
一 本文概要
股票价格预测是一项基础但具有挑战性的任务,在量化投资中至关重要。为了捕捉股票数据中复杂的指标、时间和股票之间的关联,许多研究人员已经开发了各种神经网络模型(如RNN、GNN和Transformers)。尽管这些复杂的模型具有很强的表达能力,但它们往往很难进行优化,并且由于股票数据有限,它们的性能通常受到限制。
本文提出了一种简单的基于MLP(多层感知机)的架构,名为StockMixer。StockMixer的优势在于它易于优化,并且具有强大的预测性能。StockMixer的预测过程分为指标混合、时间混合和股票混合三个步骤。与传统的基于MLP的混合方法不同,StockMixer设计了一种特殊的时间混合方法,用于交换多个时间尺度上的信息,并且明确利用股票对市场和市场对股票的影响进行股票混合。通过在真实股票数据上进行实验证明StockMixer在股票价格预测方面表现优异,超过了许多最先进的方法。
二 背景知识
2.1 股票价格预测
股票价格预测的目标是根据过去的股票价格和相关指标,预测未来的价格走势。这可以帮助投资者做出更明智的投资决策,例如买入或卖出股票,或者确定最佳的交易时机。在进行股票价格预测时,常用的方法包括基于统计学的方法和基于机器学习的方法。基于统计学的方法通常依赖于历史数据的趋势和模式,如移动平均线、趋势线和技术指标等。这些方法假设过去的价格模式会在未来重复出现,并根据这些模式进行预测。
另一方面,基于机器学习的方法利用算法和模型来自动学习历史数据中的模式和关联性,并通过这些学习来预测未来的股票价格。这些方法可以使用各种机器学习算法,如线性回归、支持向量机、决策树、随机森林、神经网络等。这些算法通过对历史数据进行训练,学习股票价格与其他因素之间的关系,并用于预测未来的价格变动。随着深度神经网络的发展,一些研究开始使用循环神经网络或卷积神经网络来预测单个股票的短期趋势。为了处理更细微的市场信号,一些研究尝试了自注意机制、对抗训练和门控因果卷积等技术。后来的研究考虑了股票之间的关系,并在预测中取得了最先进的性能。
2.2 MLP架构
MLP(多层感知机)是一种基本的人工神经网络架构。它由多个全连接的神经元层组成,每个神经元都与前一层的所有神经元相连。最近研究人员重新关注了MLP在计算机视觉领域的应用。MLP-Mixer是一种简单的架构,通过操作数据的子序列来增强MLP的学习能力,与CNN和Transformer实现了相似的性能。在时间序列领域,一些研究证实了MLP在预测任务中的可行性,并利用MLP-Mixer的思想进一步提高了时间序列预测的性能。然而,由于股票数据的特殊性,包括缺乏周期性和动态变化的相关性,基于MLP的方法在股票数据集上的表现不如基本模型。
三 本文工作
3.1 问题定义
