
一. 本文简介
时序交叉验证方法适用于时间序列数据,可以有效防止过拟合。与传统交叉验证方法相比,时序交叉验证考虑了时间序列数据的特性,可以更好地评估模型在未来数据上的性能。传统交叉验证在处理时间序列数据时可能会出现未来信息预测历史的”作弊”行为,而时序交叉验证可以避免这种问题,能够有效防止过拟合并获得更高且更稳定的收益。因此,推荐在选择机器学习模型超参数时使用时序交叉验证方法。此外,时序交叉验证的思想还可以应用于其他量化策略的参数寻优,提升策略的稳定性并避免过拟合的发生。
二. 背景知识
2.1 过拟合
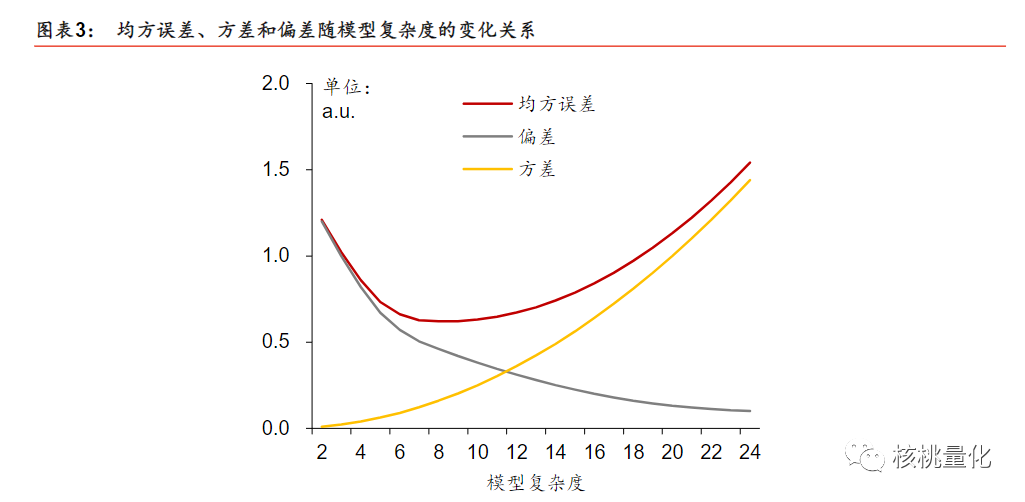
过拟合(overfitting)是指机器学习模型在训练数据上表现出较好的性能,但在未见过的测试数据上表现较差的现象。当模型过于复杂或过度拟合训练数据时,它会捕捉到数据中的噪声和细节,导致在新数据上的泛化能力下降。过拟合通常是由于模型过于复杂或训练数据不足引起的。以下是一些常见的过拟合情况和原因:
-
模型复杂度过高:当模型具有过多的参数或复杂的结构时,它可能过度拟合训练数据,将训练数据中的噪声也当作特征进行学习。 -
数据不足:如果训练数据量太小,模型可能无法从有限的样本中学到足够的特征和模式,从而过拟合训练数据。 -
特征选择不当:选择了过多的特征或不相关的特征,这些特征可能会干扰模型的学习过程,导致过拟合。 -
过度训练:训练数据集上进行过多的迭代或训练过程过长,模型可能开始记住训练样本的细节而不是学习一般化的模式。
2.2 交叉验证
交叉验证是一种常用的模型评价方法,可以用于检测和缓解过拟合问题。交叉验证通过将数据集划分为训练集和验证集,并多次重复训练和验证过程,可以对模型的泛化性能进行评估。下面介绍几种常见的交叉验证方法及其与过拟合问题的关系:
