
一 本文摘要
传统的金融贝塔系数估计方法往往依赖于严格的假设,难以准确捕捉 Beta 的动态变化,这限制了它们在实际应用中的有效性。为了解决这些问题,本文开发了一种新方法:NeuralBeta,利用神经网络进行Beta的有效估计。该方法能够处理单变量和多变量场景,并跟踪 Beta 的动态变化。为了提高模型的可解释性,本文引入了一种类似于正则化加权线性回归的新输出层,使模型的决策过程更加透明。通过在合成数据和市场数据上进行了大量实验,结果表明 NeuralBeta 在各种情况下,尤其是在 Beta 变化较大的情况下,表现优于传统方法。
二 背景知识
2.1 贝塔系数(β)
贝塔系数(β)是在金融学中用于衡量单个资产相对于整个市场的风险度量。它表示资产收益与市场收益之间的线性关系,是资本资产定价模型(CAPM)中的重要参数。贝塔系数可以帮助投资者了解资产在市场波动中的敏感性,从而在资产定价、组合优化和风险管理等方面提供重要参考。
2.2 贝塔系数的估计方法
普通最小二乘法(OLS)
普通最小二乘法(OLS)是最常见的贝塔系数估计方法。通过对资产收益和市场收益进行线性回归,可以得到贝塔系数的估计值。具体步骤如下:
-
收集资产和市场的历史收益数据。 -
建立线性回归模型,其中截距项表示独立于市场收益的部分,贝塔系数表示资产收益对市场收益的敏感性,误差项表示随机波动。 -
使用最小二乘法估计模型参数。
滚动回归
由于市场条件和资产特性会随时间变化,贝塔系数也可能是动态的。滚动回归方法通过在移动窗口内进行多次回归,捕捉贝塔系数的时间变化。具体步骤如下:
-
选择一个固定长度的回溯窗口。 -
在每个时间点,对回溯窗口内的数据进行线性回归,估计贝塔系数。 -
将估计的贝塔系数用于下一个时间点的预测。
加权最小二乘法(WLS)
加权最小二乘法(WLS)通过对不同时间点的数据赋予不同的权重,来提高贝塔系数估计的准确性。一般来说,较近的数据点被赋予更高的权重。具体步骤如下:
-
定义权重矩阵,其中对角线元素表示各时间点的数据权重。 -
使用加权最小二乘法进行回归,估计贝塔系数。
机器学习方法