股票价格预测问题通常使用归一化的股票历史模式作为输入,这些模式包括多个指标(例如开盘价、收盘价或5日平均收盘价),并预测下一天的收盘价,以计算1日回报率。假设有一个包含N个股票的股票市场数据,用X = {X1,X2,…,XN}表示。每个股票Xi ∈ R。T × F包含了过去T个时间步长的历史数据,其中F表示每个时间步长的指标维度。我们的任务是预测交易日t的收盘价pti,并计算1日回报率rti = (pti−pt−1i)/pt−1i。我们用θ表示模型的参数。整个过程可以表示为: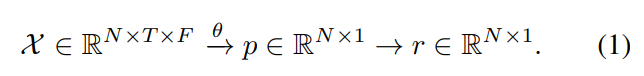

3.2 标准的MLP Mixer
MLP Mixer首先被提出作为一种轻量级的图像分类方法,主要使用线性层在令牌或特征通道中进行重复操作,并结合残差连接、数据尺度转换和适当的激活函数。除了大大提高计算速度外,这种方法在不同维度之间交换信息的能力也非常重要。这种能力使得模型可以更好地处理股票市场中的指标、时间和股票之间的关系,提高模型的表达能力。残差连接保持了输入与混合特征之间的平衡,而层归一化则在一定程度上消除了数据偏移的影响。
对于每个原始表示x,我们使用在特定维度上混合特征的方法来计算新的嵌入表示y。具体计算公式如下: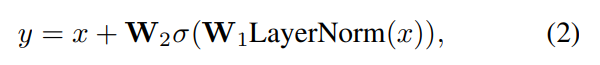
其中,x是输入特征,y是块的输出结果。W1和W2是可训练的全连接层的权重, 而h是一个可调节的隐藏维度,始终与特定维度a相等。。σ表示非线性激活函数,它对预测性能有重要影响。视觉模型通常选择GeLU作为激活函数。然而,通过实验我们发现在处理时间数据时ReLU和HardSwish能够实现更好的性能表现, MLPMixer中采用了ReLU和HardSwish作为激活函数。
3.3 StockMixer方法
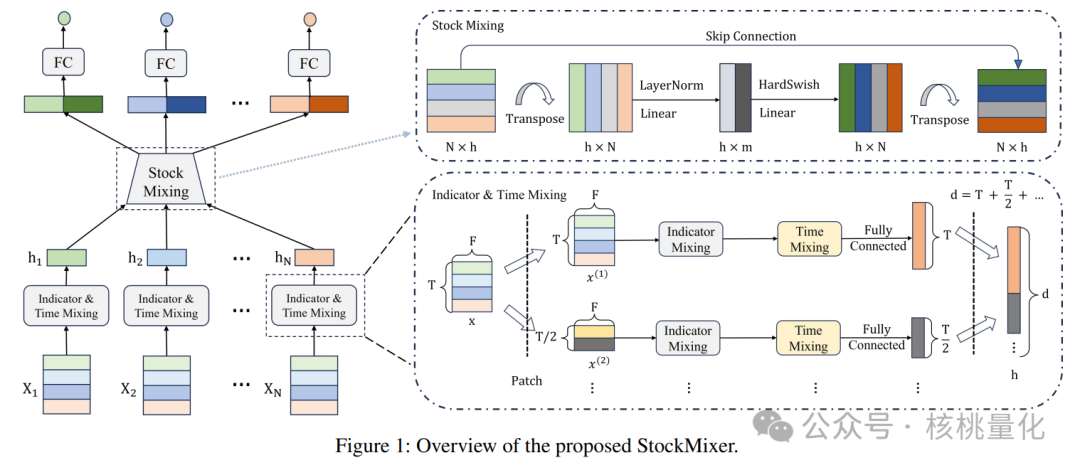 图展示了StockMixer的总体架构,主要包括两个部分:指标与时间的混合和股票的混合。指标与时间的混合部分用于提取每只股票的相应表示,相当于一个高效的编码器。这一部分的目的是将金融指标和时间信息结合起来,以捕捉股票之间的复杂关联。最终,我们将这些表示组合起来,用于预测交易日的收盘价。为了保持数据维度的一致性,我们按照指标混合、时间混合和股票混合的顺序进行模块设计,从而得到了StockMixer。
图展示了StockMixer的总体架构,主要包括两个部分:指标与时间的混合和股票的混合。指标与时间的混合部分用于提取每只股票的相应表示,相当于一个高效的编码器。这一部分的目的是将金融指标和时间信息结合起来,以捕捉股票之间的复杂关联。最终,我们将这些表示组合起来,用于预测交易日的收盘价。为了保持数据维度的一致性,我们按照指标混合、时间混合和股票混合的顺序进行模块设计,从而得到了StockMixer。
指标混合
以前的研究将金融指标的序列输入到递归神经网络中,但是忽略了指标之间的相关性。事实上,不同的指标之间可能存在一些关联关系。例如,同一天内股票的开盘价和收盘价之间的差异可能暗示着该股票未来的趋势。因此,在计算时间表示之前,我们需要在每个时间步骤中交换指标之间的信息,以更好地捕捉这些关联关系。