-
简单交叉验证(Holdout Cross-Validation):将数据集划分为训练集和验证集,通常按照一定比例划分(如70%训练集和30%验证集)。然后使用训练集训练模型,在验证集上评估模型性能。简单交叉验证可以帮助检测过拟合问题,但验证集的选择可能会对结果产生较大影响。 -
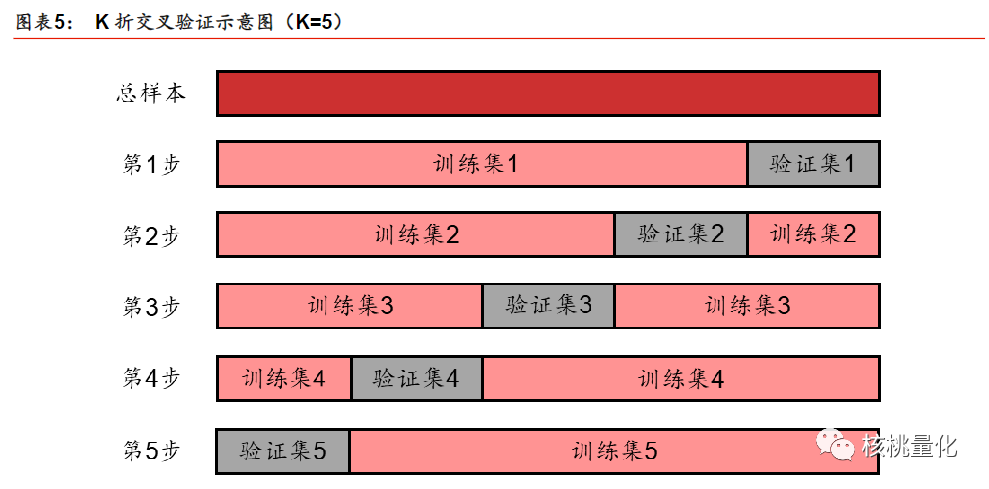
K折交叉验证(K-Fold Cross-Validation):将数据集划分为K个大小相等的子集,其中K-1个子集用作训练集,剩余的1个子集用作验证集,然后重复K次,每次选择不同的验证集。最终,对K次验证的结果进行平均得到模型性能的估计。K折交叉验证可以更稳定地评估模型的性能,减少验证集选择的偶然性,从而更好地检测和缓解过拟合问题。
-
留一法交叉验证(Leave-One-Out Cross-Validation):将每个样本单独作为验证集,其他样本作为训练集,然后重复这个过程。留一法交叉验证适用于数据集较小的情况,但计算开销较大。它能够更准确地评估模型性能,但在训练集和验证集之间存在较高的相关性,可能无法充分检测到过拟合问题。
这些交叉验证方法都可以在一定程度上帮助检测和缓解过拟合问题。通过在训练过程中使用不同的训练集和验证集组合,交叉验证可以提供对模型在未见数据上的性能估计,帮助选择合适的模型和超参数配置,从而减少过拟合的风险。此外,还可以使用正则化技术、特征选择等方法来进一步防止过拟合问题的发生。
三. 时序交叉验证
