特征不全面或不准确。表示学习通过训练模型直接从原始数据中提取有用的特征,减少对手工特征工程的依赖,提升模型在各种任务上的性能。自动编码器(Autoencoders)和卷积神经网络(Convolutional Neural Networks, CNNs)是表示学习的常用技术。自动编码器是一种无监督学习模型,通过训练其将输入数据编码成低维表示,再从这种表示重构出输入数据。这种方法能够有效捕捉数据的本质结构和模式。卷积神经网络特别适用于图像数据,通过层级结构自动学习图像的特征表示。低层次的卷积层捕捉简单的局部特征(如边缘、纹理),高层次的卷积层捕捉复杂的全局特征。这些表示可以用于各种任务,如分类、回归、图像分割和生成等。
表示学习还包括其他方法,如主成分分析(PCA)、t-SNE等降维技术,词嵌入(如Word2Vec、GloVe)和图嵌入(Graph Embedding)等自然语言处理和图数据处理技术。通过这些方法,表示学习可以在不同类型的数据和任务中发挥重要作用,提升模型的泛化能力和性能。
资产嵌入学习(Asset Embedding Learning)
资产嵌入学习是一种专门为金融领域设计的表示学习技术,旨在将金融资产(如股票、债券、基金等)映射到低维向量空间中。这种低维向量表示可以捕捉资产之间的相似性和关系,从而便于进行后续的分析和预测任务。通过将资产表示为嵌入向量,金融分析师和算法能够更有效地处理和理解复杂的金融数据。
资产嵌入学习的应用包括投资组合优化、风险管理和市场预测等任务。例如,通过将股票嵌入到一个低维空间,可以发现具有相似特征的股票群体,帮助投资者构建多样化的投资组合,减少风险。同时,这种嵌入表示还可以用于预测股票价格走势,识别市场趋势和异常事件。具体方法包括使用深度学习模型(如图神经网络,Graph Neural Networks, GNNs)来捕捉资产之间的关系,或使用时间序列嵌入技术(如LSTM、Transformer)来捕捉资产随时间变化的动态特征。通过资产嵌入学习,金融决策的准确性和效率可以得到显著提升,帮助金融机构和投资者做出更明智的决策。
三 本文方法