为了实现指标之间的混合,我们采用了一种叫做指标混合的方法。它与标准的多层感知机(MLP)混合方法相一致。对于每只股票,我们将其时间和指标进行转置,然后在指标的维度上进行特征混合。通过一个公式计算指标混合的结果,并将其作为下一步时间混合的输入。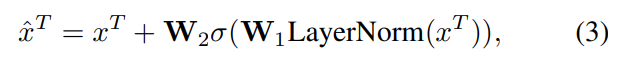 通过这种指标混合的方式,我们能够更好地利用历史股票价格作为预测未来趋势的重要指标,并且考虑到不同指标之间的相关性。这样可以提高模型的表达能力和预测准确度,从而更好地帮助我们进行股票预测。
通过这种指标混合的方式,我们能够更好地利用历史股票价格作为预测未来趋势的重要指标,并且考虑到不同指标之间的相关性。这样可以提高模型的表达能力和预测准确度,从而更好地帮助我们进行股票预测。
时间混合
时间混合是指在处理时间序列数据时,我们需要考虑时间的顺序和关联性。与计算机视觉中对图像进行子序列混合的方式不同,时间序列数据中的信息交换更依赖于时间的先后顺序。我们提出了一种结构修改的方法,类似于自注意力掩码,用于在混合过程中限制信息的传递。具体来说,我们使用上三角矩阵来控制信息的流动,确保较晚的时间步不会影响到较早的时间步,这更符合时间数据的特点。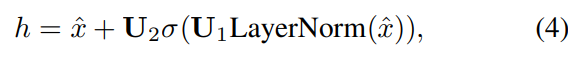
其中x表示指标混合的表示,U1,U2分别表示第一和第二个全连接层的可学习权重,只有矩阵的上三角部分可训练,以实现掩码效果。Ht表示时间的隐藏维度,这里我们设置Ht = T。
为了处理时间序列数据中的不同尺度和特征,我们采用了子序列分割和混合的方法。我们将原始时间序列分成多个子序列级别的子序列,并在不同尺度上对特征进行混合。然后,我们通过指标混合和时间混合来融合每个子序列中的特征。为了保持维度的一致性,我们对每个子序列内的时间步进行汇总,得到一个整体的表示。最后,我们通过连接操作和全连接层来聚合所有子序列的表示,得到最终的时间表示。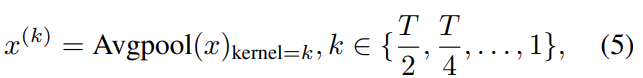
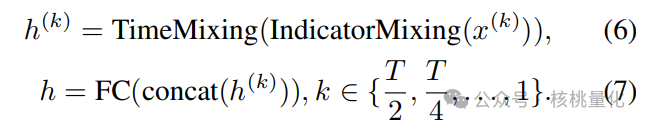 这种时间混合的方法能够在有限的时间序列数据上获取多层次、丰富多样的特征表示,并提高模型在未知数据上的泛化能力。相比于传统的线性模型,我们能够更好地利用短期模式,并减少对周期性数据的依赖。通过结合不同尺度的信息,我们能够更全面地理解和预测时间序列数据中的模式和趋势。
这种时间混合的方法能够在有限的时间序列数据上获取多层次、丰富多样的特征表示,并提高模型在未知数据上的泛化能力。相比于传统的线性模型,我们能够更好地利用短期模式,并减少对周期性数据的依赖。通过结合不同尺度的信息,我们能够更全面地理解和预测时间序列数据中的模式和趋势。
股票混合