近年来,机器学习方法被引入贝塔系数的估计中,以捕捉更复杂的非线性关系和动态变化。例如,神经网络可以通过训练大量历史数据,学习资产收益与市场收益之间的复杂模式,从而提供更精确的贝塔系数估计。这些方法在处理高维数据和非线性关系方面表现出色,进一步提升了贝塔系数估计的准确性和鲁棒性。
三 本文方法
在资产定价中,𝛽被用于评估资产的回报,例如基于市场组合的回报(资本资产定价模型,CAPM)或一组风险因子和市场指数(套利定价理论,APT)。由于各类市场动态的影响,𝛽会随时间变化,这给估计带来了挑战。为了应对这些挑战,我们提出了一种新的深度神经网络方法,称为NeuralBeta,其能够捕捉金融数据中的复杂非线性关系,提供更精准和稳健的𝛽估计。此外,我们还开发了一个可解释版本,称为NeuralBeta-Interpretable (NBI),以提高模型的透明度和可解释性。
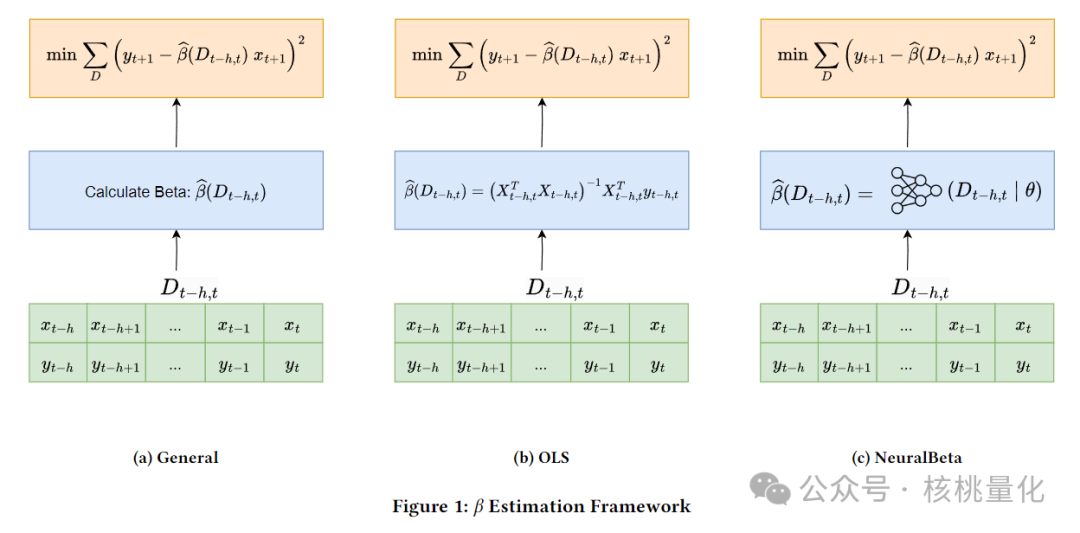

图1a展示了如何进行β估计的一般方法。输入是一个回溯窗口内的x和y数据。然后将这些数据输入模型f来估计β。这个模型可以有一些参数,比如神经网络,如图1c所示的NeuralBeta,或者可以没有参数,比如普通最小二乘法(OLS,图1b)。基于上述讨论,我们提出了一个使用神经网络来表示β估计器的框架。设θ为参数集,NeuralBeta模型被公式化为: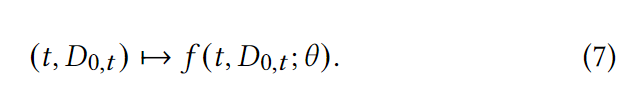
如图1c所示,NeuralBeta模型不是使用一些预定的公式,而是动态地估计目标时期的β。更重要的是,与回归方法不同,NeuralBeta包含许多参数,可以在训练过程中适当地学习。单个NeuralBeta模型被用于所有的x和y对,所以模型在每对上全面训练,而不是在一个单独的对上。这种整体方法使NeuralBeta模型能够从各种对中出现的共同模式中学习。基于单个目标资产情况的讨论,我们可以进一步扩展该方法以处理多个时间序列的联合对冲或预测任务。一个典型的例子是因子模型。假设有多个目标资产的时间序列y_i_t,可以通过共同因子时间序列和特有变量来解释。对于每个资产i,我们有类似的符号表示解释变量x_i_t,数据集D_i。目标函数被扩展到多个时间序列情况为: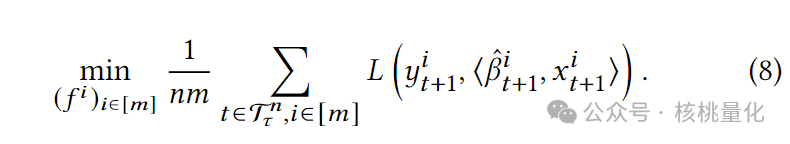