本文提出了一种新的对比学习框架,用于从金融时间序列数据中学习资产嵌入。我们的目标是通过利用资产在多个滚动子窗口中的收益相似性来捕捉资产之间的复杂关系和相似性。具体方法包括以下几个步骤:
问题设置和符号说明
设A = {𝑎1, 𝑎2, … , 𝑎𝑁}为一组N个金融资产,每个资产𝑎𝑖都有一个每日收益的时间序列r𝑎𝑖 = {𝑟𝑎𝑖1, 𝑟𝑎𝑖2, … , 𝑟𝑎𝑖𝑇}。我们的目标是学习一个嵌入函数𝑓 : A → R𝑑,将每个资产𝑎𝑖映射到一个d维的嵌入向量e𝑖 ∈ R𝑑,使得这些嵌入能够捕捉资产之间的底层关系和相似性。
生成正样本和负样本
对比学习的关键在于生成正样本和负样本。我们提出了一种基于资产收益相似性的统计采样策略。具体来说,给定一个资产𝑎𝑖,我们考虑一个长度为w、步长为s的滑动窗口,并计算每个窗口内资产𝑎𝑖与所有其他资产的收益子序列之间的相似性。然后构建一个共现计数矩阵C,其中每个条目C𝑖,𝑗表示资产𝑎𝑗在所有滑动窗口中与资产𝑎𝑖最相似的资产中出现的次数。
采样策略
为了生成正样本,我们提出了一种基于比例假设检验的采样策略。具体来说,我们计算每对资产(𝑎𝑖, 𝑎𝑗)的p值,并根据p值选择正样本和负样本。正样本是那些与资产𝑎𝑖共现次数显著高于随机情况的资产,而负样本则是那些共现次数显著低于随机情况的资产。
对比损失函数
我们探索了三种对比损失函数,分别是独立Sigmoid损失、聚合Sigmoid损失和混合Sigmoid-Softmax损失。这些损失函数通过最大化锚定资产与正样本的相似性并最小化锚定资产与负样本的相似性来学习资产嵌入。

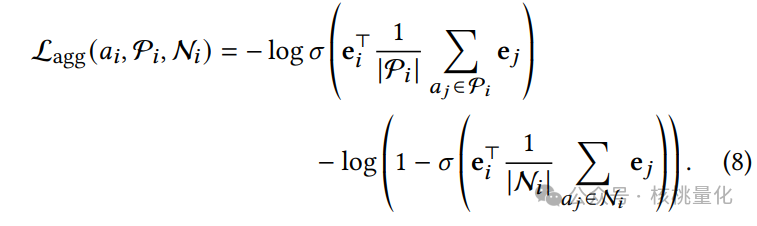
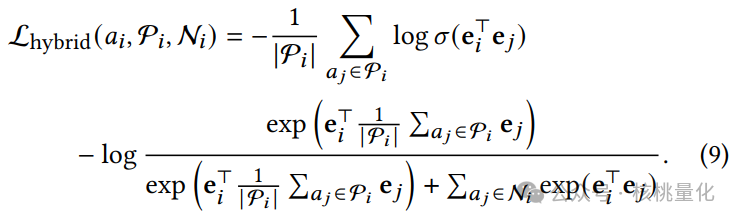
训练和优化
我们使用Adam优化器进行小批量随机梯度下降训练资产嵌入。在每次训练迭代中,我们采样一批锚定资产及其对应的正样本和负样本,计算对比损失并更新嵌入矩阵。为了防止过拟合并鼓励学习到的嵌入在单位超球面上均匀分布,我们对嵌入向量应用L2正则化。此外,我们还使用学习率调度器,当正样本部分的损失趋于平稳时,减少学习率,从而在训练后期对嵌入进行微调。