股票混合是一种方法,用于构建股票之间的关系,而无需事先了解知识图谱或行业信息。我们使用MLP-Mixer模型的强大信息交换能力来捕捉关系。通过将股票的隐藏维度设置为N,我们可以将市场特征聚合为N个股票,并相互影响。这类似于在一个完全连接的图中进行消息传递,其中任意两个股票之间都有一条边。然而,由于股票数据集较小,缺乏可迁移性和稳健性,容易导致过拟合问题。
为了解决这个问题,我们希望保留最重要和有用的市场状态,以提高模型的性能和可解释性。对于每支股票,我们不需要考虑所有其他股票的信息,而是将股票之间的信息交换过程分解为股票到市场和市场到股票的过程,类似于超图。为了实现这一点,我们引入了一个超参数m,将与股票相关的隐藏维度替换为m,以实现可自学习的超图效果。这个过程可以看作是将股票信息聚合到市场上,然后计算市场对每个股票的影响。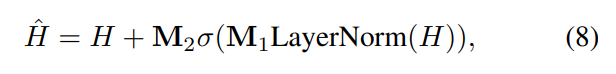 最后,我们将股票的自身表示与市场影响的表示进行连接,并通过一个全连接层进行维度缩减,得到最终的预测结果。通过这种方式,我们能够有效地捕捉到股票之间的关系,并提高模型在预测股票走势方面的表现和可解释性。
最后,我们将股票的自身表示与市场影响的表示进行连接,并通过一个全连接层进行维度缩减,得到最终的预测结果。通过这种方式,我们能够有效地捕捉到股票之间的关系,并提高模型在预测股票走势方面的表现和可解释性。
损失函数
损失函数是用来衡量我们的预测结果与实际结果之间的差异的一种函数。在这个问题中,我们使用股票的1日回报率作为真实值,而不是之前的研究中使用的归一化价格。我们的目标是通过最小化预测回报率和实际回报率之间的均方误差(MSE)来准确预测股票的回报率,并且要保持那些预期回报率更高的股票在排序中靠前的相对顺序。为了实现这个目标,我们使用了一种结合了点对回归和排序感知损失的方法。 损失函数由两部分组成。第一部分是均方误差(LMSE),用来衡量预测回报率与实际回报率之间的差异。我们希望通过最小化这个差异来使预测结果更接近真实情况。第二部分是排序感知损失,用来保持预期回报率更高的股票在排序中靠前的相对顺序。这部分损失函数的计算方式是对每对股票进行比较,并根据它们的预测排名分数和实际排名分数来确定损失的大小。如果排名顺序不正确,损失会增加,以鼓励模型学习正确的排序关系。在整个损失函数中,我们还引入了一个权重参数α,用来平衡均方误差和排序关系的重要性。通过调整这个参数,我们可以根据具体情况来决定哪个方面更重要。
损失函数由两部分组成。第一部分是均方误差(LMSE),用来衡量预测回报率与实际回报率之间的差异。我们希望通过最小化这个差异来使预测结果更接近真实情况。第二部分是排序感知损失,用来保持预期回报率更高的股票在排序中靠前的相对顺序。这部分损失函数的计算方式是对每对股票进行比较,并根据它们的预测排名分数和实际排名分数来确定损失的大小。如果排名顺序不正确,损失会增加,以鼓励模型学习正确的排序关系。在整个损失函数中,我们还引入了一个权重参数α,用来平衡均方误差和排序关系的重要性。通过调整这个参数,我们可以根据具体情况来决定哪个方面更重要。
