
一 本文概要
传统的日内交易策略主要依赖于价格特征来构建状态空间,但忽视了策略位置的上下文信息,而这一点在日内交易中至关重要。本文提出了一种新颖的深度强化学习(DRL)模型,通过将位置特征纳入稀疏状态空间来封装上下文信息。模型在长达近十年的时间内和多种资产(包括商品和外汇证券)上进行了评估,并考虑了交易成本。结果表明,本文模型在盈利能力和风险调整指标方面表现显著。特征重要性结果显示,每个包含上下文信息的特征对模型的整体性能均有贡献。此外,通过对代理的日内交易活动的探索,揭示了支持本文模型有效性的模式。
二 背景知识
日内交易
日内交易是一种短期投机性交易策略,交易者在一个交易日内完成所有买卖操作,不持有任何资产过夜,以避免隔夜风险。由于日内交易的高频率和短期性质,交易者主要依赖技术分析工具,如蜡烛图、移动平均线、相对强弱指数(RSI)和布林带等,来识别市场趋势和价格反转点。交易者通常会使用专门的交易软件,实时监控市场动态,并基于特定的技术指标和信号做出快速决策。日内交易的目标是在短时间内通过小幅度价格波动获取利润,因此需要高度的市场敏感性和快速反应能力。交易者往往会使用杠杆来放大收益,但这也增加了风险。成功的日内交易者必须具备良好的市场知识、严格的纪律和强大的心理素质,以应对市场的高波动性和不确定性。
为了提高交易效率和准确性,许多日内交易者会使用算法交易和高频交易技术。这些技术通过复杂的数学模型和计算机程序,自动执行交易操作,捕捉市场中的微小价格差异。尽管日内交易可以带来高回报,但也存在显著的风险,包括市场波动、流动性不足和技术故障等。交易者需要具备良好的风险管理策略,如设置止损点和止盈点,以限制潜在损失。此外,日内交易还需要支付较高的交易成本,如佣金和点差,这些成本可能会侵蚀交易利润。因此,日内交易并不适合所有投资者,尤其是那些缺乏专业知识和经验的人。总体而言,日内交易是一种高风险、高回报的交易策略,适合那些能够承受高风险并且具备快速决策和执行能力的专业交易者。
深度强化学习
深度强化学习(Deep Reinforcement Learning, DRL)是一种结合了深度学习和强化学习的先进机器学习方法,用于解决复杂的决策问题。在强化学习中,智能体(agent)通过与环境(environment)的持续交互来学习最佳策略,目标是最大化累计奖励(cumulative reward)。智能体在每个时间步接收到环境的当前状态(state),基于该状态选择一个动作(action),然后从环境中获得相应的奖励(reward)和下一个状态。这一过程通过试错(trial-and-error)和反馈(feedback)不断优化智能体的策略(policy)。深度学习,通过深度神经网络(DNN)的强大表示能力,可以处理高维和复杂的状态空间,提升了强化学习在实际应用中的表现。深度强化学习在游戏、机器人控制、自动驾驶和金融交易等领域取得了显著成功。例如,AlphaGo通过深度强化学习击败了顶级围棋选手,展示了其在复杂决策问题上的强大能力。