算法的整体伪代码如下:

四 实验结果
实验部分在两个重要任务上评估了对比学习方法的效果:行业部门分类和投资组合优化。实验结果表明,我们的方法在这些任务上显著优于传统方法和现有的最先进方法。
数据集和实验设置
我们使用一个公开的、真实世界的金融数据集,该数据集包括2000年至2018年间611只美国股票的每日收益。对于对比学习框架,我们设置嵌入维度为d = 16,滑动窗口长度为w = 22,步长为s = 5,相似资产的数量为k = 5。我们使用皮尔逊相关系数作为收益子序列之间的相似性度量。
实验结果分析
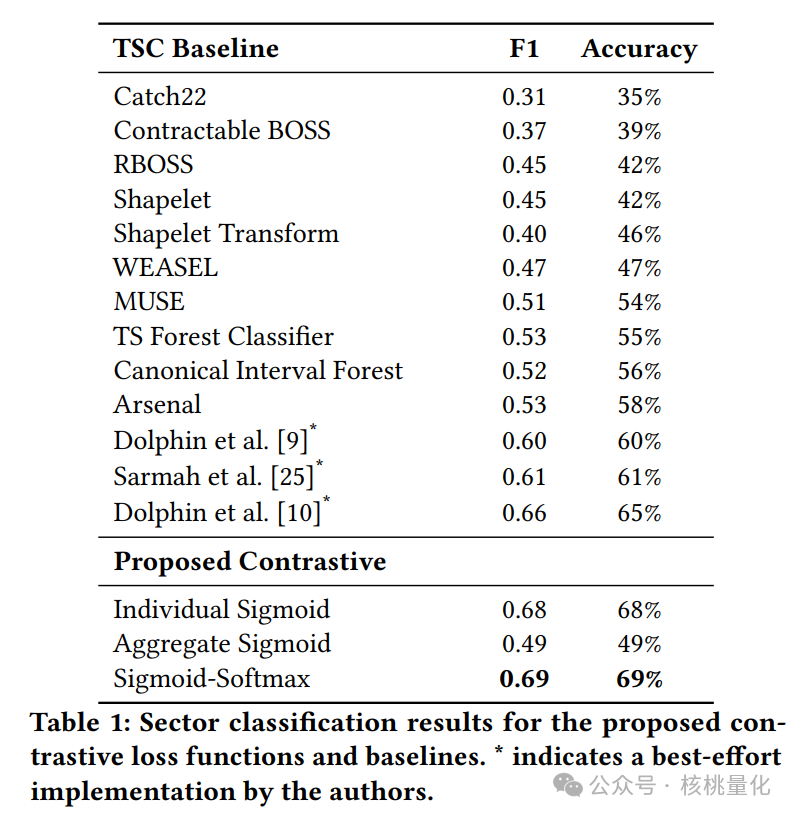
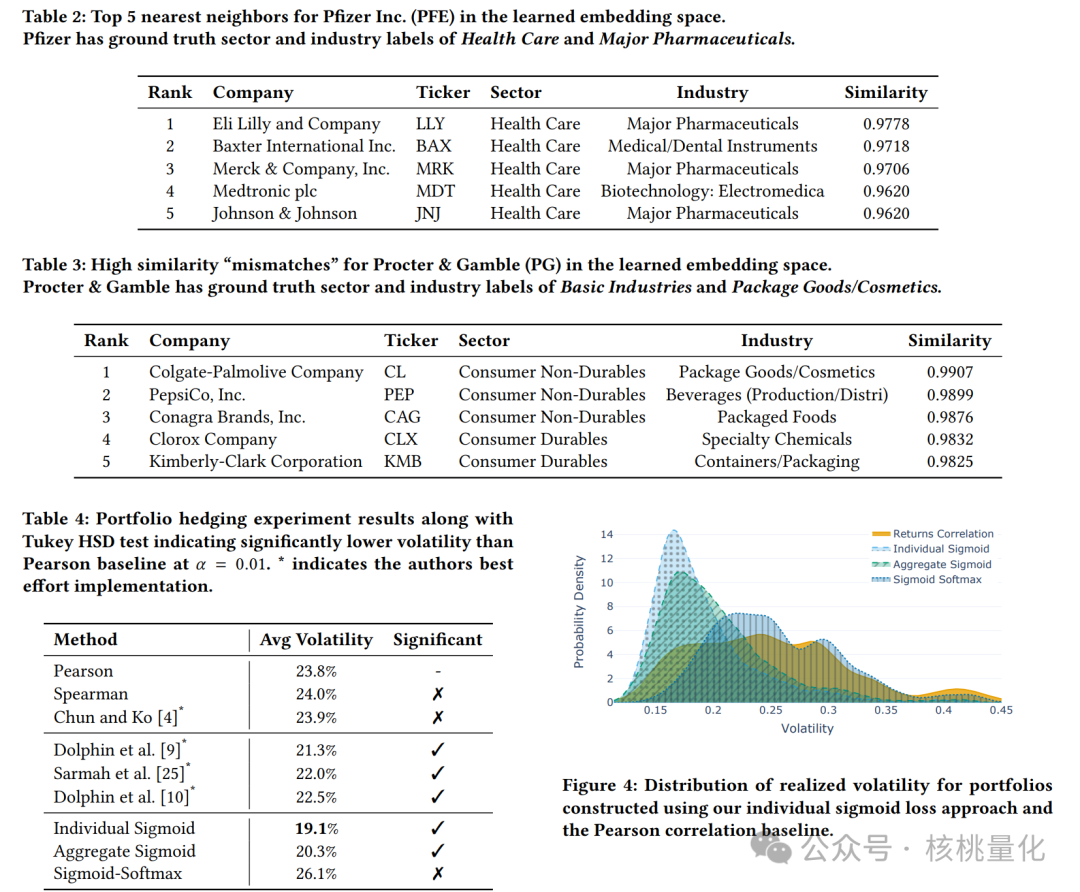
我们首先考虑行业部门分类任务,这是一个常用的基准评估任务。我们使用学习到的嵌入作为输入特征,训练支持向量机分类器,并进行5折交叉验证。实验结果表明,使用Sigmoid-Softmax损失的对比学习方法在所有指标上表现最佳,F1分数为0.69,准确率为69%。这表明我们学习到的嵌入在捕捉资产之间的行业级别相似性和关系方面非常有效。为了进一步展示所学资产嵌入的实用价值,我们进行了一个简单的对冲任务,旨在模拟投资组合优化。对于每个目标资产,我们根据嵌入空间中的相似性信息选择一个对冲资产,并构建一个简单的两资产投资组合。实验结果表明,使用独立Sigmoid损失的对比学习方法实现了最低的平均波动率19.1%,显著优于基于皮尔逊相关系数的基线方法。
五 总结展望
本文提出了一种基于对比学习的资产嵌入学习框架,从金融时间序列数据中捕捉资产间的复杂关系。实验结果显示,所提方法在行业分类和投资组合优化任务上表现优异,突显了其实际应用价值。未来的研究可以进一步探索该框架在非金融时间序列数据中的应用,及其在更大规模数据集上的扩展能力。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111078
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!