总的来说, 这样的损失函数旨在使模型能够准确预测股票的回报率,并确保在投资时将预期回报率更高的股票排在前面。
四 实验分析
4.1 实验数据集
实验使用了使用了来自美国股市的三个真实数据集, 其中两个数据集分别是来自NASDAQ和NYSE的交易记录,时间跨度从2013年1月2日到2017年12月8日。这些数据集经过了筛选,去除了异常模式和低价股,以保持数据的代表性。NASDAQ数据集的特点是波动性较高,而NYSE数据集则相对更稳定。第三个数据集是基于S&P 500指数的,从Yahoo Finance数据库中获取了该指数的历史价格数据和行业信息。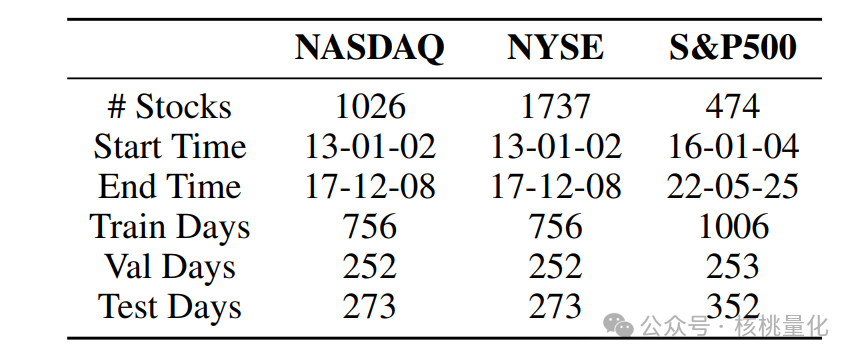
4.2 评估指标
为了评估模型的性能,我们采用了四个常用的指标。其中包括信息系数(IC)和排名信息系数(RIC),它们衡量了预测结果与实际结果的接近程度。我们还使用了Precision@N指标来评估模型在前N个预测中的准确性。最后,我们使用夏普比率(SR)来综合考虑回报率和风险,以评估模型的整体表现。
4.3 整体结果
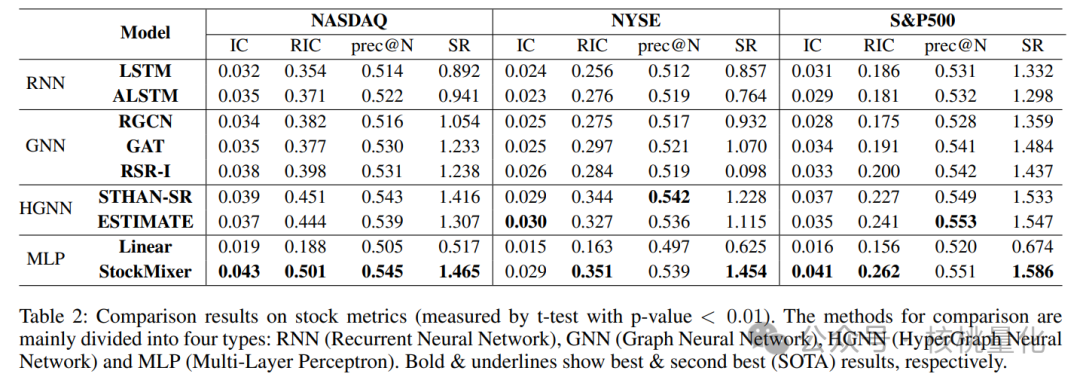
表2展示了各种比较方法的性能,并指出了以下关键观察结果:首先,对于单变量方法,无论是LSTM还是改进的ALSTM,在与其他混合架构相比时表现较差,这证明了股票市场中关系的重要性。其次,超图架构能够更好地建模复杂的股票间依赖关系,而传统图结构主要关注任意两个实体之间的相关性。然而,真实股价的变化并不仅仅依赖于几个强相关的公司,更取决于市场的整体属性。此外,简单的线性模型在股票时间序列建模方面缺乏有效的归纳偏好,而其他基于MLP的时间序列方法在不考虑股票特征的情况下表现更差。最后,我们提出的StockMixer在轻量级的MLP模型基础上融合了混合网络的优点,取得了最佳结果,并在大多数指标上相对于其他方法有显著的性能提升。此外,StockMixer的设计简单但强大,参数数量仅次于RNN,并且计算时间比图传递方法更短。然而,在处理较大的候选股票池时,可能会逐渐出现性能下降的情况,这表明缺乏足够的归纳偏好。
4.4 消融实验
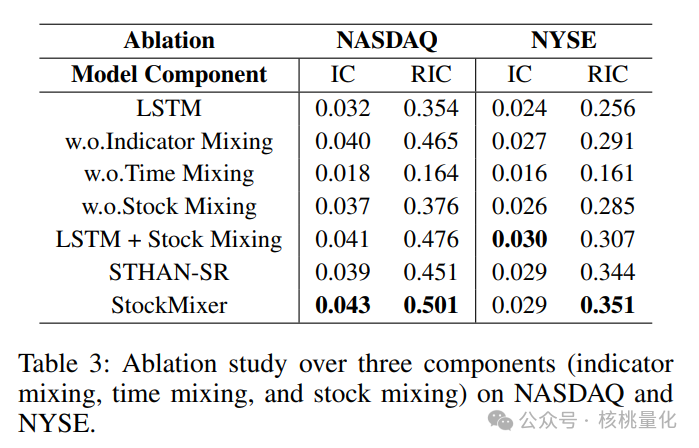 我们的研究主要关注模型组件和超参数对股票预测性能的影响。我们通过实验来验证三个混合块的效果,并与两个典型的基准模型进行比较。我们还用我们的股票混合方法替换了先前的市场模块,并在纳斯达克和纽约证券交易所进行了实验。实验结果表明,不同的组件对模型性能产生共同影响。其中,时间维度的混合对性能影响最大。如果只学习孤立的表示,就很难建模有意义的关系。这也解释了为什么我们的模型和先前的架构都采用了时间优先于空间的方法。我们还发现,将指标特征混合到股票运动中对于预测性能非常重要。没有融入指标特征的模型性能稍差。另外,我们发现基于MLP的编码器可以作为RNN的可靠替代品,对LSTM模型性能有较大提升。
