
一 本文概要
投资组合管理目标是决定怎样分配我们的资金到不同的股票或其他资产上,以便最大化我们的收益,同时控制风险。随着机器学习技术的发展,当前研究者们开始使用深度强化学习技术来改善投资决策。这种技术通过在模拟的市场环境中训练,让模型学习如何做出更好的决策。但是,这种方法也有一个问题,就是它可能会过于依赖在模拟环境中学到的策略,而这些策略在真实的市场中可能不适用。
为了缓解上述问题,本文引入了两种技术:对比学习和奖励平滑。对比学习可以使得强化学习模型能够识别可能预示未来价格变动的资产状态模式;奖励平滑作为一种正则化技术,防止模型过拟合追求即时但不确定的利润。通过对资产状态模式的识别和长期回报的追求,该方法在模拟环境中表现出色,并在美国股市和加密货币市场上取得了显著的收益提升。
二 背景知识
2.1 深度强化学习
深度强化学习(DRL)是一种结合了深度学习和强化学习的机器学习方法。它的目标是让计算机智能体通过与环境的交互学习如何做出最优的决策,以最大化预先定义的奖励信号。深度学习是指一类基于人工神经网络的机器学习方法,它能够从大规模的数据中学习表示和特征,以及对数据进行预测和决策。深度学习使用多层次的神经网络结构,每一层都对输入进行一系列非线性变换和特征提取,从而逐步学习到更高层次的抽象表示。强化学习是指一种学习范式,其中一个智能智能体通过与环境的交互来学习如何做出正确的决策。智能体根据当前环境的状态采取行动,并从环境中接收奖励或惩罚作为反馈。其目标是通过尝试不同的行动和观察结果来学习一个策略,使其能够在长期中获得最大化的奖励。
深度强化学习结合了这两个方法,使用深度学习网络作为强化学习中的函数近似器。深度神经网络可以接收环境的状态作为输入,并输出智能体的行动策略。通过训练网络,可以使其逐渐调整策略以最大化预期的长期奖励。
2.2 投资组合管理
投资组合管理是指管理和优化投资组合的过程,旨在最大化投资回报并控制风险。它涉及到选择适当的资产、分配资金以及监督和调整投资组合以适应市场变化。通常包含下述的重要概念和方法:
-
资产分配:资产分配是确定投资组合中不同资产类别的权重分配。这意味着决定在股票、债券、现金等不同资产类别之间分配资金的比例。资产分配的目标是实现预期回报,并控制投资组合的整体风险。 -
风险管理:风险管理是投资组合管理的核心。它包括识别和评估不同投资的风险水平,并采取适当的措施来减轻风险。常用的风险管理方法包括多样化投资组合、资产再平衡和使用衍生品工具进行对冲。 -
多样化:多样化是通过在投资组合中选择不同的资产类别、行业、地理区域等来分散风险。通过将投资分散到不同的资产,投资者可以降低特定资产的风险,并在整体上平衡回报和风险。 -
资产再平衡:资产再平衡是定期调整投资组合以恢复资产分配到目标比例的过程。当某些资产的表现超过预期时,它们的权重会增加,而其他资产的权重会减少。通过资产再平衡,投资者可以保持投资组合的目标配置,避免暴露在过度风险之下。 -
