
昨天有同学留言说,为何要使用mongo,而不是直接把数据下载到hdf5里。
其实,如果是一次性数据下载,确实直接保存到hdf5,然后使用pandas本地加载是最为合适的。
但如果要做成在线服务,可以每天自动更新数据。hdf5增量更新的功能有限。还是需要数据库支持。
在做数据分析时,可以把数据下载到本地,写入hdf5文件,而且统计读出,合成到一个统一的大文件里,进行排序及其它运算。
datas = []
with pd.HDFStore('all.hdf5') as store:
for key in store.keys():
if 'all' in key:
continue
df = store[key]
df['code'] = key.replace('/', '')
datas.append(df)
all = pd.concat(datas)
all.sort_index(ascending=True, inplace=True)
store['all'] = all
with pd.HDFStore('all.hdf5') as store:
df = store['all']
sub_df = df.loc['20230113']
sub_df.set_index('code', inplace=True)
sub_df['转股溢价_rank'] = sub_df['转股溢价'].rank()
sub_df.sort_values(by='转股溢价_rank', inplace=True)print(sub_df)
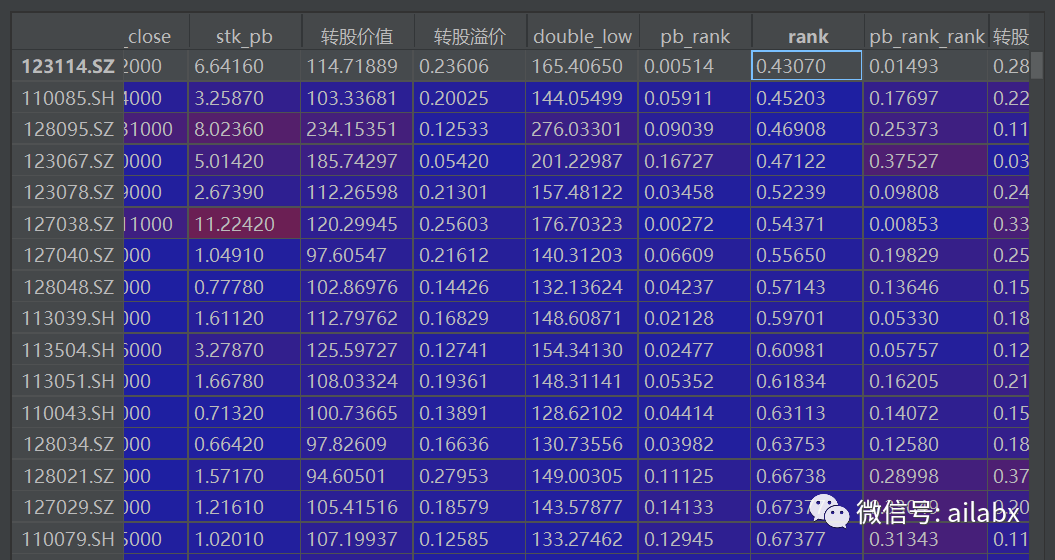
使用多因子对400多支可转债进行排序:
cols_rank = [] sub_df['rank'] = 0.0 for col in ['pb_rank','转股溢价','-dt_netprofit_yoy']: asc = True if '-' in col: asc = False col = col.replace('-', '') cols_rank.append(col+'_rank') sub_df[col+'_rank'] = sub_df[col].rank(ascending=asc,pct=True) sub_df['rank'] = sub_df['rank'] + sub_df[col+'_rank'] sub_df.sort_values(by='rank', inplace=True)
如下就是多因子选债的最新结果:

后续对因子进行ic分析,以及对多因子模型进行回测。
关于基金的转换与赎回
昨天对一部分盈利的基金进行了转换,今天看到手续费,突发奇想要计算一下,没算明白。电话客服,说了各种细节,也没算明白。
后来打基金公司电话,搞明白几点:
一、有的基金是条款变更了,比如后来把手续费降下来了。这时候查之前的交易记录就会特别困惑,我有一支就是超过7天没有手续费,结果发现交易中有手续费,就特别困惑。
二、定投中途有过卖出记录。这个一眼看不过还真看不太明白。
逻辑上讲,现在都是电子交易,计算出错的可能性不大。主要是加深一下自己的理解,而且感受一下,交易成本的摩擦费用不小。
话说,有一笔交易,差几天就超过3年,就没有手续费了。结果当然没有仔细看。手续率是万20,呵。
下面说说NLP的一些进展
无论是做量化投资、机器学习还是自然语言处理,其实很多时间是花在数据准备、数据预处理,数据加工,特征工程上的。本身策略或者模型反倒简单。另外的的时间就是机器自己算的事情了。
自然语言处理,现在业界有句话叫,如果不用考虑上线,那就“无脑bert”。
bert虽好,就是费资源,无论是训练资源,还是上线后推理。
有时候杀鸡用牛刀,不太经济。
今天介绍一个好用的工具,facebook一个哥们开发的fasttext——即可以生成词向量,也可以做文本分类。
官网是https://fasttext.cc/
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104174
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!