我们的研究主要关注模型组件和超参数对股票预测性能的影响。我们通过实验来验证三个混合块的效果,并与两个典型的基准模型进行比较。我们还用我们的股票混合方法替换了先前的市场模块,并在纳斯达克和纽约证券交易所进行了实验。实验结果表明,不同的组件对模型性能产生共同影响。其中,时间维度的混合对性能影响最大。如果只学习孤立的表示,就很难建模有意义的关系。这也解释了为什么我们的模型和先前的架构都采用了时间优先于空间的方法。我们还发现,将指标特征混合到股票运动中对于预测性能非常重要。没有融入指标特征的模型性能稍差。另外,我们发现基于MLP的编码器可以作为RNN的可靠替代品,对LSTM模型性能有较大提升。
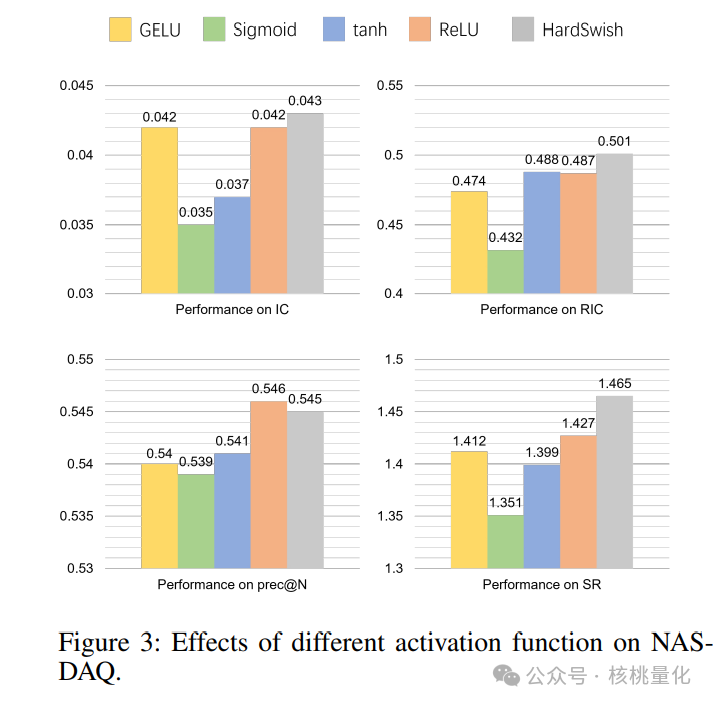 上图展示的实验研究了不同激活函数的影响。在股票预测任务中,Sigmoid和tanh表现一般,而ReLU和HardSwish明显改善了模型性能。
上图展示的实验研究了不同激活函数的影响。在股票预测任务中,Sigmoid和tanh表现一般,而ReLU和HardSwish明显改善了模型性能。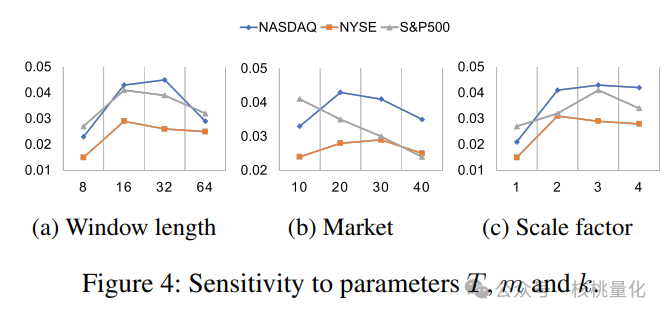 关于超参数的敏感性研究显示,适度的回溯窗口长度能获得最佳性能。过短的窗口长度信息不足,而过长的窗口长度则会导致学习成本增加。在股票混合中,不同的市场维度对于不同的数据集有不同的最佳取值。市场容量较大的数据集更适合较大的维度,因为更多的股票带来了更复杂的市场表示。最后,我们发现多尺度因子对于模型性能的提升有一定的影响,其中k = 3时获得了最佳结果。
关于超参数的敏感性研究显示,适度的回溯窗口长度能获得最佳性能。过短的窗口长度信息不足,而过长的窗口长度则会导致学习成本增加。在股票混合中,不同的市场维度对于不同的数据集有不同的最佳取值。市场容量较大的数据集更适合较大的维度,因为更多的股票带来了更复杂的市场表示。最后,我们发现多尺度因子对于模型性能的提升有一定的影响,其中k = 3时获得了最佳结果。
五 总结展望
本文提出了一种名为StockMixer的股票预测架构,通过增强MLP块实现了简单而强大的模型。StockMixer采用了指标、时间和股票混合块的轻量级组合,其中时间混合考虑了更多尺度,提供了更好的时间编码器,而股票混合则更强大地建模了股票相关性。通过大量实验,我们发现StockMixer在各项评估指标上的性能优于当前流行的基准模型,平均相对性能提升为7.6%、10.8%和10.9%。未来可以将StockMixer应用于更多的股票市场,以验证其在不同市场中的泛化能力。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111057
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!