绩效评估:绩效评估是衡量投资组合表现的过程。投资者使用各种指标和方法来评估投资组合的回报、风险和相对于基准的表现。这些指标可以包括年化回报率、波动性、夏普比率等。 -
主动管理和被动管理:主动管理是指通过选择个别证券或市场时机来尝试超越市场表现。被动管理则是追踪特定市场指数或指数基金,以获取与市场相似的回报。投资者可以根据自己的投资目标和风险承受能力选择适合的管理方式。
三 本文工作
基于深度强化学习的投资组合管理是将深度强化学习应用于投资组合管理的方法。它结合了深度学习的表示学习和强化学习的决策优化,旨在通过自主学习和适应来优化投资组合的决策。它将投资组合管理看作是一个马尔可夫决策过程(MDP)。在这个过程中,智能体通过一系列资产重新分配来学习一种交易策略,以最大化投资组合的价值。在DRL方法中,投资组合管理被表示为一个MDP,其中包含以下要素:
状态(State):在金融投资组合管理中,状态代表了某个时间点的资产价格和投资组合权重。状态可以用一个包含历史价格和权重的向量来表示。
动作(Action):在每个时间点,智能体根据当前的状态选择一个动作,即重新分配资产权重的方式。动作可以通过一个向量来表示,其中包含了每个资产的权重比例。
奖励(Reward):智能体在资产价格上涨时获得奖励。为了更准确地模拟真实情况,考虑了交易成本。交易成本会减少投资组合的价值。
未来奖励折现因子(Future Reward Discount Factor):智能体在决策过程中考虑未来奖励的折现因子。折现因子决定了智能体对未来回报的重视程度。
智能体的目标是学习一个策略,即一个从状态到动作的映射,以最大化在长期内的期望回报。与传统的金融方法只解决一步优化问题不同,DRL方法通过对长期期望折现回报的最大化来进行优化。具体而言,智能体根据历史价格和权重信息作出决策,选择新的权重分配方案来调整投资组合。智能体通过迭代计算来确定交易成本,并根据资产价格的变化来更新投资组合的价值。最终,智能体的奖励是基于投资组合价值的增长情况。DRL方法通过将投资组合管理问题建模为一个MDP,并利用深度强化学习来学习最优的交易策略,以实现最大化投资组合价值的目标。这种方法通过考虑长期回报和交易成本等因素,能够更好地适应真实的金融环境。
3.1 对比学习
对比学习是一种方法,通过给神经网络展示不同于主要任务的视角来提升其创建强大表示的能力。在投资组合管理中,这个方法非常有用,因为决策投资的策略依赖于从数据中提取的表示。为了达到这个目的,我们希望将高度相关的表示分组在一起,因为在金融市场中,一个资产可能是另一个资产未来走势的先行指标。
如果两个资产(用(xi, xj)表示)可以相互帮助预测未来的价格趋势,我们将它们称为正样本对。反之,如果它们不能相互帮助,我们将其称为负样本对。这个概念如图1所示。需要注意的是,这些样本对可以来自不同的资产和不同的时间段,因为这种关系可能随时发生。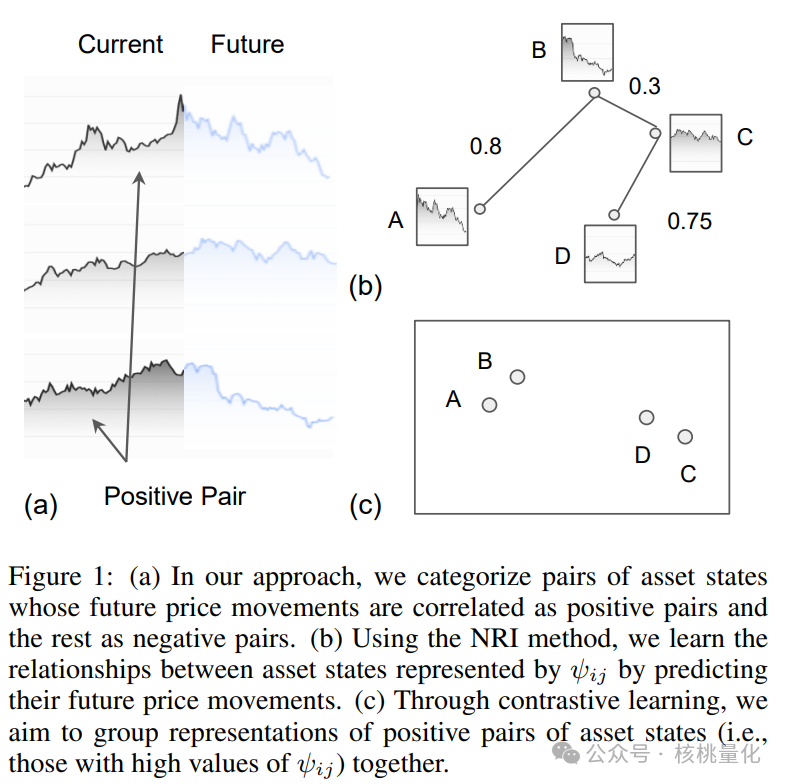