传统的交叉验证方法假设样本是独立同分布的,也就是说样本之间没有相关性,并且所有样本都来自同一分布。然而,当样本是时间序列数据时,数据随时间的演进可能包含周期性、过去和未来数据之间的相互关系等信息,不符合传统交叉验证的基本假设。在时间序列数据中使用传统交叉验证方法可能导致将未来时刻的数据用于训练集,将历史时刻的数据用于验证集,这会导致模型在验证集上表现良好,但在实际应用中预测历史结果时可能出现错误。换句话说,模型使用了未来的信息来预测过去的结果,这种行为类似于”作弊”。
为了解决这个问题,需要一种既能充分利用数据又能保留时序数据之间相互关系的交叉验证方法,这就是时序交叉验证方法。时序交叉验证将时间序列数据按照一定的时间跨度划分为多个部分,然后依次将每个部分作为验证集,其他部分作为训练集进行模型训练和评估。通过多次验证并取平均值,可以得到对模型性能的综合评估。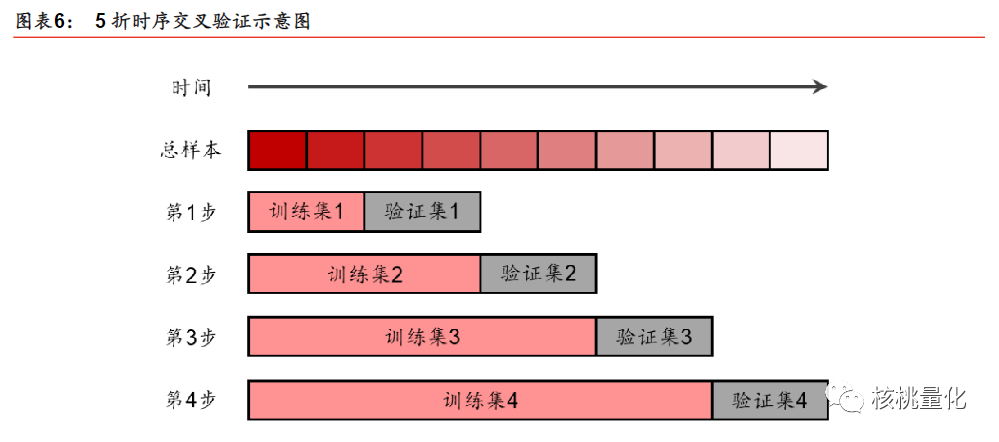
以上图中的5折时序交叉验证为例,假设样本的时间跨度为10个月,首先将样本等分为5个部分。然后,依次将每个部分作为验证集,其他部分作为训练集,进行模型验证和评估。通过这种方式,可以避免使用未来信息,并且保留了时序数据中的相互关系。时序交叉验证方法在时间序列数据的机器学习中是一个较为合理的选择,它可以防止未来信息的利用,对模型的评估更加准确。
四. 将时序交叉验证用于选股
4.1 算法训练
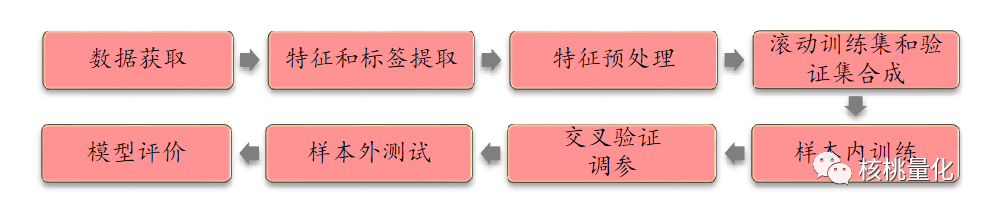
本文选用逻辑回归和XGBoost 作为基学习器,两者分别作为简单模型和复杂模型的代表。测试流程包含如下步骤:
-
数据获取:选择全A股作为股票池,剔除ST股票、停牌股票和上市不足3个月的股票。设定回测区间为2011年1月31日至2018年9月28日。 -
特征和标签提取:每个自然月的最后一个交易日,计算70个因子的暴露度作为样本的原始特征。下个自然月个股的超额收益作为标签,排名前30%的股票标记为正例(y=1),后30%的股票标记为负例(y=-1)。 -
