
昨天有星球群里,有朋友问起我们这个回测平台都包含了谁,我想应该好好说下整理一下这个逻辑了。
开源的回测系统很多,而且有些还很成熟,比如backtrader,有些有大公司加持,比如qlib。
为何我们还需要自己重新造轮子呢?——因为我们做AI量化。


如果说要demo一个引擎特别简单:向量化只需要几行代码,按bar特征也不复杂。但要完善,贴近实盘,还是需要细致的工作。
对于系统我自己有几点要求:
1、使用pandas dataframe:pybroker, bt,排除backtrader,pyalgotrade,这两个框架都是自定义的数据结构,可能与项目历史有关吧,调试起来麻烦。
2、传统量化:qlib不支持,qlib的传统量化特别弱,这一点不太好。毕竟我们做量化,不能不用机器学习就执行不了吧。——我学了它的表达式引擎,这个特别好,但我没有用它的数据存储,我引入了duckdbDuckdb,很适合AI量化的一个基于本地文件系统的的olap分析引擎(代码下载)。
3、支持“大规模”因子:这个是刚需,传统的量化框架,把指标计算给实现了,这其实把简单问题复杂化了。AI量化可能成百上千的因子,必要使用表达式,这个只有qlib支持,以及我下面要说的bt。
4、模块化:消除策略的模板代码,这个基础回测引擎包装挺容易。”积木式”模块化的思路就是来自bt。http://pmorissette.github.io/bt/
bt一共只有三个文件:
from engine.datafeed.dataloader import Duckdbloader import pandas as pd symbols = ['000001.SZ', '000002.SZ'] loader = Duckdbloader(symbols=None, columns=['close', 'open', 'volume'], start_date="20100101") fields = ["-1 * correlation(open, volume, 10)"] fields = ['std(close, 10)/close'] #fields = ['(corr(close/shift(close,1), log(volume/shift(volume, 1)+1), 30))'] factor_name = '量价背离_10' names = [factor_name] df = loader.load(fields=fields, names=names) df.dropna(inplace=True) print(df) #df_close.reindex(df_close.index, method='ffill') # df = pd.DataFrame() df_close = df.pivot_table(columns='symbol', values='close', index='date') #df_close = pd.DataFrame() #df_close.reindex(index=df_close.index, method='ffill') df_close.fillna(method='ffill', inplace=True) df_close.fillna(method='bfill', inplace=True) print(df_close) df_close.dropna(inplace=True) import bt # algo to fire on the beginning of every month and to run on the first date runMonthlyAlgo = bt.algos.RunMonthly( run_on_first_date=True, run_on_end_of_period=True ) factor = df[['symbol',factor_name]] class SelectTopK(bt.Algo): def __init__(self, factor: pd.DataFrame, K=1, drop_top_n=0,b_ascending=False): self.K = K self.drop_top_n = drop_top_n # 这算是一个魔改,就是把最强的N个弃掉,尤其动量指标,过尤不及。 