我们的策略网络包括一个编码器f,它将外部状态xi编码成一个表示zi(即zi = f(xi))。对于训练数据中的每个状态xi,我们找到对应的状态xj以生成正样本对,并应用对比奖励来训练编码器f。余弦相似度是衡量两个向量相似程度的指标。对于每个训练批次中的正样本对(xi, xj),我们最大化以下奖励: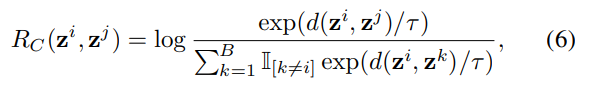 其中d(zi, zj)是向量zi和zj的余弦相似度,τ是一个温度参数。我们设P为正样本对的集合。总的对比奖励由RC = Σi,j∈P RC(zi, zj)给出。
其中d(zi, zj)是向量zi和zj的余弦相似度,τ是一个温度参数。我们设P为正样本对的集合。总的对比奖励由RC = Σi,j∈P RC(zi, zj)给出。
对比学习通过将具有相似特征的资产表示分组在一起,来加强神经网络的表示能力。这样的学习方式有助于提升投资组合管理中的决策策略,并从数据中提取更好的特征表示。
3.2 正样本匹配预测
当我们想要确定哪些资产状态可以互相帮助预测未来价格走势时,我们使用了一种叫做神经关系推断(NRI)的方法。神经关系推理(NRI)是一种基于图神经网络(GNN)的技术,它通过历史数据自动学习资产之间的复杂关系。与传统的变分自编码器(VAE)不同,NRI不仅分析单个资产状态,而是将一批资产状态作为整体来考虑,从而更全面地预测市场趋势。
NRI的编码器部分是一个完全连接的GNN,它通过消息传递机制在网络的节点(代表资产)和边(代表资产间的关系)之间交换信息。这个过程涉及到一系列的变换,将输入的资产状态转换为能够揭示资产间关系的表示形式。解码器部分则负责基于当前的资产状态和已学习的关系来预测未来的价格变动。它的目标是最大化证据下界,这是一种衡量模型预测准确性的指标。为了避免短期内价格波动过小导致的问题,解码器还被设计为能够预测多个未来价格步骤。
正样本匹配预测算法的核心在于识别那些能够相互预测未来价格变动的资产状态对,即正样本对。通过最大化对比奖励,算法鼓励模型使这些正样本对的表示形式更加接近,而不相关状态的表示则保持区别。这种方法不仅提高了模型预测未来价格变动的能力,也增强了智能体在面对市场不确定性时的鲁棒性。
3.3 奖励平滑
在每个时间周期t,智能体的目标是最大化其即时奖励RT,这通常涉及到最大化其投资组合的回报。然而,如果智能体只关注即时回报,它可能会过度适应历史训练数据中的特定模式,而这些模式可能无法准确预测未来的价格变动,因为市场价格变动本质上是不可预测的。
为了避免这个问题,研究者提出了一种奖励平滑的方法。这种方法考虑了连续时间周期的相似性,并通过引入一个变量F来表示用于平滑的未来时间步数。智能体现在不仅要最大化即时奖励RT,还要最大化平滑后的奖励sRT。平滑后的奖励sRT是通过在一段时间内累积的奖励的对数平均值来计算的,这些奖励包括了从当前时间周期到未来F个时间周期的回报。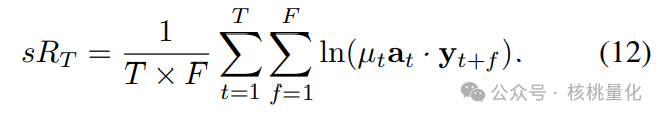 与在时间序列应用中常用的时间连续批次不同,奖励平滑不是让智能体在每个时期独立交易,而是鼓励智能体在连续时期采取能够带来类似利润的行动。这意味着智能体的行动不再是独立的,而是旨在实现跨多个未来时期的稳定利润。这有助于提高智能体在面对市场波动和不确定性时的鲁棒性,并可能提高其在实际交易中的性能。