在金融交易中,深度强化学习被用来开发自动化交易策略,帮助交易者在复杂多变的市场环境中做出优化决策。智能体可以通过历史市场数据和实时交易数据,持续学习和调整交易策略,以最大化投资回报。深度强化学习不仅可以处理高维的市场数据,还能够考虑交易成本、风险和市场冲击等多种因素,提供更加精细和动态的交易决策。这种方法的灵活性和适应性,使其在高频交易和日内交易等领域具有广泛应用前景。总体而言,深度强化学习通过结合深度学习的表示能力和强化学习的决策优化能力,为解决复杂决策问题提供了强大的工具,正在不断拓展其应用边界。
三 本文方法
3.1 问题定义
每个资产都有一个限价订单簿(LOB),它包括了所有买卖信息。限价订单由以下几部分组成:买卖方向(买/卖)、数量、限价和提交时间。市场订单会匹配限价订单簿中的订单来执行交易,从而形成价格。为了简化市场动态,LOB通常会被采样并汇总成OHLCV(开盘价、最高价、最低价、收盘价、交易量)数据。本研究中,我们使用每分钟的时间间隔来代表日内交易的粒度。
3.2 状态空间构建
传统的日内交易策略主要依赖于价格特征,如原始价格、收益和技术指标。然而,这些特征往往忽略了交易策略相对于特定时间点的位置上下文信息。为此,本文提出了位置特征,这些特征可以捕捉策略在历史和未来上下文中的位置。
价格特征
价格特征包括原始价格、回报率和技术指标等。这些特征从市场数据中提取,提供了资产价格的历史和当前状态信息。具体来说,本文使用了以下几种价格特征:
-
原始价格:包括开盘价、收盘价、最高价和最低价。 -
回报率:包括日内回报率和历史回报率。 -
技术指标:如移动平均线(MA)、相对强弱指数(RSI)、布林带(Bollinger Bands)等。
位置特征
位置特征封装了策略相对于交易日的上下文信息,主要包括:
-
交易日剩余时间:当前时间距离交易日结束的时间。 -
每日交易阶段:将交易日划分为若干阶段,如开盘阶段、午盘阶段和收盘阶段。 -
历史交易行为:包括过去几个时间步内的交易行为(买入、卖出、持有)。
通过结合价格特征和位置特征,本文构建了一个更全面的状态空间,为DRL模型提供更丰富的信息输入。
3.3 模型训练
本文提出的DRL模型包括以下几个部分:
-
输入层:输入包括价格数据和位置特征。 -
特征提取层:使用卷积神经网络(CNN)或长短期记忆网络(LSTM)来提取特征。 -