self.factor = factor self.b_ascending = b_ascending def __call__(self, target): selected = None key = 'selected' #print(target.now) factor = self.factor.loc[target.now] factor.set_index('symbol', inplace=True) #factor = factor[factor['']] factor_sorted = factor.sort_values(by=factor_name, ascending=self.b_ascending) symbols = factor_sorted.index ture_symbols = [] for s in symbols: price = target.universe.loc[target.now][s] if price < 0: continue ture_symbols.append(s) #bar_df = bar_df.sort_values(self.order_by, ascending=self.b_ascending) if not selected: start = 0 if self.drop_top_n <= len(ture_symbols): start = self.drop_top_n ordered = ture_symbols[start: start + self.K] else: ordered = [] else: ordered = [] count = 0 for s in ture_symbols: # 一定是当天有记录的 if s in selected: count += 1 if count > self.drop_top_n: ordered.append(s) if len(ordered) >= self.K: break target.temp[key] = ordered return True # algo to set the weights in the temp dictionary\ # weights = pd.Series([0.6, 0.4], index=df.columns) # weighSpecifiedAlgo = bt.algos.WeighSpecified(**weights) weight_equally = bt.algos.WeighEqually() # algo to rebalance the current weights to weights set in temp dictionary rebalAlgo = bt.algos.Rebalance() # a strategy that rebalances monthly to specified weights s = 'monthly' strat = bt.Strategy(s, [ #runMonthlyAlgo, #bt.algos.SelectAll(), SelectTopK(factor=factor, K=10), weight_equally, rebalAlgo ] ) """ runMonthlyAlgo will return True on the last day of the month. If runMonthlyAlgo returns True, then weighSpecifiedAlgo will set the weights and return True. If weighSpecifiedAlgo returns True, then rebalAlgo will rebalance the portfolio to match the target weights. """ # set integer_positions=False when positions are not required to be integers(round numbers) backtest = bt.Backtest( strat, df_close, integer_positions=False, progress_bar=True ) res = bt.run(backtest) res.display() df = res.get_transactions() print(df) df.to_csv('trans.csv') res.plot() import matplotlib.pyplot as plt plt.show()
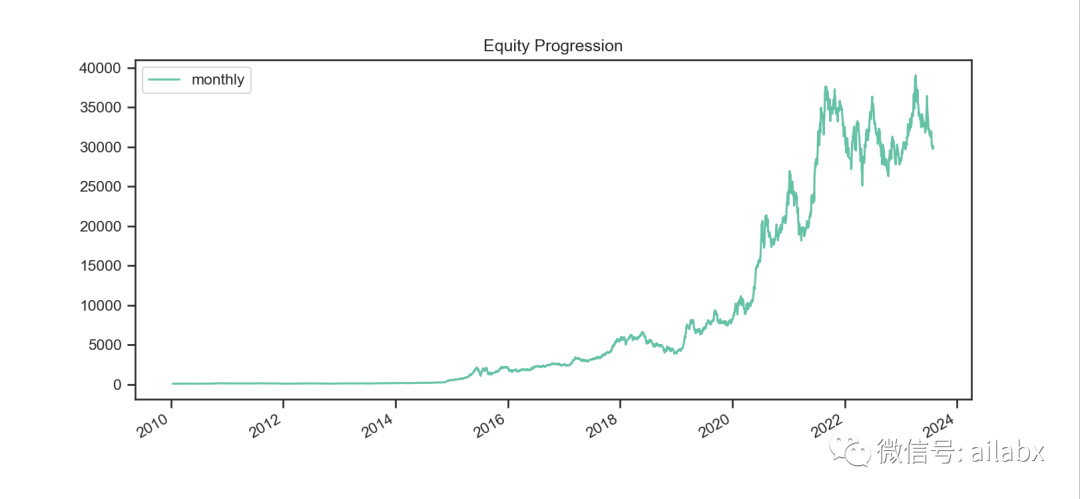
我们还是使用alphalens来分析一下单因子的收益率:
我们做一下波动率的单因子分析:
factor_expr = ‘std(close, 10)/close’
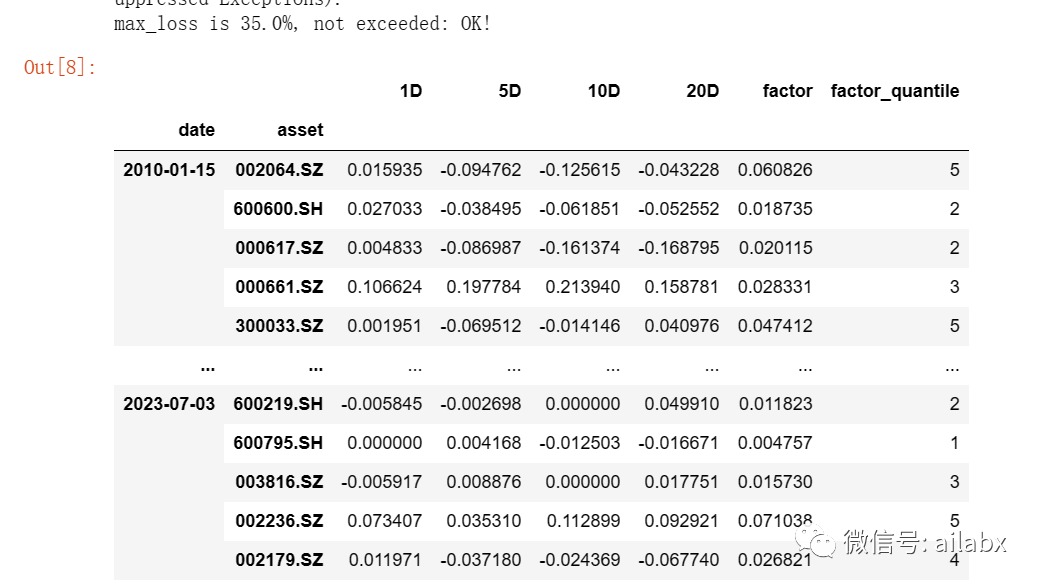
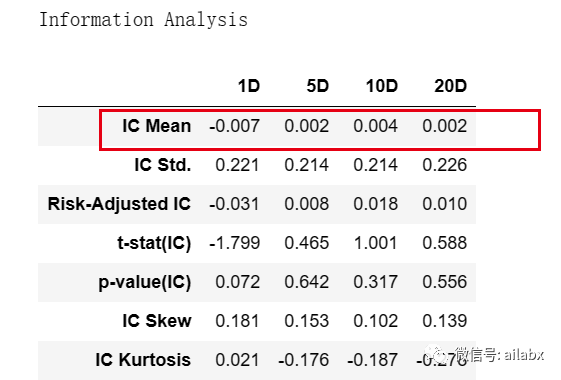
收益分析结果:
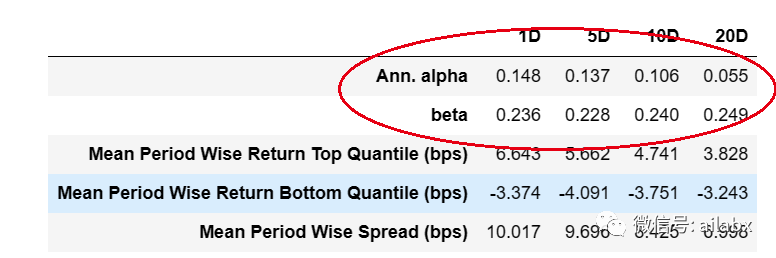
但IC值一般:
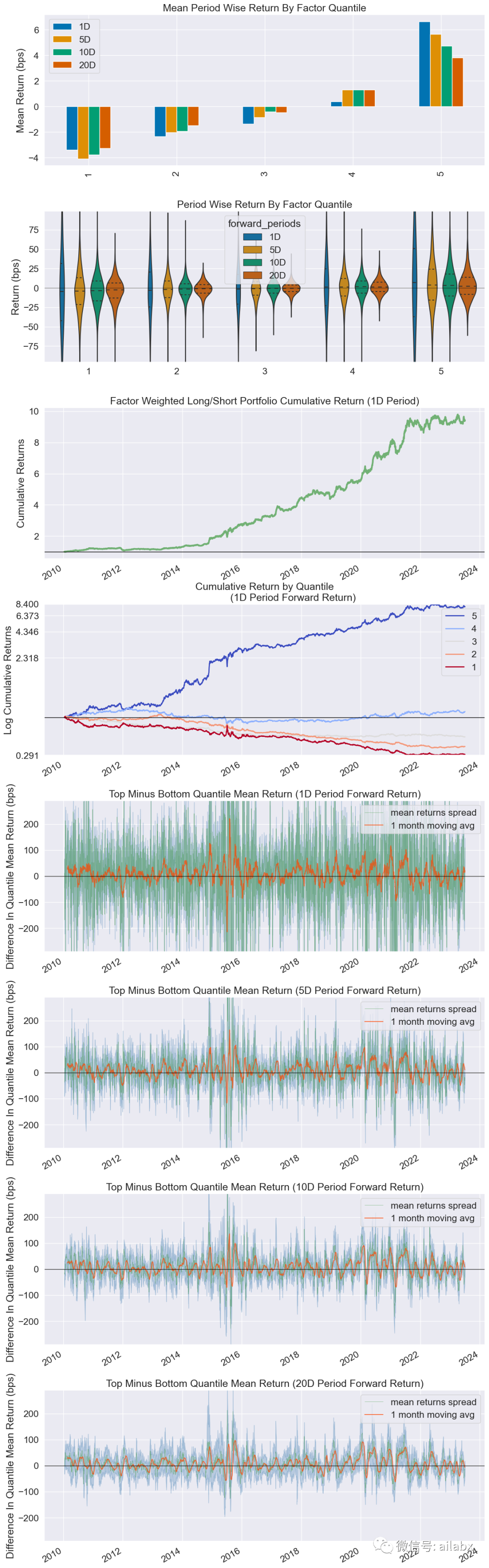
我们看一下收益分析里的代码:
使用OLS”普通最小二乘法”,y = aX+b,计算alpha/beta。
alpha_beta = pd.DataFrame() for period in returns.columns.values: x = universe_ret[period].values y = returns[period].values x = add_constant(x) reg_fit = OLS(y, x).fit() try: alpha, beta = reg_fit.params except ValueError: alpha_beta.loc['Ann. alpha', period] = np.nan alpha_beta.loc['beta', period] = np.nan else: freq_adjust = pd.Timedelta('252Days') / pd.Timedelta(period) alpha_beta.loc['Ann. alpha', period] = \ (1 + alpha) ** freq_adjust - 1 alpha_beta.loc['beta', period] = beta return alpha_beta
尽管对于单因子分析,大家都在讨论IC/IR,
我目前实证的结果是,IC大的,Alpha可能小;而Alpha大,IC可能不明显的,但回测结果更优。
大家可以试试。IC值我在代码里都排好序了。
因子评估,传统的IC/IR分析:qlib因子分析之alphalens源码解读
更具挑战的事情是,传统的方法依靠的是线性关系,这个被挖掘得很充分了。机器学习能不能找到高维的非线性的关系,这个存疑。另外就是找“另类数据“。
当然战略就找重要的,且可解决的。利用自己的信息优势,资源优势,整合方案优势等等,这才是一个好战略。
前面花了不少笔墨解决gui的问题,似乎并不是一个好战略。
粉丝重要的诉求是策略,可以指导交易的策略,是赚钱。

90万条历史记录秒出:


改造后的dataloader,我去除了CsvLoader和HdfLoader,后面统一使用DuckdbLoader,这个大家注意一下,性能要好很多。
import pandas as pd import os from datetime import datetime from loguru import logger import duckdb from tqdm import tqdm import abc from engine.config import CSVS_DIR from engine.datafeed.expr import calc_expr class Dataloader: def __init__(self, path, symbols, start_date='20100101', end_date=datetime.now().strftime('%Y%m%d')): self.symbols = symbols self.path = path self.start_date = start_date if not end_date or end_date == '': end_date = datetime.now().strftime('%Y%m%d') self.end_date = end_date @abc.abstractmethod def _load_df(self): pass def _reset_index(self, df: pd.DataFrame): trade_calendar = list(set(df.index)) trade_calendar.sort() def _ffill_df(sub_df: pd.DataFrame): df_new = sub_df.reindex(trade_calendar, method='ffill') return df_new df = df.groupby('symbol',group_keys=False).apply(lambda sub_df: _ffill_df(sub_df)) return df def load(self, fields=None, names=None): df = self._load_df() df = self._reset_index(df) if not fields or not names or len(fields) != len(names): return df else: df.set_index(['symbol', df.index], inplace=True) #print(df) for field, name in tqdm(zip(fields, names)): df[name] = calc_expr(df, field) df.reset_index(level='symbol', inplace=True) df.sort_index(inplace=True) return df class Duckdbloader(Dataloader): def __init__(self, symbols, columns, start_date='20100101', end_date=datetime.now().strftime('%Y%m%d')): super().__init__(None, symbols, start_date, end_date) self.columns = columns self.columns.extend(['symbol','date']) def _load_df(self): if self.columns: cols_str = ','.join(self.columns) #cols_str += ',' + "CAST('date' AS VARCHAR)" symbols_str = None if self.symbols and len(self.symbols): symbols = ["'{}'".format(s) for s in self.symbols] symbols_str = ",".join(symbols) query_str = """ select {} from '{}/*/*.csv' where date >= '{}' and date <= '{}' """.format(cols_str, CSVS_DIR.resolve(), self.start_date, self.end_date) if symbols_str: query_str += ' and symbol IN ({})'.format(symbols_str) df = duckdb.query( query_str ).df() df.set_index('date', inplace=True) return df if __name__ == '__main__': from engine.datafeed.dataloader import Duckdbloader loader = Duckdbloader(symbols=['000001.SZ', '000002.SZ'], columns=['close', 'open', 'volume'], start_date="20100101") fields = ["-1 * correlation(open, volume, 10)"] names = ["量价背离_10"] df = loader.load(fields=fields, names=names) df.dropna(inplace=True) print(df)
直接pip install alphalens即可。
我们找一个因子:alpha101里第6个因子,比较简单但有效:
-1 * correlation(open, volume, 10):这个因子的逻辑是”价量背离“。
近10天的开盘价与成交量呈现”负“的相关关系。

整理成alphalens需要的格式:使用pandas dataframe的pivot_table:



从IC/IR来看,10天/20的”预测效果“还行:


后续所有的因子列表,可能按IC/IR来排序,然后组合成一个新的有效因子!
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103970
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!