注意,这里的自变量是对应于每个资产的函数向量f_i,而不是单个函数,但我们仍然可以使用一个大的神经网络来表示该向量,即f_i = f_{i+1} = … = f_m。我们在训练模型时使用的损失函数是均方误差(MSE):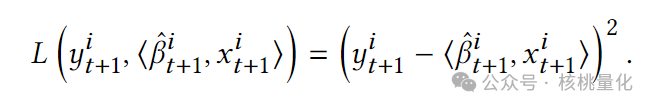
可解释的神经网络架构
使用神经网络进行β估计的一个问题是缺乏可解释性。为了解决这个问题,我们引入了一种新的输出层,使用正则化加权线性回归:
其中权重W_{t−h,t}为正值,Σ是正定矩阵。μ和Σ可以解释为β的高斯先验的均值和协方差。注意,权重是正的,但无界;这是为了让模型选择依赖先验的程度,即小权重导致更多的正则化,而大权重导致较少的正则化。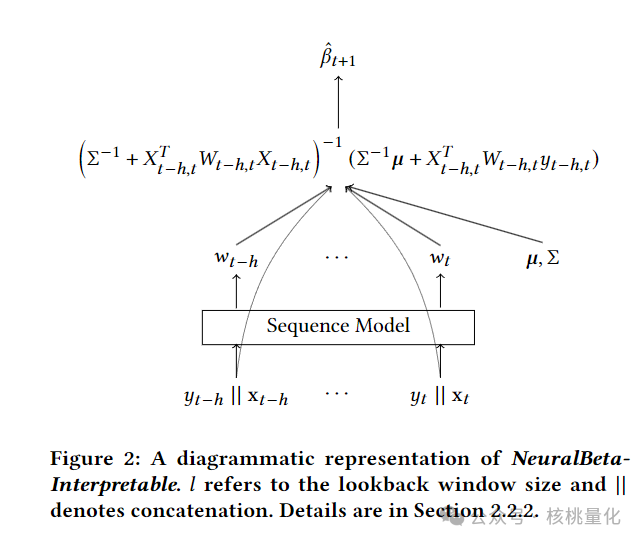
在NeuralBeta中,μ和Σ是需要训练的全局参数,我们限制Σ为对角矩阵。图2展示了我们的方法的高级图表,我们称之为NeuralBeta-Interpretable(NBI)。类似于NeuralBeta中的神经网络是β估计器的替代品,NBI中的”神经”可以解释为在给定上下文窗口的情况下隐式调整权重。
四 实验分析
4.1 合成数据实验
本文在合成数据上进行了三种不同类型的β估计实验:常数β、阶跃β和周期性β。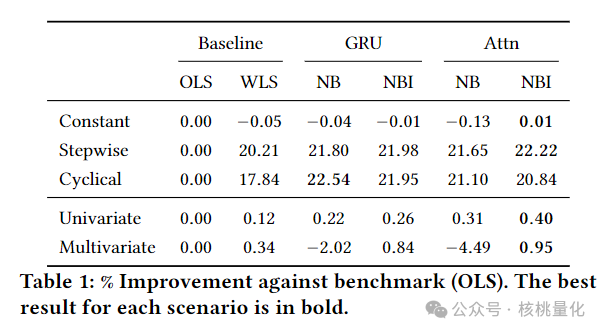
-
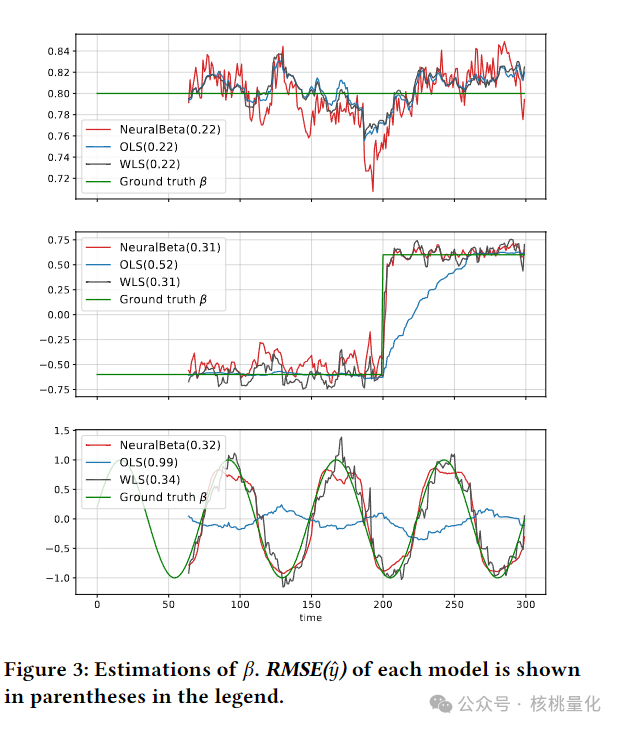
常数β:NeuralBeta在常数β场景下略微优于OLS,尽管理论上OLS已经接近最优解。这表明NeuralBeta即便在简单场景下也能有效工作。 -
阶跃β:在阶跃β场景中,NeuralBeta和WLS显著优于OLS,且表现几乎相同。WLS使用了半衰期为2的加权策略,NeuralBeta自动识别并应用了这种策略。 -
周期性β:NeuralBeta在周期性β场景中表现出色,超过了OLS和WLS。尽管WLS可以跟踪正弦波的趋势,NeuralBeta提供了更平滑和更准确的估计,同时保持了同样的响应水平。
4.2 市场数据实验
本文使用了2010-2023年的市场数据,包括S&P 500指数、大小因子和价值因子指数,以及S&P 500成分股的日收益率。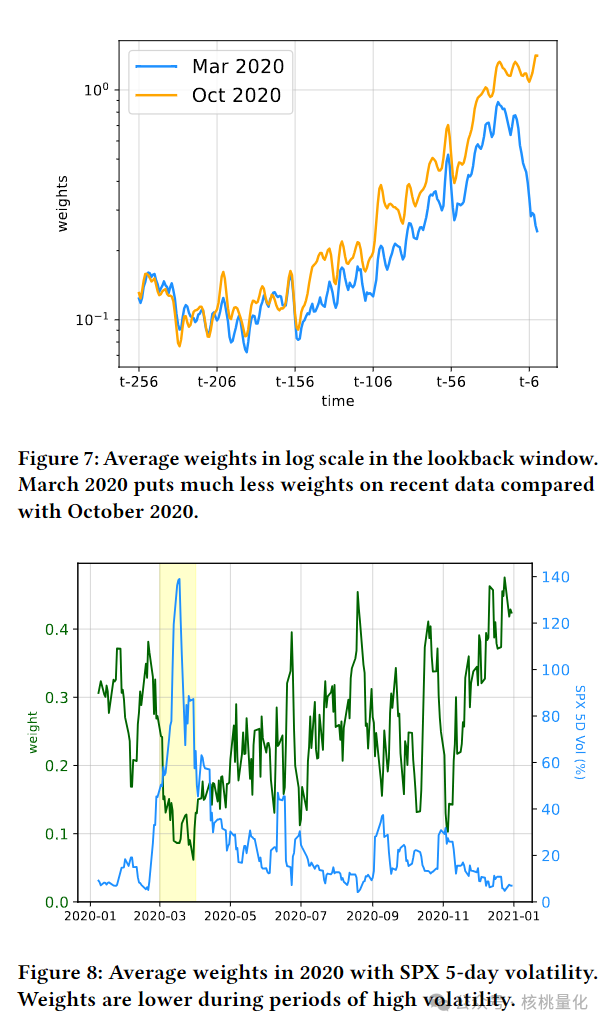