与在时间序列应用中常用的时间连续批次不同,奖励平滑不是让智能体在每个时期独立交易,而是鼓励智能体在连续时期采取能够带来类似利润的行动。这意味着智能体的行动不再是独立的,而是旨在实现跨多个未来时期的稳定利润。这有助于提高智能体在面对市场波动和不确定性时的鲁棒性,并可能提高其在实际交易中的性能。
3.4 确定性策略梯度方法
我们使用了一种称为确定性策略梯度的强化学习方法。在这个方法中,我们将整个投资过程的状态-行动-奖励轨迹表示为一个序列,记录了每个时间步的状态、行动和奖励。在每个时间步,智能体器根据当前的状态来决定每个资产的分配权重。
我们的目标是在多次交易后最大化最终的投资组合价值。为了帮助智能体器学习有效的策略,我们还引入了两个额外的目标:平滑奖励和提取鲁棒表示。平滑奖励的目的是避免智能体器过度拟合训练数据,因为价格的变动是不可预测的。提取鲁棒表示则是为了让智能体器能够更好地做出决策。
为了综合考虑这些目标,我们定义了智能体器的整体奖励。这个整体奖励由三部分组成:最终投资组合价值、平滑奖励和鲁棒表示。我们使用权重来平衡这些奖励的重要性。具体来说,我们使用一个基于对数投资组合价值的指数函数来确定平滑奖励的权重。当智能体器获得较少或负回报时,权重较高,以指导智能体器尽量避免亏损。而鲁棒表示的权重则由另一个参数来调整。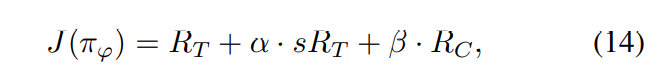
3.5 训练设置
输入
智能体的输入是状态st=⟨xt,wt⟩,它由历史资产价格和资产权重组成。外部状态xt包含了过去k个时间步的收盘价、最高价和最低价。为了预处理这些数据,资产价格通过除以前一时期的价格并减去一个常数1来进行标准化。通过卷积层提取每个资产的表示,然后将所有资产的表示连接起来,并通过另一组卷积层输出一个动作。
超参设置
在训练过程中,使用AdamW优化器来训练网络,折扣因子γ设置为1,奖励平滑窗口长度F设置为5,温度参数τ设置为0.05。学习率根据市场的不同进行调整,美国股市和加密货币市场分别设置为0.0001和0.00015,批量大小也根据市场特性进行设定。
训练和回测
智能体采用在线学习的方式进行训练。在回测阶段,智能体在训练集上进行初步训练后,通过不断地纳入新样本并评估来更新策略。这个过程使用几何分布概率函数来采集训练数据,其中γ参数用于控制最近状态的重要性。
NRI模型
NRI是模型中的一个关键组成部分,它的编码器和解码器是两个具有32个隐藏单元和ELU激活函数的全连接层。NRI的训练同时进行,使用相同一批样本,并针对不同市场调整学习率和温度参数。为了避免偏差,每批资产状态被打乱,并为对比学习分成小组。NRI被训练为学习每个小组内样本状态之间的关系,而不是整个批次。
