
使用baostock获取可转债指数数据。
之前数据一直在使用tushare,尽管需要付一些费用,但不高。但发现中证转债指数000832.sh数据仅到2018年。而且之前还遇到北向资金数据也不更新了。
baostock不需要账户,不需要注册,也不需要付费。之前未使用主要是它只有A股股票,指数,财务数据,没有像可转债,ETF,场外基金这样的数据。目前看来,多个数据来源来互补充也是一种选择。
获取 A股 价量数据与 指数量价数据的函数是一样的,就是query_history_k_data_plus,比较方便。
import baostock as bs
import pandas as pd
from loguru import logger
class BaoStockUtils:
def __init__(self):
self.lg = bs.login()
logger.info('登录信息:' + self.lg.error_msg)
def query_data(self, code, factors):
factors.append('date')
factors = ','.join(factors)
rs = bs.query_history_k_data_plus(code, factors, frequency='d')
# 获取结果集
data_list = []
while (rs.error_code == '0') & rs.next():
# 获取一条记录,将记录合并在一起 data_list.append(rs.get_row_data()) result = pd.DataFrame(data_list, columns=rs.fields) return result if __name__ == '__main__': # 获取可转债指数 df = BaoStockUtils().query_data('sh.000832', ['close']) print(df) # 获取A股数据 df = BaoStockUtils().query_data('sz.000001', ['close']) print(df)
若是股票数据,还可以获取日频的pe, pb,ps等估值数据。
if __name__ == '__main__': # 获取可转债指数 df = BaoStockUtils().query_data('sh.000300', ['close','pbMRQ']) print(df) # 获取A股数据 df = BaoStockUtils().query_data('sz.000001', ['close','peTTM','pbMRQ']) print(df)

直接写入mongo数据库中,还是“单因子”,“列存”的模式:
def build_cb_index(): from logic.baostock_utils import BaoStockUtils code = 'sh.000832' factor = 'close' start_date = get_start_date(code, factor) logger.info('更新转债指数起始日期' + start_date) df = BaoStockUtils().query_data(code, [factor], start_date=start_date) # df['date'] = df['date'].apply(lambda x: x.replace('-','')) df.rename(columns={'close': 'value'}, inplace=True) df['factor'] = factor df['code'] = code df['_id'] = code + '_' + df['date'] + '_' + factor print(df) mongo_utils.write_df('cb_factors', df)
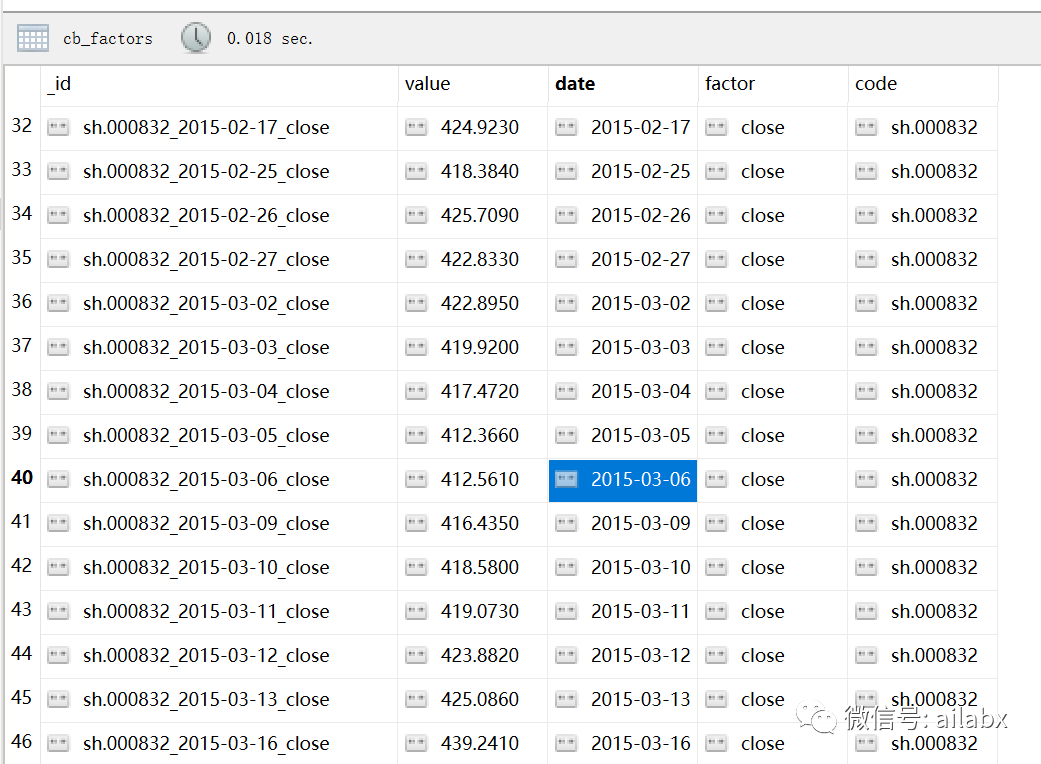
把491支可转债入库以后,因子数据不到100万条,还行:
后续可以进行可转债多因子模型的分析。
# 从mongo加载因子,并写入hdf5 import numpy as np import pymongo from logic.utils import mongo_utils import pandas as pd def load_factor(code): items = mongo_utils.get_db()['cb_factors'].find({'code': code}, {'_id': 0, 'code': 0}) df = pd.DataFrame(list(items)) return df if __name__ == '__main__': # code = ['123105.SZ', '110053.SZ', '123105.SZ', '123092.SZ', '127065.SZ'] cb_index = 'sh.000832' df_index = load_factor(cb_index) df_index['date'] = df_index['date'].apply(lambda x: x.replace('-', '')) df_index.set_index('date', inplace=True) df_index.rename(columns={'value': 'index'}, inplace=True) del df_index['factor'] # print(df_index) code = '123092.SZ' df = load_factor(code) df = pd.pivot_table(df, index='date', columns='factor', values='value') df = pd.concat([df, df_index], axis=1) # print(df) for col in ['chg_price', 'dt_netprofit_yoy']: df[col] = df[col].ffill() df.dropna(inplace=True) # df.sort_values(by='date', ascending=False, inplace=True) df['转股价值'] = 100 / df['chg_price'] * df['stk_close'] df['转股溢价'] = df['close'] / df['转股价值'] - 1 df['double_low'] = df['close'] + df['转股溢价'] * 100 df['pb_rank'] = df['stk_pb'].rank(pct=True) df['rate'] = df['close'].pct_change() df['index'] = df['index'].apply(lambda x: float(x)) df['index_rate'] = df['index'].pct_change() df.dropna(inplace=True) import statsmodels.api as sm from statsmodels import regression def linreg(x, y): x = sm.add_constant(x) model = regression.linear_model.OLS(y, x).fit() return model.params[0], model.params[1] alpha, beta = linreg(df['index_rate'], df['rate']) print(alpha, beta) # 多列滚动函数 # handle对滚动的数据框进行处理 def handle(x, df, name, n): df = df[name].iloc[x:x + n, :] print(df) return 1 # group_rolling 进行滚动 # n:滚动的行数 # df:目标数据框 # name:要滚动的列名 def group_rolling(n, df, name): df_roll = pd.DataFrame({'a': list(range(len(df) - n + 1))}) df_roll['a'].rolling(window=1).apply(lambda x: handle(int(x[0]), df, name, n), raw=True) group_rolling(252, df, ['rate', 'index_rate']) print(df)
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104175
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!