-
单变量(CAPM):在单变量场景中,NeuralBeta的表现略优于GRU,且可解释的架构(NBI)在测试集上的表现优于普通架构。图7展示了在COVID-19初期和2020年10月期间,模型对回溯窗口内各滞后数据点分配的平均权重。结果表明,模型在高波动时期对最近数据点分配较低权重,而在市场稳定时期对最近数据点分配较高权重。 -
多变量(因子模型):在多变量因子模型中,NBI架构表现最佳,而非解释性NeuralBeta模型的表现略逊于基准方法。图8显示了S&P 500成分股在2020年的平均权重与SPX 5日波动率的关系,表明模型能够适应市场变化。
4.3 超参数调优
通过图9,本文展示了不同超参数设置下NeuralBeta和NBI的验证集RMSE(均方根误差)。结果表明,较长的回溯窗口、更适中的隐藏层大小和丢弃率能够提供更好的结果。尽管在验证集上NBI的表现略逊于普通NeuralBeta,但在测试集上NBI表现更佳,且在不同配置下表现更稳定。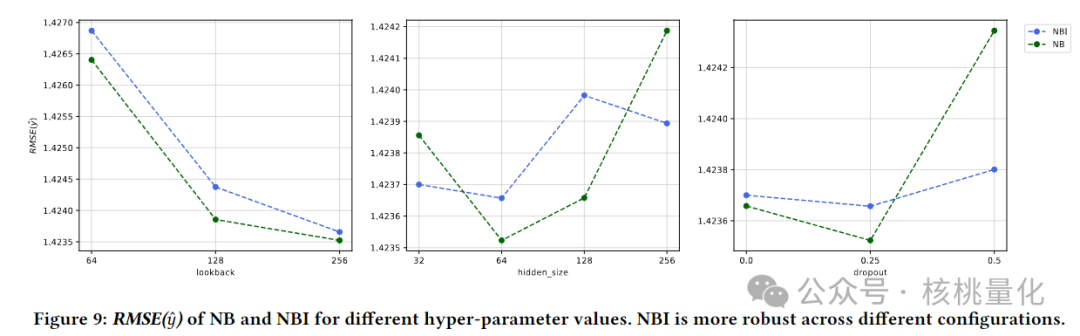
五 总结展望
本文提出了NeuralBeta,一种基于深度神经网络的全新β估计方法。该模型有效地解决了传统β估计方法中存在的若干挑战,特别是应对β值动态变化和模型透明性问题。此外,本文还开发了一种可解释的神经网络架构NeuralBeta-Interpretable(NBI),不仅提高了模型的透明度,还在某些情况下提升了性能。通过在合成数据和市场数据上的广泛实验,本文验证了NeuralBeta的效率和稳健性。结果表明,在不同场景中,NeuralBeta的性能均优于基准方法。本文还展示了NBI生成的权重示例,帮助用户理解模型的决策机制。
未来的研究可以进一步探索NeuralBeta在不同金融环境中的适用性,并结合更多的市场因子和复杂的市场条件来测试其鲁棒性。此外,改进模型的训练效率和实时应用能力也是值得关注的方向。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111079
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!