四 实验分析
4.1 实验设置
我们选择了美国股市和加密货币市场作为评估的对象,从Yahoo Finance和Poloniex的官方API获取了相关数据,选取了交易量较高的资产进行实验。在美国股市方面,我们收集了九只交易量最高的股票的每日频率数据。在加密货币市场方面,我们收集了十种交易量最高的加密货币的半小时频率数据。为了确保公平比较,我们对比了不同方法在不同市场条件下的表现。我们对美国股市和加密货币市场的数据进行了分期,并将最后一年的数据用于测试。测试期的长度取决于数据的频率,代理每天或每30分钟进行一次交易。为了减少初始化对结果的影响,我们使用了8个不同的随机种子训练代理,并计算它们的平均组合价值。我们还进行了一些额外的实验,评估了我们提出的对比奖励和奖励平滑技术的有效性。
对比的基线方法包括了一些传统方法和深度强化学习方法进行了比较。传统方法包括买入并持有、统一常数再平衡组合(UCRP)、在线移动平均回归(OLMAR)和加权移动平均均值回归(WMAMR)。深度强化学习方法包括深度组合管理(DPM)和状态增强强化学习(SARL)。我们从相关论文和开源代码中获取了这些方法的实现。
我们使用一些标准评估指标来比较投资策略的性能,包括组合价值、夏普比率和最大回撤。这些指标不完美,所以我们需要综合考虑它们来评估方法的优劣。
7.3 实验分析
下表的实验结果显示,与传统的投资策略相比,深度强化学习方法在大多数情况下表现更好。本文的方法在股市整体上涨时表现良好,并在加密货币市场上实现了较高的回报。然而,需要注意的是,深度强化学习方法也带来了一些风险,特别是在高回报的情况下可能伴随着高风险。
本文的方法相对于其他深度强化学习方法(如DPM和SARL)具有优势,它在投资组合价值和夏普比率方面表现更好。这一优势可以归因于我们采用的对比学习、奖励平滑和更深的策略网络。在加密货币市场上,我们的模型表现尤为出色,这可能是因为我们的代理能够更频繁地进行交易,并实现复利和更高的回报。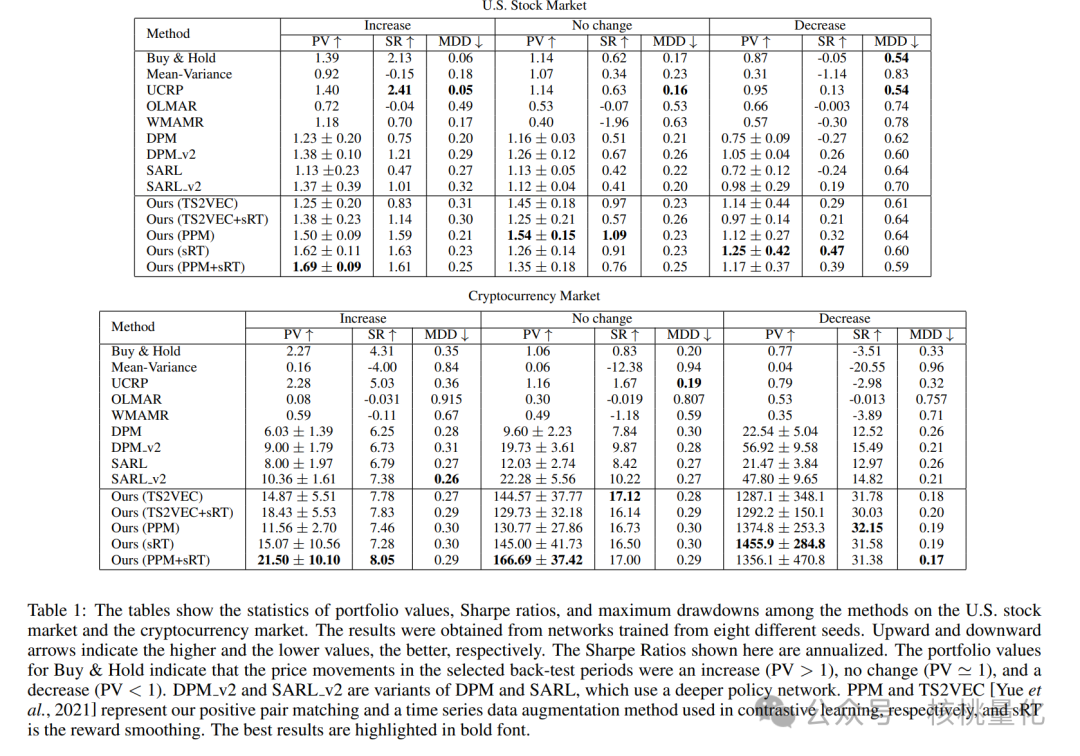
消融实验方法本文的方法相对于其他深度强化学习方法(如DPM和SARL)具有优势,它在投资组合价值和夏普比率方面表现更好。这一优势可以归因于我们采用的对比学习、奖励平滑和更深的策略网络。在加密货币市场上,我们的模型表现尤为出色,这可能是因为我们的代理能够更频繁地进行交易,并实现复利和更高的回报。
五 总结展望
本文引入了两种技术:对比学习和奖励平滑来提升强化学习的表现并在实验环境中获得显著的效果。然而,需要注意的是,这些实验结果仍然基于模拟环境,实际市场中的情况可能会有所不同。未来的研究应该着重解决实际市场中的挑战,并进一步提高模型的性能和可靠性。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111058
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!