特征预处理:使用中位数去极值方法处理因子暴露度序列,将超过中位数加五倍中位数绝对值的值设定为该边界值,将低于中位数减五倍中位数绝对值的值设定为该边界值。处理缺失值,将因子暴露度缺失的位置设定为同一行业其他股票的平均值。进行行业市值中性化处理,通过线性回归计算因子暴露度与行业哑变量和对数市值的残差作为新的因子暴露度。标准化因子暴露度序列,减去均值并除以标准差,得到近似服从N(0, 1)分布的序列。 -
滚动训练集和验证集的合成:为了减少时间开销,采用年度滚动训练方式,将样本数据分为八个阶段。例如,预测2011年时,将2005-2010年的数据作为样本内数据集。根据不同的交叉验证方法(K折或时序),划分训练集和验证集。
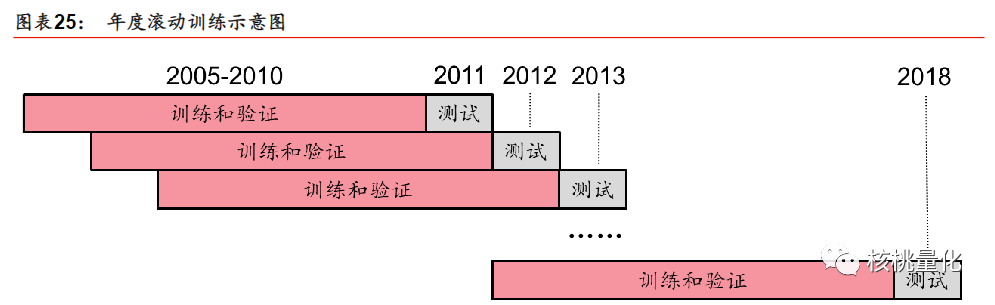
-
样本内训练:使用逻辑回归和XGBoost基学习器对训练集进行训练。 -
交叉验证调参:对所有超参数组合进行网格搜索,选择验证集平均AUC最高的一组超参数作为最终模型的超参数。不同的交叉验证方法可能得到不同的最优超参数。 -
样本外测试:使用确定的最优超参数,以T月末截面期处理后的特征作为模型输入,得到每个样本的预测值f(x)。将预测值视为合成后的因子,进行单因子分层回测,使用之前的单因子测试报告中的回测方法。 -
模型评价:使用分层回测的结果作为模型筛选标准。提供测试集的正确率、AUC等指标来衡量模型的性能。
4.2 实验结果
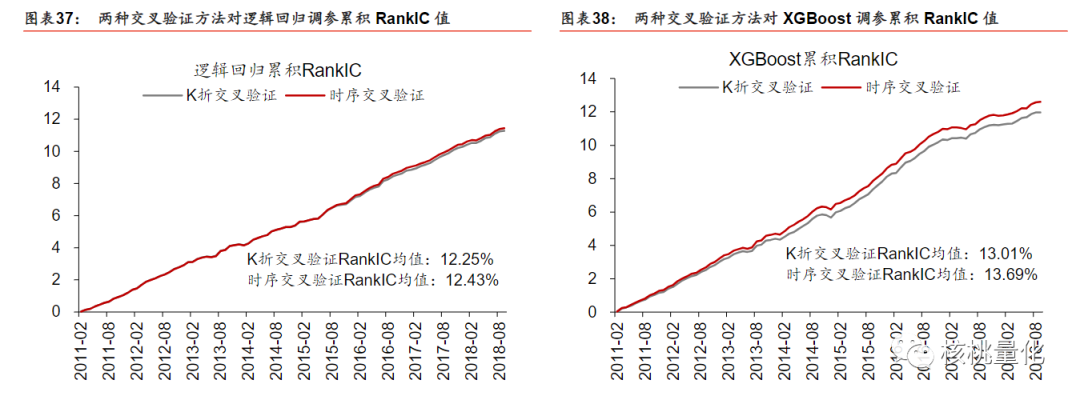
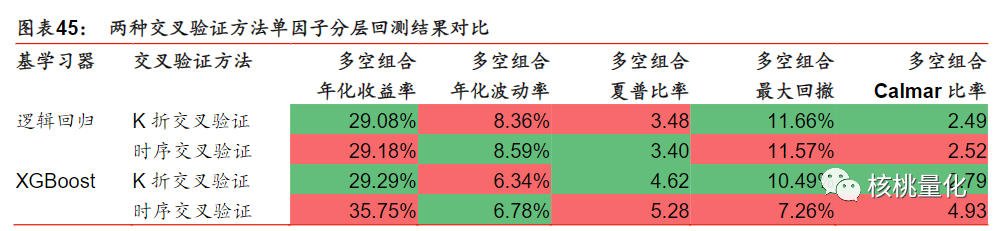