决策层:使用DQN或A3C模型来做出交易决策。
训练过程中,模型在模拟环境中与市场进行交互,不断调整其策略以最大化累积奖励。奖励函数考虑了利润、风险和交易成本。使用回测数据评估模型性能,并根据结果调整模型参数。

四 实验分析
4.1 实验设置
本文的实验在一个包含多种资产的数据集上进行,数据集涵盖了近十年的市场数据。实验设置包括以下几个步骤:
-
数据预处理:对原始市场数据进行清洗和标准化处理,生成价格特征和位置特征。 -
模型训练:使用预处理后的数据训练DQN和A3C模型,采用经验回放和目标网络等技术来提高训练效果。 -
性能评估:通过回测实验评估模型的性能,使用累计收益、夏普比率和最大回撤等指标进行比较分析。
4.2 实验分析
本文提出的模型在一段接近十年的时间内以及多种资产(包括商品和外汇证券)上进行了评估,并考虑了交易成本。实验结果显示,该模型在盈利能力和风险调整指标方面表现出显著的性能。以下是实验结果的具体总结:
收益表现:
模型在不同市场条件下均表现出较高的盈利能力。
通过比较基准模型,本文提出的模型在绝大多数情况下都实现了更高的累计回报。
风险调整指标:
使用夏普比率等风险调整指标评估模型性能,结果显示该模型在平衡风险和回报方面具有优势。
模型能够有效地控制回撤,展示了良好的风险管理能力。
特征重要性:
通过特征重要性分析,发现每个包含上下文信息的特征都对模型的整体性能有贡献。
这些特征帮助模型更好地理解市场动态,从而做出更优的交易决策。
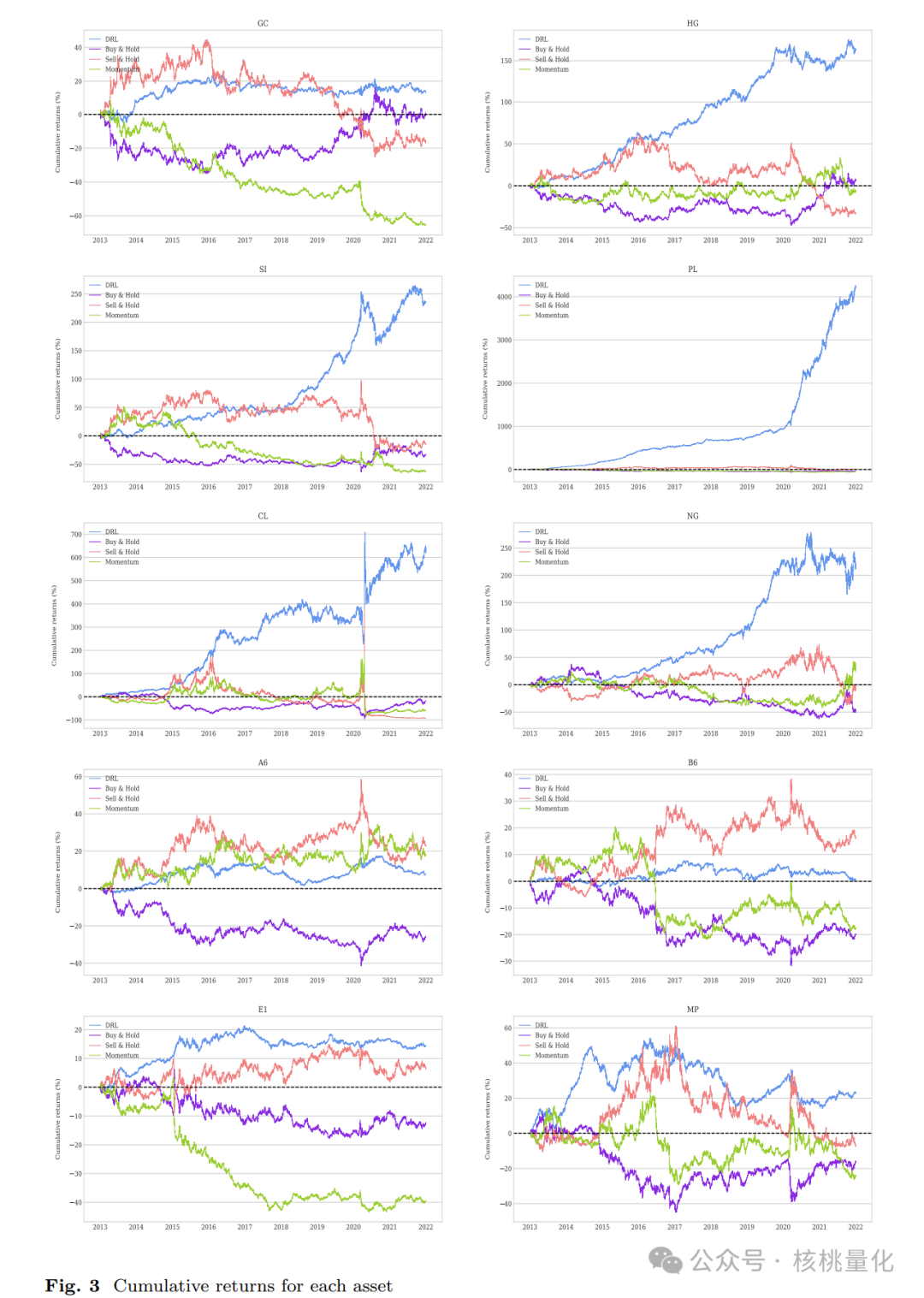
交易活动分析:
对模型的日内交易活动进行分析,揭示出模型在特定时间间隔内的交易模式。
通过这些模式,可以证明本文提出的模型在不同的市场环境下都能保持有效性。
总体而言,本文提出的深度强化学习模型通过引入位置特征,显著提升了日内交易策略的性能,并展示了在不同资产和长时间段内的鲁棒性和有效性。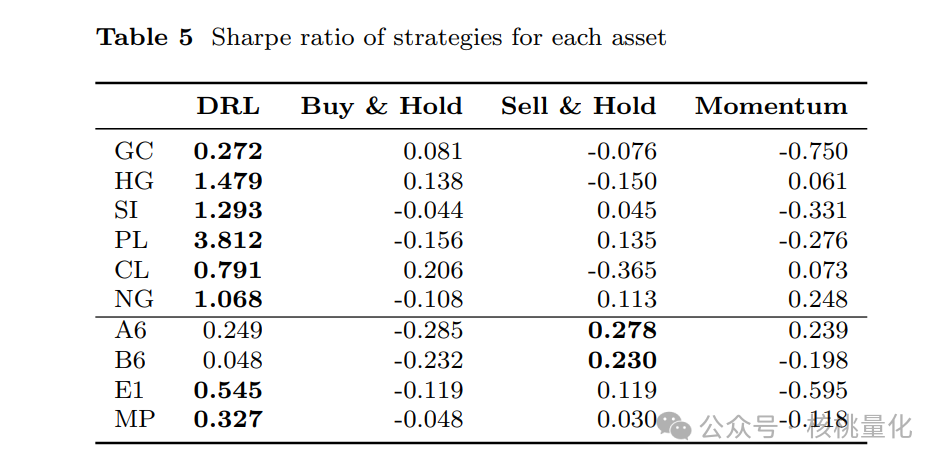


五 总结展望
本文提出了一种新颖的深度强化学习(DRL)模型,通过引入位置特征来增强日内交易策略的性能。通过结合价格特征和位置特征,本文模型能够更全面地捕捉市场信息,从而优化交易决策。实验结果表明,本文模型在盈利能力、风险调整收益和风险管理方面均表现出色,显著优于传统基于价格特征的模型。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111072
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!