从下面的实验部分分析可知,时序交叉验证方法在全A选股中的应用相比传统K折交叉验证表现出明显优势。由于因子数据具有较强的序列相关性,传统交叉验证方法的样本独立同分布假设不成立。时序交叉验证选择了更简单的模型,具有较小的正则化项和较低的树深度和行采样比例,以降低过拟合风险。在模型性能方面,时序交叉验证表现更好,具有较高的测试集正确率、AUC和RankIC值,而样本内正确率较低,表明其过拟合程度较低。在合成单因子分层回测和构建策略组合回测方面,对于简单的逻辑回归模型,时序交叉验证与K折交叉验证表现接近;而对于复杂的XGBoost模型,时序交叉验证具备明显优势。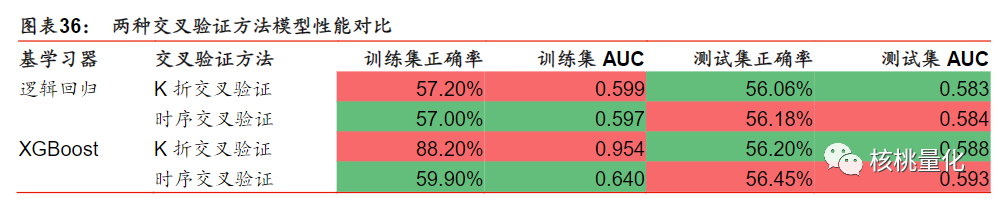
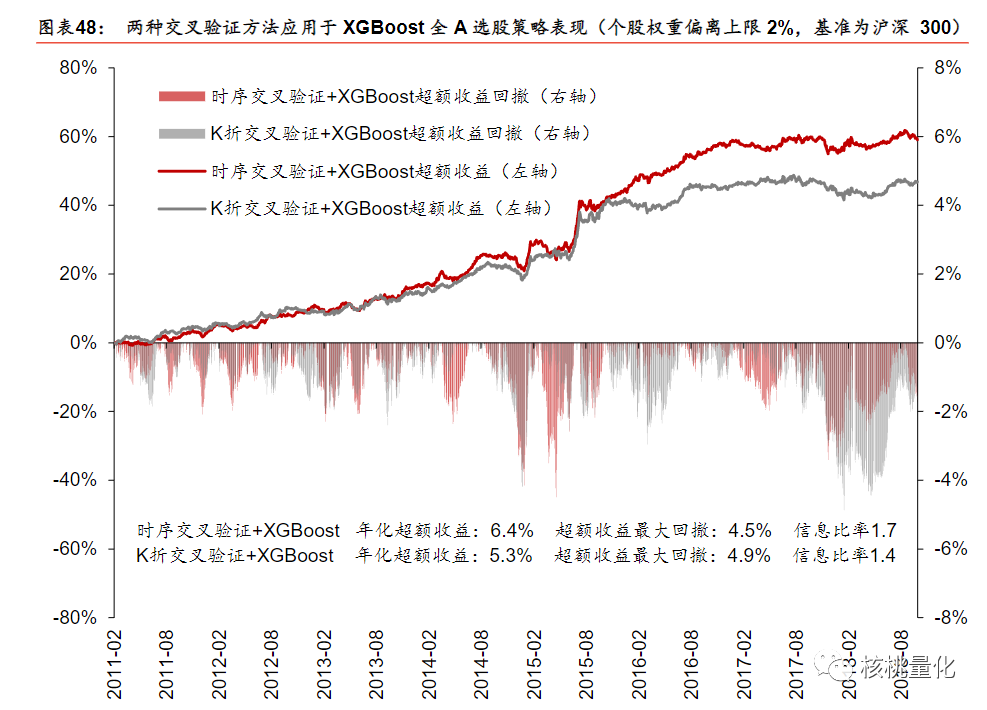
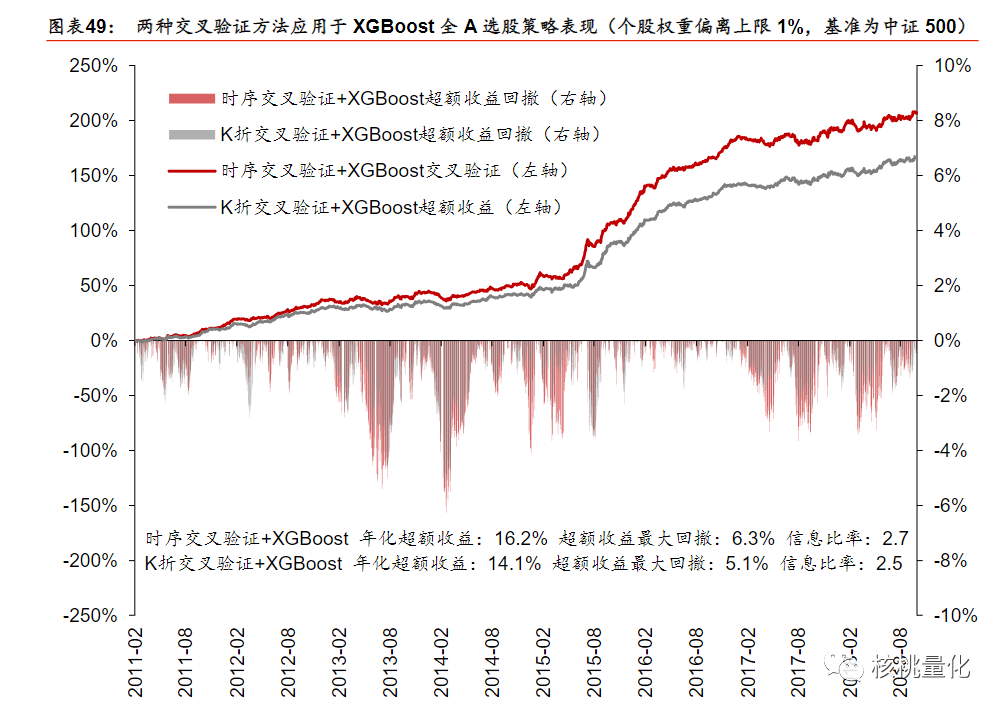
五. 总结展望
金融市场的复杂性要求我们重新审视和改进机器学习方法的应用。时序交叉验证在金融市场中的应用显示出明显的优势,能够提供更好的模型性能和回测结果。展望未来,我们需要进一步研究和发展适用于金融市场的机器学习方法,以更好地应对其复杂性,并为投资决策提供更可靠的工具和指导。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111024
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!



![[通达信指标]波段抄底买卖主图公式](https://95sca.cn/2024/08/07/5cDqGzYLzcaKvmA1722997733.390958.jpg?imageMogr2/thumbnail/!480x300r|imageMogr2/gravity/center/crop/480x300)

